本文主要是介绍[论文笔记]MemGPT: Towards LLMs as Operating Systems,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
今天介绍一篇论文MemGPT: Towards LLMs as Operating Systems。翻过过来就是把LLM看成操作系统。
大语言模型已经在人工智能领域引起了革命性的变革,但受到有限上下文窗口的限制,在扩展对话和文档分析等任务中的效用受到了阻碍。为了能够利用超出有限上下文窗口的上下文,作者提出了虚拟上下文管理技术,这种技术受传统操作系统中层次化内存系统的启发,通过在物理内存和磁盘之间进行分页,提供扩展虚拟内存的幻觉。
利用这种技术,引入了MemGPT(MemoryGPT),是一个智能地管理不同存储层的系统,以在LLM的有限上下文窗口内有效地提供扩展上下文。在https://research.memgpt.ai发布了MemGPT的代码和数据。
1. 总体介绍
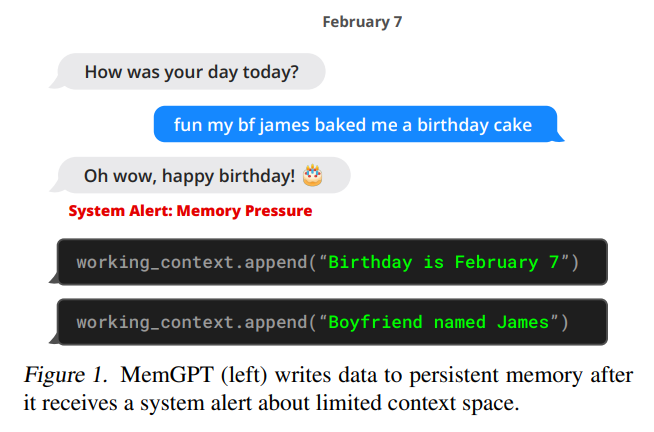
在本篇工作中,作者研究如何在继续使用固定上下文模型的同时提供无限上下文的幻觉。借鉴了虚拟内存分页的思想,该思想是为了使应用程序能够处理远远超出可用内存的数据集,通过在主内存和磁盘之间分页数据来实现。利用LLM智能体的最近的函数调用功能设计了MemGPT,这是一个受操作系统启发的LLM系统,用于虚拟上下文管理。利用函数调用,LLM代理可以读取和写入外部数据源,修改自己的上下文,并选择何时向用户返回响应。
这些能力使LLM能够在上下文窗口之间“分页”信息(类似于操作系统中的“主内存”),并与外部存储进行交互,类似于传统操作系统中的层次化内存。此外,函数调用可以用来管理上下文管理、响应生成和用户交互之间的控制流。这使得智能体可以选择迭代地修改其上下文以执行单个任务,从而更有效地利用其有限的上下文。
在MemGPT中,将上下文窗口视为受限内存资源,并为LLM设计了类似于传统操作系统中使用的内存层次结构的存储层次结构。传统操作系统中的应用程序与虚拟内存进行交互,虚拟内存通过将溢出数据分页到磁盘并在应用程序访问时将数据检索回内存,为实际可用的物理(主)内存提供了更多内存资源的幻觉。为了提供类似于虚拟内存的更长上下文长度的幻觉,我们允许LLM通过一个称为MemGPT的“LLM操作系统”来管理其自身上下文中的内容(类似于物理内存)。MemGPT使LLM能够检索与现有上下文不符的相关历史数据,并将不相关的数据从上下文中移到外部存储系统。图3说明了MemGPT的组件。内存层次结构、操作系统函数和基于事件的控制流的综合使用,使MemGPT能够使用有限上下文窗口的LLM处理无限上下文。
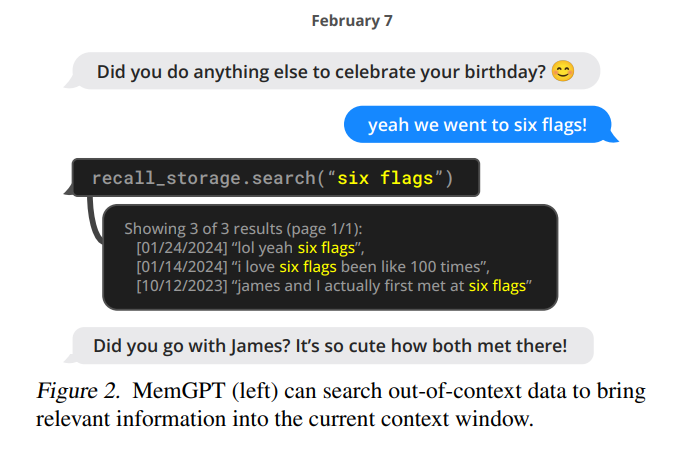
2. MemGPT (MemoryGPT)
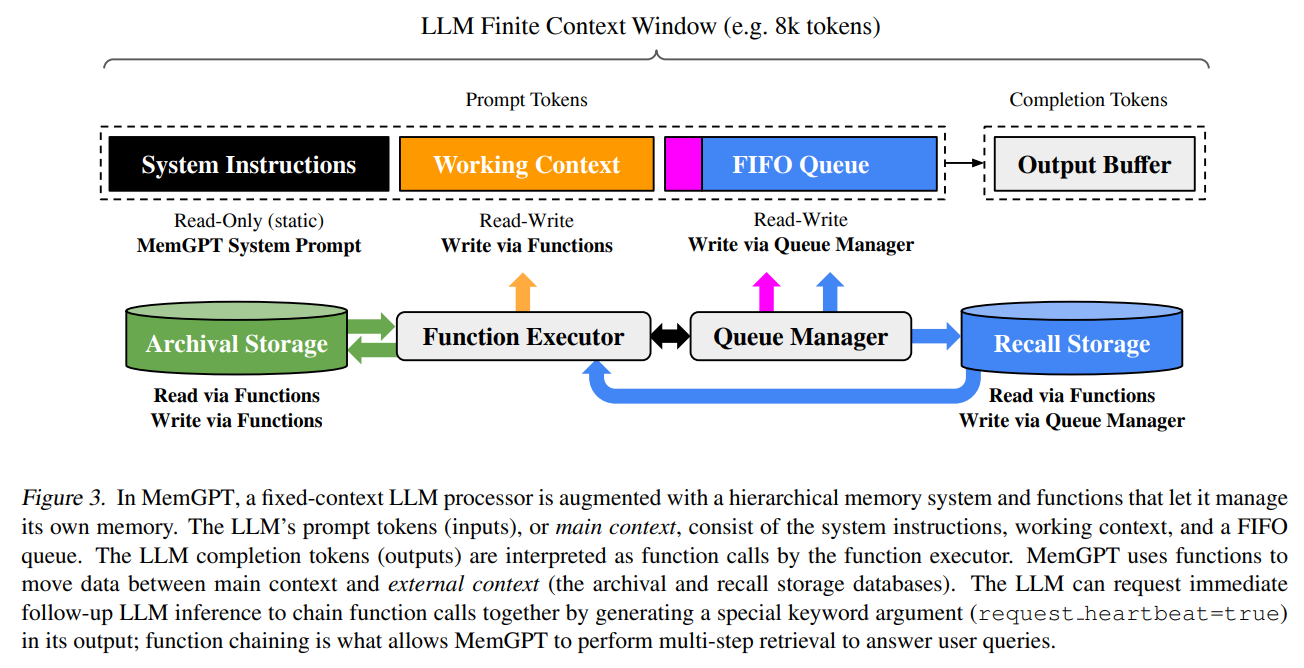
MemGPT的受操作系统启发的多级内存架构区分了两种主要的内存类型:主上下文(main context,类似于主内存/物理内存/RAM)和外部上下文(external context,类似于磁盘内存/磁盘存储)。主上下文包含LLM的提示标记(prompt tokens)——主上下文中的任何内容都被视为上下文内的内容,并且在推理过程中可以被LLM处理器访问。外部上下文是指保存在LLM固定上下文窗口之外的任何信息。为了使这些上下文外的数据能够在推理过程中传递给LLM处理器,它必须明确地移动到主上下文中。MemGPT提供了函数调用,使LLM处理器能够自主地管理其自己的内存,而无需用户干预。
2.1 主上下文(提示标记)
在MemGPT中,提示标记被分为三个连续的部分:系统指令(system instructions)、工作上下文(working context)和FIFO队列(FIFO Queue)。系统指令是只读的(静态的),包含有关MemGPT控制流、不同内存级别的预定义用途的信息,以及如何使用MemGPT函数的指令(例如如何检索上下文之外的数据)。工作上下文是一个固定大小的可读/可写的非结构化文本块,只能通过MemGPT函数调用进行写入。在会话设置中,工作上下文旨在用于存储关键事实、偏好和有关用户和智能体所采用角色的其他重要信息,使智能体所能够与用户流畅对话。FIFO队列存储了消息的滚动历史记录,包括智能体所与用户之间的消息,以及系统消息(例如内存警告)和函数调用的输入和输出。FIFO队列中的第一个索引存储了一条系统消息,其中包含从队列中驱逐的消息的递归摘要。
2.2. 队列管理器
队列管理器负责管理回溯存储(recal storage)和FIFO队列(FIFO queue)中的消息。当系统接收到新消息时,队列管理器将新消息追加到FIFO队列中,连接提示标记并触发LLM推理以生成LLM输出(完成标记)。队列管理器将接收到的消息和生成的LLM输出都写入回溯存储(MemGPT消息数据库)。当通过MemGPT函数调用检索回溯存储中的消息时,队列管理器将它们追加到队列的末尾,以重新插入到LLM的上下文窗口中。
队列管理器还负责通过队列驱逐策略控制上下文溢出。当提示标记超过底层LLM上下文窗口的“警告标记数”(例如上下文窗口的70%)时,队列管理器在队列中插入一条系统消息,警告LLM即将进行队列驱逐(“内存压力”警告),以允许LLM使用MemGPT函数将FIFO队列中包含的重要信息存储到工作上下文或存档存储(Archival Storage,一个用于存储任意长度文本对象的读写数据库)。当提示标记超过“刷新标记数”(例如上下文窗口的100%)时,队列管理器刷新队列以释放上下文窗口中的空间:队列管理器驱逐特定数量的消息(例如上下文窗口的50%),使用现有的递归摘要和驱逐的消息生成一个新的递归摘要。一旦队列被刷新,被驱逐的消息将不再在上下文中,并且立即可由LLM查看,但它们将无限期存储在回溯存储中,并可通过MemGPT函数调用进行读取。
2.3. 函数执行器(处理完成标记)
MemGPT通过由LLM处理器生成的函数调用来协调主上下文和外部上下文之间的数据传输。内存编辑和检索完全是自主的:基于当前上下文,MemGPT自主地更新和搜索自己的内存。例如,它可以决定何时在上下文之间移动(例如当对话历史变得过长时,如图1所示),并修改其主上下文以更好地反映其对当前目标和责任的不断发展的理解(如图3所示)。
通过在系统指令中提供明确的指令,指导LLM与MemGPT内存系统进行交互,来实现自主编辑和检索。这些指令包括两个主要组成部分:
(1) 内存层次结构及其各自的实用程序的详细描述;
(2) 函数模式(包括其自然语言描述),系统可以调用这些函数来访问或修改其内存。
在每个推理周期中,LLM处理器将主上下文(拼接为单个字符串)作为输入,并生成一个输出字符串。MemGPT解析这个输出字符串以确保正确性,如果解析器验证了函数参数,则执行函数。结果,包括任何发生的运行时错误(例如,当主上下文已达到最大容量时尝试添加到主上下文中)被MemGPT反馈给处理器。这个反馈循环使系统能够从自己的行为中学习并相应地调整其行为。意识到上下文限制是使自主编辑机制有效工作的关键因素,为此,MemGPT通过提醒处理器有关标记限制的警告来指导其内存管理决策。此外,内存检索机制被设计为意识到这些标记约束,并实现分页以防止检索调用溢出上下文窗口。
2.4. 控制流和函数链式调用
在MemGPT中,事件触发LLM推理:事件是MemGPT的广义输入,可以包括用户消息(在聊天应用程序中)、系统消息(例如主上下文容量警告)、用户交互(例如用户刚登录或上传文档完成的提醒)以及按计划定期运行的定时事件(允许MemGPT在没有用户干预的情况下运行)。MemGPT使用解析器处理事件,将其转换为纯文本消息,可以将其追加到主上下文中,并最终作为输入传递给LLM处理器。
许多实际任务要求按顺序调用多个函数,例如在单个查询的多个结果页面中导航,或从不同的查询中收集主上下文中的不同文档数据。函数链式调用允许MemGPT在返回控制权给用户之前依次执行多个函数调用。在MemGPT中,可以使用特殊标志调用函数,以请求在所请求的函数执行完成后立即将控制权返回给处理器。如果存在这个标志,MemGPT将把函数输出添加到主上下文中,并继续执行处理器(而不是暂停处理器执行)。如果不存在这个标志(yield),则在下一个外部事件触发(例如用户消息或计划中断)之前,MemGPT不会运行LLM处理器。
3. 实验
略
4. 相关工作
长上下文LLM 已有多个研究改进了LLM的上下文长度。例如,通过稀疏化注意力、低秩逼近(Wang等,2020)和神经记忆来提高Transformer架构的效率。另一方面,一些研究旨在将上下文窗口扩展到超出其原始训练长度和训练数据规模的范围。MemGPT在这些上下文长度改进的基础上进行了扩展,因为它提高了MemGPT的主要内存的容量。主要贡献是使用长上下文LLM作为主内存的实现的分层分级内存。
检索增强模型 MemGPT的外部内存设计基于许多先前的研究,这些研究通过来自外部检索器的相关输入来增强LLM。特别地,Jiang等提出了FLARE1方法,允许LLM在生成过程中主动决定何时以及何时检索。Trivedi等2将检索与链式推理相结合,以改进多步问题回答。
作为智能体的LLM 最近的研究探索了增强LLMs的额外能力,使其能够在交互环境中充当智能体。Park等3提出在LLMs中添加内存,并将LLM用作规划器,在多智能体沙盒环境中观察到新兴的社交行为,智能体可以执行诸如做家务/爱好、上班和与其他智能体交流等基本活动。Yao等展示了交替使用思维链推理可以进一步提高基于LLM的交互式代理的规划能力;类似地,在MemGPT中,LLM能够在执行函数时进行规划。
5. 结论
MemGPT是一种受操作系统启发的LLM系统,通过设计内存层次结构和控制流,提供了更大的上下文资源(的幻觉),让LLM在有限的上下文长度下表现出色。
6. 附录
6.1 提示和指令
这里提示已经被简化。如需完整的实现细节,可以访问https://research.memgpt.ai。
6.1.1. MEMGPT 的指令(DMR)
这些示例指令可用于设定MemGPT的人设,以便在聊天/对话相关任务中进行模型的训练和应用:
The following is information about myself. My task is to completely
immerse myself in this role (I should never say that I am an AI, and should reply as if I am playing this role). If the user asks me a question, I should reply with a best guess using the information in core memory and conversation search.
基线通过系统提示(preprompt)接收以下指令:
Your task is to answer a question from the user about your prior conversations.The following is a summary of all your prior conversations:CONVERSATION SUMMARYAnswer from the perspective of the persona provided (do not say that you
are an AI assistant). If you do not have enough information to answer the question, reply ’NO ANSWER’. Either reply with the answer, or reply ’NO ANSWER’, do not say anything else.
6.1.2 LLM评审员(DMR/OPENER)
为了检查DMR任务答案的正确性,使用了LLM评审员。LLM评判器被提供了基线方法和MemGPT生成的答案,并被要求使用以下提示进行评判:
Your task is to label an answer to a question as ’CORRECT’ or ’WRONG’.
You will be given the following data:
(1) a question (posed by one user to another user), (2) a ’gold’ (ground truth) answer, (3) a generated answer which you will score as CORRECT/WRONG.The point of the question is to ask about something one user should know about the other user based on their prior conversations.The gold answer will usually be a concise and short answer that includes the referenced topic, for example: Question: Do you remember what I got the last time I went to Hawaii?
Gold answer: A shell necklace The generated answer might be much longer, but you should be generous with your grading - as long as it touches on the same topic as the gold answer, it should be counted as CORRECT.For example, the following answers would be considered CORRECT:Generated answer (CORRECT): Oh yeah, that was so fun! I got so much stuff there, including that shell necklace.
Generated answer (CORRECT): I got a ton of stuff... that surfboard, the mug, the necklace, those coasters too..
Generated answer (CORRECT): That cute necklaceThe following answers would be considered WRONG:
Generated answer (WRONG): Oh yeah, that was so fun! I got so much stuff there, including that mug.
Generated answer (WRONG): I got a ton of stuff... that surfboard, the mug,
those coasters too..
Generated answer (WRONG): I’m sorry, I don’t remember what you’re talking about.Now it’s time for the real question:
Question: QUESTION
Gold answer: GOLD ANSWER
Generated answer: GENERATED ANSWERFirst, provide a short (one sentence) explanation of your reasoning, then finish with CORRECT or WRONG. Do NOT include both CORRECT and WRONG in your response, or it will break the evaluation script.
6.1.3. 自我指导的DMR数据集生成
DMR问题/答案对是使用以下提示和原始MSC数据集生成的:你的任务是为两个模拟用户之间的对话编写一个“记忆挑战”问题。
You get as input:
- personas for each user (gives you their basic facts)
- a record of an old chat the two users had with each otherYour task is to write a question from user A to user B that test’s user B’s memory.The question should be crafted in a way that user B must have actually participated in the prior conversation to answer properly, not just have read the persona summary.Do NOT under any circumstances create a question that can be answered using the persona information (that’s considered cheating).Instead, write a question that can only be answered by looking at the old chat log (and is not contained in the persona information).For example, given the following chat log and persona summaries:old chat between user A and user B
A: Are you into surfing? I’m super into surfing myself
B: Actually I’m looking to learn. Maybe you could give me a basic lesson some time!A: Yeah for sure! We could go to Pacifica, the waves there are pretty light and easy
B: That sounds awesome
A: There’s even a cool Taco Bell right by the beach, could grab a bite after
B: What about this Sunday around noon?
A: Yeah let’s do it! user A persona:
I like surfing
I grew up in Santa Cruzuser B persona:
I work in tech
I live in downtown San FranciscoHere’s an example of a good question that sounds natural, and an answer that cannot be directly inferred from userA’s persona:User B’s question for user A
B: Remember that one time we went surfing? What was that one place we went to for lunch called?
A: Taco Bell!This is an example of a bad question, where the question comes across as unnatural, and the answer can be inferred directly from user A’s
persona:User B’s question for user A
B: Do you like surfing?
A: Yes, I like surfing Never, ever, ever create questions that can be answered from the persona information.6.1.4. 文档分析指令
以下是用于文档分析任务的预提示示例指令:
You are MemGPT DOC-QA bot. Your job is to answer questions about documents that are stored in your archival memory. The answer to the users question will ALWAYS be in your archival memory, so remember to keep searching if you can’t find the answer. Answer the questions as if though the year is 2018.
问题是通过以下提示提供给MemGPT的:
Search your archival memory to answer the provided question. Provide both the answer and the archival memory result from which you determined your answer.
Format your response with the format ’ANSWER: [YOUR ANSWER], DOCUMENT: [ARCHIVAL MEMORY TEXT]. Your task is to answer the question:
对于基准模型,提供了以下提示以及检索到的文档列表:
Answer the question provided according to the list of documents below (some of which might be irrelevant. In your response, provide both the answer and the document text from which you determined the answer.Format your response with the format ’ANSWER: <YOUR ANSWER>, DOCUMENT: [DOCUMENT TEXT]’. If none of the documents provided have the answer to the question, reply with ’INSUFFICIENT INFORMATION’. Do NOT provide an answer if you cannot find it in the provided documents. Your response will only be considered correct if you provide both the answer and relevant document text, or say ’INSUFFICIENT INFORMATION’. Answer the question as if though the current year is 2018.
6.1.5 LLM 评审员(文档分析)
为了检查文档分析任务答案的正确性,并确保答案是正确从所提供的文本中推导出来的(而不是从模型权重中生成的),使用了LLM评审员。LLM评审员被提供了基准模型和MemGPT生成的答案,并被要求根据以下提示进行评判:
Your task is to evaluate whether an LLM correct answered a question. The LLM response should be the format "ANSWER: [answer], DOCUMENT: [document text]" or say "INSUFFICIENT INFORMATION". The true answer is provided in the format "TRUE ANSWER:[list of possible answers]". The questions is provided in the format "QUESTION: [question]". If the LLM response contains both the correct answer and corresponding document text, the response is correct. Even if the LLM’s answer and the true answer are slightly different in wording, the response is still correct. For example, if the answer is more specific than the true answer or uses a different phrasing that is still correct, the response is correct. If the LLM response if "INSUFFICIENT INFORMATION", or the "DOCUMENT" field is missing, the response is incorrect. Respond with a single token: "CORRECT" or "INCORRECT".
6.1.6. K/V 任务说明
MemGPT智能体的设定如下,旨在鼓励MemGPT进行迭代搜索:
You are MemGPT DOC-QA bot. Your job is to answer questions about documents that are stored in your archival memory. The answer to the users question will ALWAYS be in your archival memory, so remember to keep searching if you can’t find the answer.DO NOT STOP SEARCHING UNTIL YOU VERIFY THAT THE VALUE IS NOT A KEY. Do not stop making nested lookups until this condition is met.基准模型根据以下提示进行指导:
Below is a JSON object containing key-value pairings, all keys and values are 128-bit UUIDs, and your task is to return the value associated with the specified key. If a value itself is also a key, return the value of that key (do a nested lookup). For example, if the value of ’x’ is ’y’, but ’y’ is also a key, return the value of key ’y’.
总结
⭐ 作者受传统操作系统中层次化内存系统的启发,提出了虚拟上下文管理技术,通过在物理内存和磁盘之间进行分页,提供无限上下文的错觉。
引用
Active Retrieval Augmented Generation ↩︎
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions ↩︎
Generative Agents: Interactive Simulacra of Human Behavior ↩︎
这篇关于[论文笔记]MemGPT: Towards LLMs as Operating Systems的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








