本文主要是介绍MySQL基础索引知识【索引创建删除 | MyISAM InnoDB引擎原理认识】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
博客主页:花果山~程序猿-CSDN博客
文章分栏:MySQL之旅_花果山~程序猿的博客-CSDN博客
关注我一起学习,一起进步,一起探索编程的无限可能吧!让我们一起努力,一起成长!
目录
一,索引用处
二,磁盘
三,mysql 与磁盘的基本交互单位
四,管理page的数据结构(InnoDB引擎下)
单个page
多个page
B+树 VS B树
聚簇索引 VS 非聚簇索引
辅助索引(普通索引)
MyISAM 引擎
InnoDB引擎
五,索引的操作
主键索引
1.创建
2.删除
普通索引
1.创建
2. 删除
表索引查询
使用索引的原则
结语
嗨!收到一张超美的图,愿你每天都能顺心!

一,索引用处
首先我们需要知道一个结论,合适索引可以大大的提高对数据检索的效率,具体优化比如减少磁盘I/O操作等更细节的优化,待我们在更深层次的了解再谈吧,现在我们只需要知道,索引可以大大提升数据检索的效率,即可。
首先熟悉一下新名词,常见的索引种类有:
- 主键索引(primary key)
- 唯一索引(unique)
- 普通索引(index)
- 全文索引(fulltext)--解决中子文索引问题
二,磁盘
我们知道mysql是对数据进行管理,存储的上层应用,一旦涉及存储就一定会涉及磁盘这个外设(企业服务器用的基本是机械硬盘,谁叫他便宜),而磁盘属于一种机械设备,效率不能与电子元件相比,加上I/O的特性,那如何提升mysql的检索效率?——这得从磁盘讲起
了解磁盘
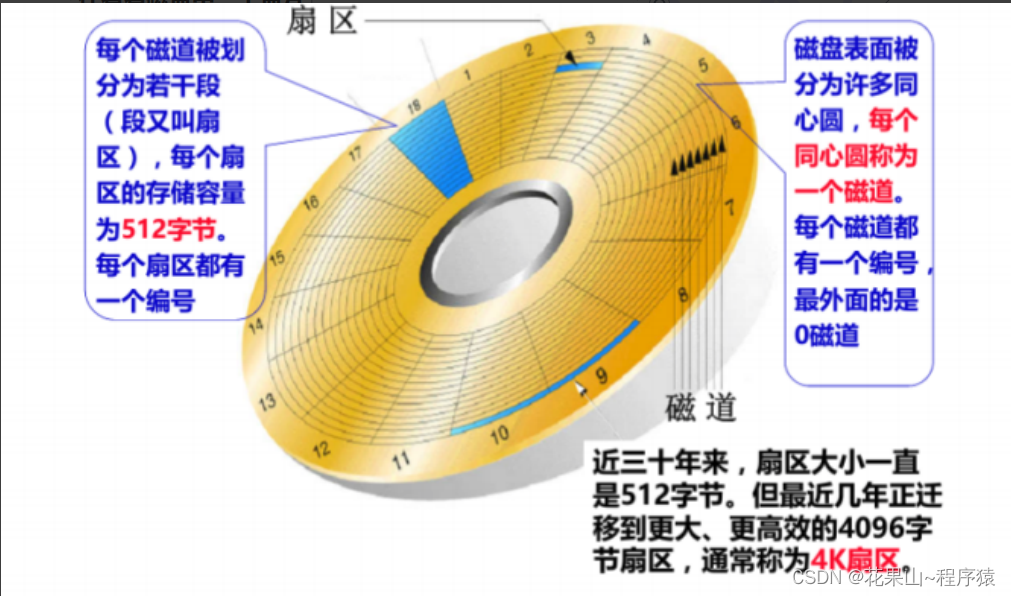
关于磁盘的运行和读取,感兴趣的同学可以去网上了解,这里就不赘述了。
我们知道磁盘扇区大小有512字节,也有4k的,那操作系统进行I/O操作也是以512,4k进行交互的吗? 答:不是
解释:
- 如果操作系统是依据磁盘提供的扇区大小,进行交互的,那扇区大小变化,则操作系统也得变化 。
- 如果一次I/O才512字节,那么I/O次数多,效率自然不高
- 我们学习的文件操作,数据单位是数据块,并不是扇区。
结论:系统与磁盘交互的单位是数据块,具体大小是4K。(局部性原理,预加载后面的数据)
这里补充一下,随机访问与连续访问:
随机访问:本次IO所给出的扇区地址和上次IO给出扇区地址不连续,这样的话磁头在两次IO操作之间需要作比较大的移动动作才能重新开始读/写数据。
连续访问:如果当次IO给出的扇区地址与上次IO结束的扇区地址是连续的,那磁头就能很快的开始这次IO操作,这样的多个IO操作称为连续访问。
结论:随机访问,I/O次数多,效率低;连续访问,I/O次数少,效率高。
三,mysql 与磁盘的基本交互单位
我们清楚mysql是不能直接操作硬件的,这是一种忽略操作系统的逻辑理解。
MySQL 作为一款应用软件,可以想象成一种特殊的文件系统。它有着更高的IO场景,所以,为了提高基本的IO效率, MySQL 进行IO的基本单位是 16KB (后面统一使用 InnoDB 存储引擎讲解)
下面就用一张图进行理解吧。
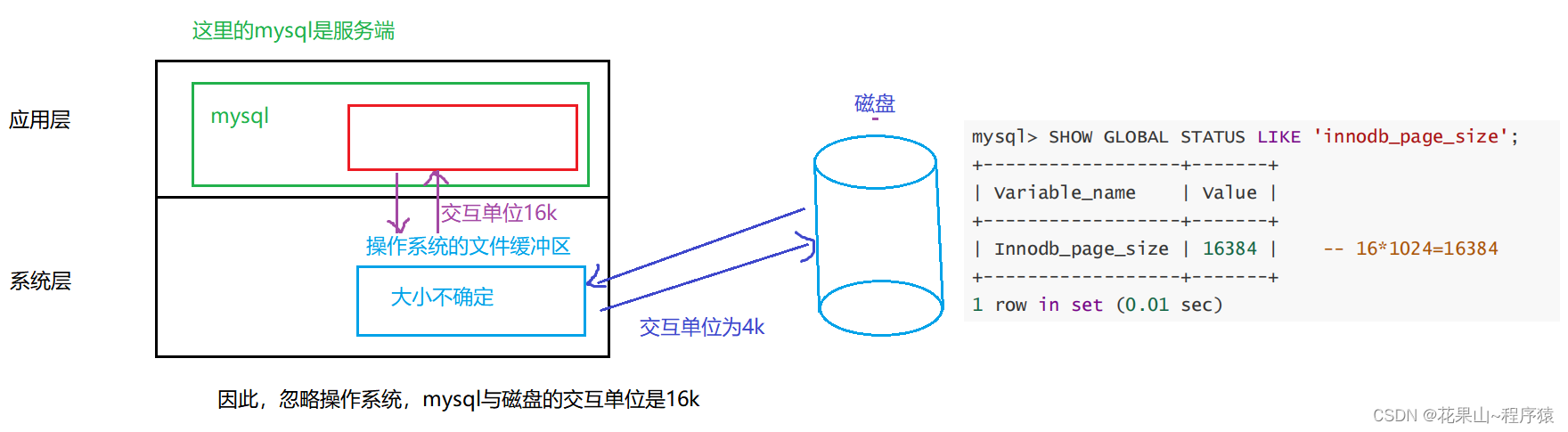
在 Linux 系统中,文件缓冲区大小默认为4KB。但是可以通过修改内核参数来调整这个值,比如将 /proc/sys/vm/page-size 设置为 16384 来将缓冲区大小设置为 16KB(来源AI)
结论:从上面我们可以知道,硬盘与操作系统之间的交互是4k,mysql在InnoDB引擎下与磁盘之间进行16KB的IO交互,而这个交互单位在mysql中被称作 page 。
因此从上面认识中,我们可以有一下理解:
- mysql中的文件,是用page为单位来进行存储的。
- mysql的cord操作,对数据进行修改,首先找到数据page所在的位置,需要持久化时,根据page的位置进行覆盖更新即可。
- 只要是涉及计算的cpu就一定会参与其中,数据也必然存在于内存中,这时这个计算中就会出现两份数据,一份在内存中,一份在磁盘中;需要持久化时,操作系统会根据其刷新策略刷新到磁盘中,也就是一次I/O,单位为page。
- mysql服务端启动时会申请一个内存空间用来进行数据操作,这块空间叫Buffer Tool 大小为128MB,可见为这个缓存条很大。
四,管理page的数据结构(InnoDB引擎下)
上面我们我们提到Buffer Tool是一个很大的内存空间,里面存放着从磁盘获取的数据,也有曾经使用过的污染数据,也有等待持久化的数据。
问题来了?这真的只是一个简单的内存块吗?
——不会是,根据先组织,后管理思想,里面必然有数据结构进行管理——这也是为什么当我们插入没有主键的表时,结果会为我们排序。
为什么mysql交换单位为page,而且是16k? 为什么不是要多少给多少?
答:这种策略叫做局部性原理,计算机读取一部分资源,大概率会读取周边数据,因此直接一次性将那一块数据缓存了。之所以I/O交互慢,I/O次数占大头,大量的随机访问会造成效率低下。
单个page
MySQL 中要管理很多数据表文件,而要管理好这些文件,就需要 先描述,在组织 ,我们目前可以简单理解成一个个独立文件是有一个或者多个Page构成的。
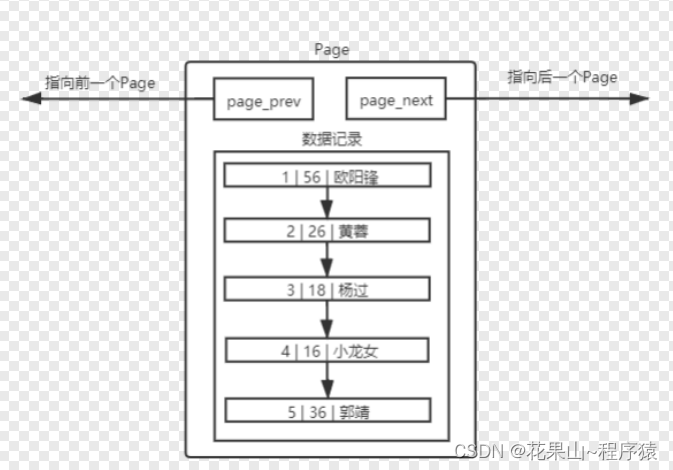
不同的 Page ,在 MySQL 中,都是 16KB ,使用 prev 和 next 构成双向链表。
因为有主键的问题, MySQL 会默认按照主键给我们的数据进行排序,从上面的Page内数据记录可以看出,数据是有序且彼此关联的。
问:为什么插入时,进行排序?
因为,进行排序是为了提高查询效率。
我们知道链表插入与删除效率高(不用移动其他数据,只用修改prev,next指针)但是查询,修改效率低,插入时排序可以让每次查询都是有效数据(比如说查询10,你本可以避免对13的查询)
多个page
在查询某条数据的时候直接将一整页的数据加载到内存中,以减少硬盘IO次数,从而提高性能。但是,本质上是对page逐条查找。当多个page通过链表相连时,线性查找效率低下。
因此page的结构加入了目录,如下:
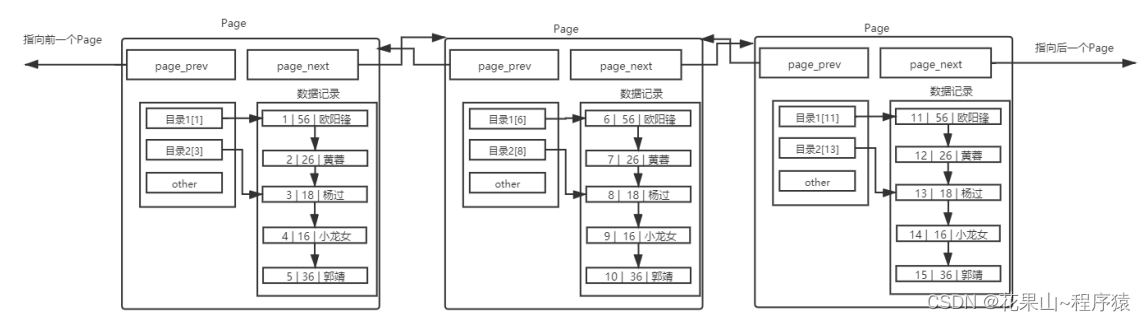
这是一种空间换时间的做法,减少单page存放的数据量,添加目录的数量,这样当查询此页时,只需要查看目录,就能以较少的次数就能查找到数据。
但也有一个问题,上面的方法仍然需要大量的I/O,page依然会被一个一个地加载到内存中!本质上效率提升不了多少,那怎么减少I/O的次数?
将带有数据page的目录给管理起来,如图所示:
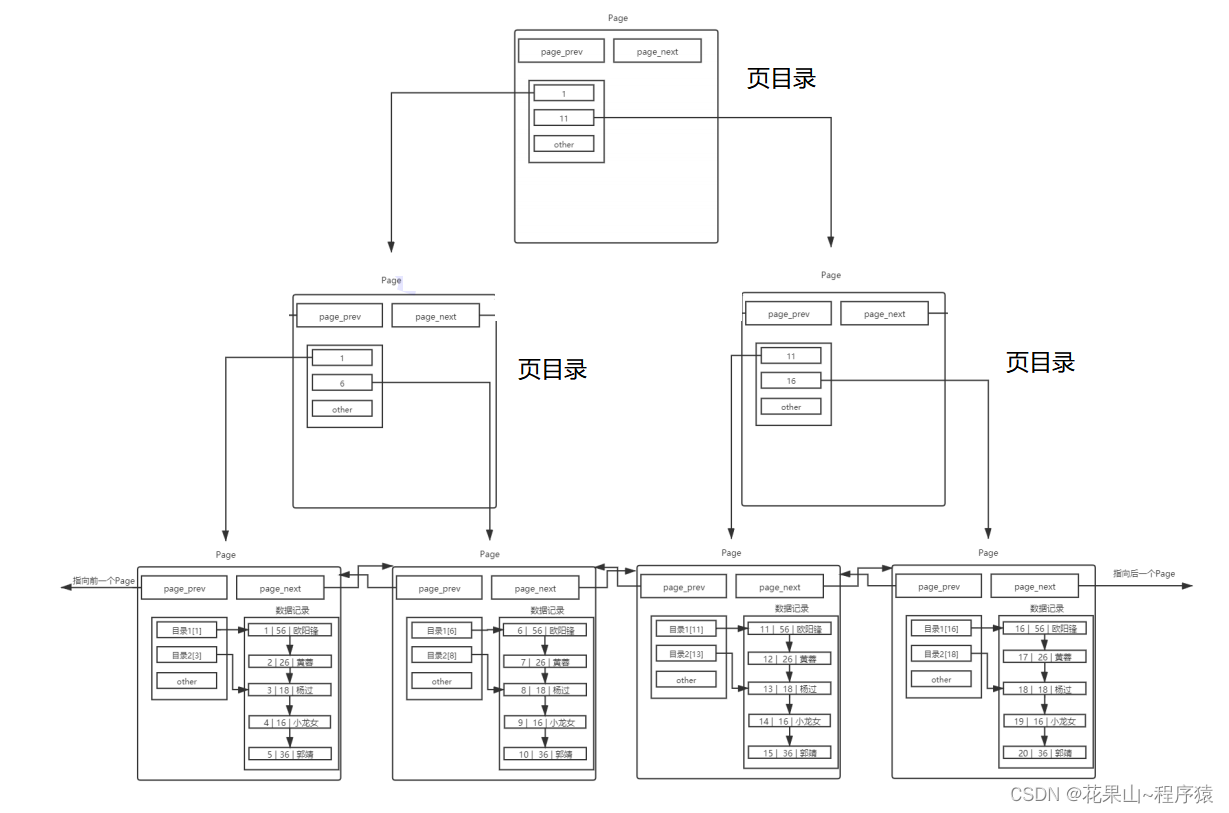
(载有数据的page,通过链表相连;page的目录信息,将被会被外部的页目录管理)
没错这是一颗B+树,数据量越大,减少的I/O次数越明显。
(B+每个节点可以管理大量的目录page,和大量的数据page,每增加一个高度的节点管理的数据将成指数级增长,因此B+树是一个矮胖型的树,矮胖意味着途径的节点少,每次进入一个节点就是一次I/O,因此I/O次数少,而二叉树,avl数/红黑树这类受瘦高结构的树不合适,哈希类结构不支持范围查找)
关于B+树的实现,可以关注我未来的的高阶数据结构,我们来手把手实现。
复盘一下
B+树将Page分为目录页和数据页。目录页只放各个下级Page的最小键值。
查找的时候,自定向下找,只需要加载部分目录页到内存,即可完成算法的整个查找过程,从而大大减少了I/O次数。
下面是各引擎,底层支持的数据结构:

B+树 VS B树
问:为什么使用B+树,而不是使用B树?
首先我们来看看B树
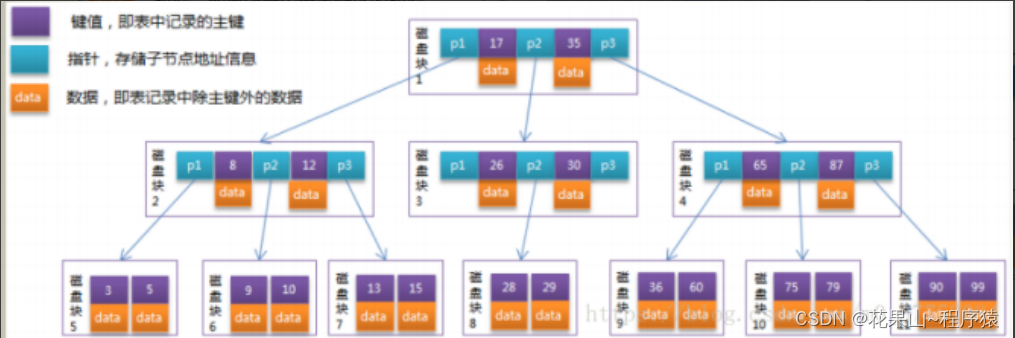
特点:1.每个节点会包含数据;2. 数据之间没有进行连接。
光B树的特点我们就知道,其不适合磁盘I/O:
- 原因1 :相同的目录页,能通过目录管理的数量会变少,变少意味一次着淘汰的数据量少,需要多次淘汰,因此B树的高度会更高,I/O次数更多。
- 原因2:B树数据之间缺少连接,不利于范围查找,变相提高I/O次数。
聚簇索引 VS 非聚簇索引
InnoDB存储索引,本事就是聚簇索引,那什么是非聚簇索引?下面我们了解一下mysql另一个索引——MyISAM
MyISAM 存储引擎-主键索引
MyISAM 引擎同样使用B+树作为索引结果,叶节点的data域存放的是数据记录的地址。下图为 MyISAM 表的主索引, Col1 为主键。
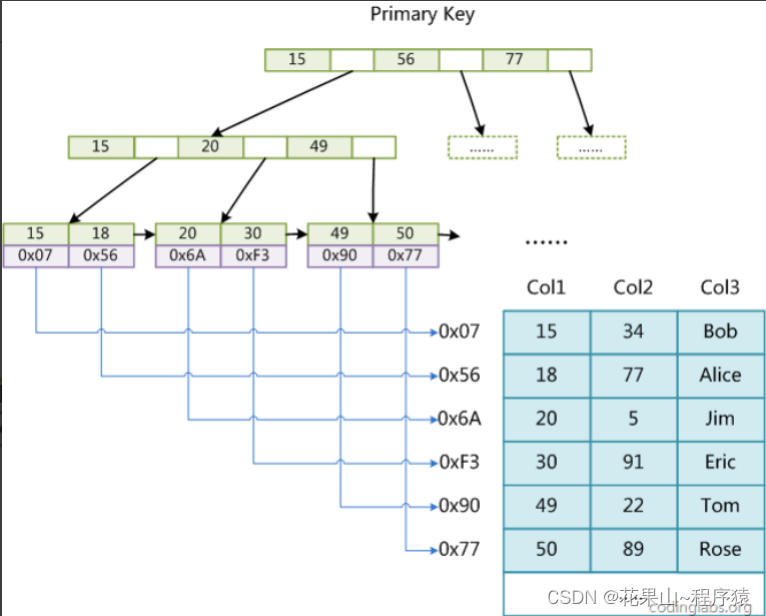
因此,我们可以简单的区分聚簇索引与非聚簇索引,叶子节点的data域存放真实数据的是聚簇,data域存放数据指针的叫做非聚簇。
两种引擎创建文件时的不同:

辅助索引(普通索引)
当然, MySQL 除了默认会建立主键索引外,我们用户也有可能建立按照其他列信息(例如唯一键)建立的索引,一般这种索引可以叫做辅助(普通)索引
对于 MyISAM ,建立辅助(普通)索引和主键索引没有差别,无非就是主键不能重复,而非主键可重复。
MyISAM 引擎
下图就是基于 MyISAM 的 Col2(非主键) 建立的索引,和主键索引没有差别:
InnoDB引擎
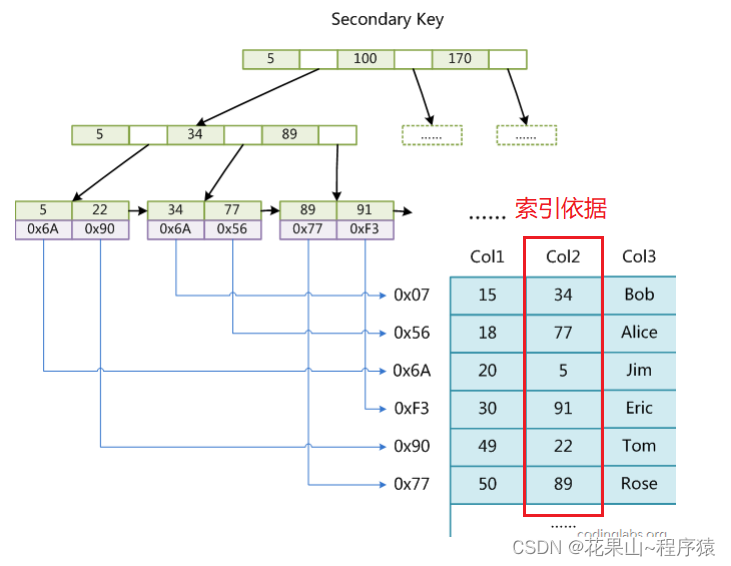
下图是基于InnoDB的Col3建立的索引,但与主键索引有区别,如下:
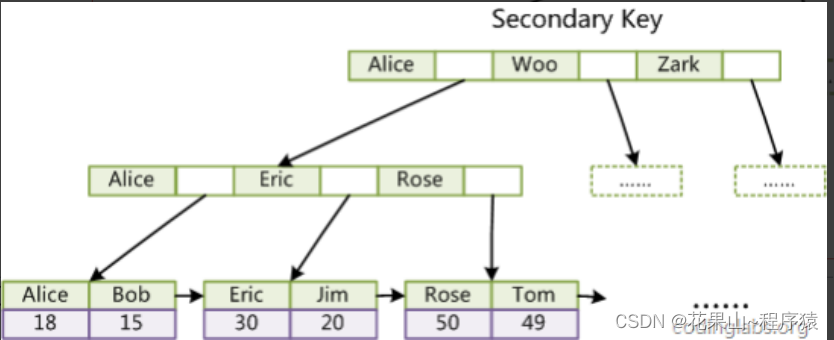
值得我们注意的是InnoDB引擎下,辅助索引结果不存放完整数据,而是只存放主键(key).
所以InnoDB普通索引需要 2次索引:首先,普通索引查找记录找到主键,然后通过主键来找到数据记录。这个过程叫做——回表查询
那为什么InnoDB要这么设计2次索引呢??
答:太浪费空间了。
1.MyISAM的主键索引与普通索引基本上没差别的原因是结果都是数据地址(非聚簇索引),占用的空间比较小。
2.一张表是可以有多张索引,都会储存到文件中,而没有必要多存一份数据,而如果结果都是数据(聚簇索引)将会有大量的储存开销。
五,索引的操作
主键索引
1.创建
第一种:创建表时,添加主键约束,mysql会自动帮我们创建索引
-- 在创建表的时候,直接在字段名后指定 primary key
create table user1(id int primary key, name varchar(30));-- 在创建表的最后,指定某列或某几列为主键索引
create table user2(id int, name varchar(30), primary key(id));第二种:在创建表后,添加主键(当然前提是没有主键)
create table user3(id int, name varchar(30));
-- 创建表以后再添加主键
alter table user3 add primary key(id);2.删除
alter table 表名 drop primary key;
普通索引
1.创建
我们需要知道的是 unique(唯一键)也是普通索引的一员,他的创建也是普通索引的创建,mysql也会为其创建索引结构
第一种:表创建时
create table user8(id int primary key,
name varchar(20) unique, --唯一键
email varchar(30),
index(name) --在表的定义最后,指定某列为索引
);第二中:表创建后 + 索引重命名
create table user9(id int primary key, name varchar(20), email varchar(30));
alter table user9 add index(name); --创建完表以后指定某列为普通索引alter index my_index_name user9(name); --对索引重命名2. 删除
我们知道unique是普通索引中的一员,我们删除unique索引时,也是使用下面普通索引统一的删除法:
alter table 表名 drop index 索引名;
表索引查询
展示这个表中所有的索引信息
show keys from 表名 \G;
show index from 表名 \G;
使用索引的原则
- 经常被频繁调用的,适合作为索引——效率提的高
- 唯一性太差的不适合作为索引
- 更新比较频繁的不适合作为索引——这需要频繁的重新创建索引
- 基本不会作为where条件判断的不适合索引
结语
本小节就到这里了,感谢小伙伴的浏览,如果有什么建议,欢迎在评论区评论,如果给小伙伴带来一些收获,请动动你发财的小手点个免费的赞,你的点赞和关注永远是博主创作的动力源泉。
这篇关于MySQL基础索引知识【索引创建删除 | MyISAM InnoDB引擎原理认识】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




