本文主要是介绍Linux CFS调度器之周期性调度器scheduler_tick函数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、简介
- 二、源码分析
- 2.1 scheduler_tick
- 2.2 task_tick
- 2.3 entity_tick
- 2.4 check_preempt_tick
- 2.5 resched_curr
- 参考资料
前言
Linux内核调度器主要是主调度器和周期性调度器,主调度器请参考:Linux 进程调度之schdule主调度器
一、简介
每当定时器中断发生时,都会调用定时器中断处理程序。每当调用定时器中断处理程序时,处理程序会调用update_process_times函数,将一个时钟滴答分配给当前进程。在其中,会调用scheduler_tick函数。scheduler_tick函数执行和调度相关的一些操作,如检查是否有进程需要调度和切换。
时钟中断是调度器的脉搏,内核依靠周期性的时钟来处理器CPU的控制权。时钟中断处理程序,检查当前进程的执行时间是否超额,如果超额则设置重新调度标志(_TIF_NEED_RESCHED);时钟中断处理函数返回时,被中断的进程如果在用户模式下运行,需要检查是否有重新调度标志,设置了则调用schedule()调度。
周期性调度器scheduler_tick()以固定的频率检测是否有必要进行进程调度和切换。在CFS调度类中,scheduler_tick会检测一个进程执行的时间是否过长,以避免过程的延时,是时候让其他CFS就绪队列中的进程运行.
注意周期性调度器scheduler_tick()设置TIF_NEED_RESCHED标志来对进程进行标记需要被抢占,设置该位则表明需要进行调度切换,没有进行实际的抢占,只是将当前进程标记为应该被抢占。而实际的切换将在抢占执行点来完成。
如果当前进程需要重新调度的条件成立,这里只是会设置TIF_NEED_RESCHED标志,并不会马上调用schedule()来进行调度。真正的调度时机发生在从中断/异常返回时,会判断当前进程有没有被设置TIF_NEED_RESCHED,如果设置则调用schedule()来进行调度。
二、源码分析
流程图如下图左边所示:
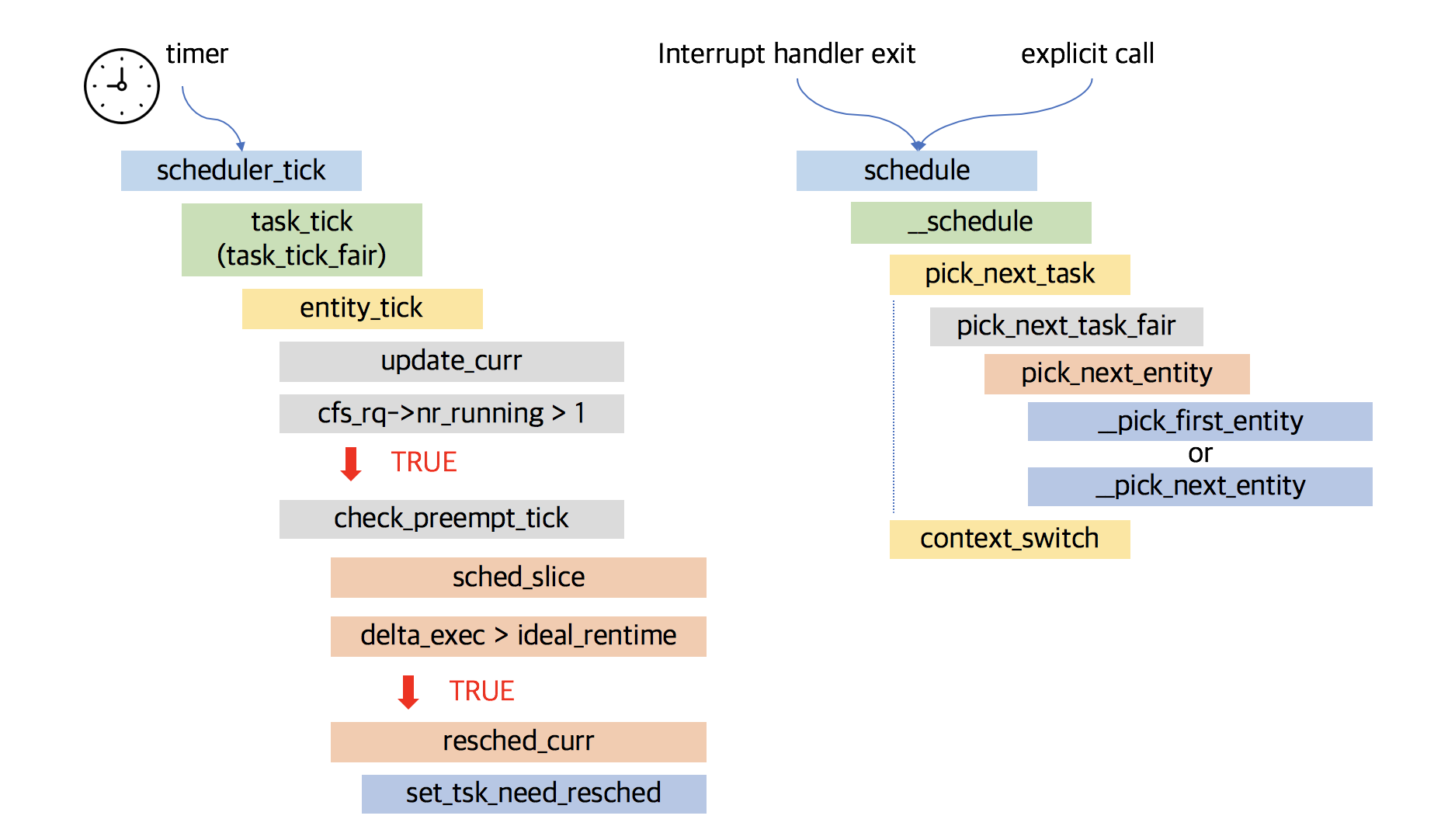
2.1 scheduler_tick
// linux-4.10.1/kernel/sched/core.c/** This function gets called by the timer code, with HZ frequency.* We call it with interrupts disabled.*/
void scheduler_tick(void)
{(1)int cpu = smp_processor_id();struct rq *rq = cpu_rq(cpu);struct task_struct *curr = rq->curr;(2)raw_spin_lock(&rq->lock);update_rq_clock(rq);curr->sched_class->task_tick(rq, curr, 0);cpu_load_update_active(rq);calc_global_load_tick(rq);raw_spin_unlock(&rq->lock);(3)
#ifdef CONFIG_SMPrq->idle_balance = idle_cpu(cpu);trigger_load_balance(rq);
#endif}
这段代码是调度器的定时器中断处理函数,用于处理定时器中断事件。以下是对代码的详细说明:
(1)
首先,获取当前处理器的ID,并根据ID获取对应的运行队列(rq)和当前正在运行的任务(curr)。
(2)
使用原子自旋锁(raw_spin_lock)锁定运行队列,确保原子操作的执行。
调用update_rq_clock()函数,更新运行队列的时钟。
通过curr->sched_class->task_tick()函数调用,调用当前任务所属调度类的task_tick()函数,执行任务级别的时钟滴答处理。
调用cpu_load_update_active()函数,更新运行队列的活跃CPU负载。即就绪队列的cpu_load[]数据。
调用calc_global_load_tick()函数,计算全局负载的时钟滴答。
解锁运行队列,使用raw_spin_unlock。
(3)
如果编译选项中启用了SMP(对称多处理器)支持,会进行一些额外的处理:
将rq->idle_balance设置为idle_cpu(cpu),表示当前运行队列是否处于空闲状态。
调用trigger_load_balance()函数,触发负载平衡操作。
其中主要是:
curr->sched_class->task_tick(rq, curr, 0);
2.2 task_tick
curr->sched_class->task_tick(rq, curr, 0);
// kernel/sched/fair.cconst struct sched_class fair_sched_class = {.task_tick = task_tick_fair,
}
// kernel/sched/fair.c/** scheduler tick hitting a task of our scheduling class:*/
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{struct cfs_rq *cfs_rq;struct sched_entity *se = &curr->se;for_each_sched_entity(se) {cfs_rq = cfs_rq_of(se);entity_tick(cfs_rq, se, queued);}if (static_branch_unlikely(&sched_numa_balancing))task_tick_numa(rq, curr);
}
这段代码是调度器中的公平调度类(fair)的任务时钟滴答处理函数。以下是对代码的详细说明:
(1)首先,定义了一个指向当前任务的调度实体(sched_entity)的指针se,并获取与该实体相关联的CFS运行队列(cfs_rq)。
(2)使用for_each_sched_entity迭代当前任务的调度实体,对每个实体执行以下操作:
获取与该实体相关联的CFS运行队列(cfs_rq)。
调用entity_tick()函数,处理该实体的时钟滴答事件。
其中entity_tick函数最为重要,检查该任务是否需要调度,这里表明需要进行调度切换,没有进行实际的抢占,只是将当前进程标记为应该被抢占。而实际的切换将在抢占执行点来完成。
* 在不支持组调度条件下, 只循环一次
* 在组调度的条件下, 调度实体存在层次关系,
* 更新子调度实体的同时必须更新父调度实体
#ifdef CONFIG_FAIR_GROUP_SCHED
/* Walk up scheduling entities hierarchy */
#define for_each_sched_entity(se) \for (; se; se = se->parent)#else /* !CONFIG_FAIR_GROUP_SCHED */#define for_each_sched_entity(se) \for (; se; se = NULL)
#endif /* CONFIG_FAIR_GROUP_SCHED */
static inline struct task_struct *task_of(struct sched_entity *se)
{return container_of(se, struct task_struct, se);
}#define task_rq(p) cpu_rq(task_cpu(p))static inline struct cfs_rq *cfs_rq_of(struct sched_entity *se)
{struct task_struct *p = task_of(se);struct rq *rq = task_rq(p);return &rq->cfs;
}
(3)如果静态分支(static_branch)sched_numa_balancing为真,表示启用了NUMA(非统一内存访问)平衡功能,则调用task_tick_numa()函数,处理与NUMA平衡相关的任务时钟滴答。
2.3 entity_tick
static void
entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued)
{/** Update run-time statistics of the 'current'.*/(1)update_curr(cfs_rq);/** Ensure that runnable average is periodically updated.*/(2)update_load_avg(curr, UPDATE_TG);......(3)if (cfs_rq->nr_running > 1)check_preempt_tick(cfs_rq, curr);
}
(1)update_curr用来更新当前任务调度实体的 vruntime 值和更新cfs_rq就绪队列的min_vruntime成员。
(2)update_load_avg更新该进程调度实体的负载和CFS就绪队列的赋值。
(3)如果CFS运行队列中的可运行任务数大于1,则调用check_preempt_tick()函数,检查是否需要进行抢占,即当前进程是否需要调度。
2.4 check_preempt_tick
/** Preempt the current task with a newly woken task if needed:*/
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{unsigned long ideal_runtime, delta_exec;struct sched_entity *se;s64 delta;ideal_runtime = sched_slice(cfs_rq, curr);delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;if (delta_exec > ideal_runtime) {resched_curr(rq_of(cfs_rq));/** The current task ran long enough, ensure it doesn't get* re-elected due to buddy favours.*/clear_buddies(cfs_rq, curr);return;}/** Ensure that a task that missed wakeup preemption by a* narrow margin doesn't have to wait for a full slice.* This also mitigates buddy induced latencies under load.*/if (delta_exec < sysctl_sched_min_granularity)return;se = __pick_first_entity(cfs_rq);delta = curr->vruntime - se->vruntime;if (delta < 0)return;if (delta > ideal_runtime)resched_curr(rq_of(cfs_rq));
}
这段代码是调度器中的检查任务抢占的函数。以下是对代码的详细说明:
(1)首先,定义了一些变量来保存理想运行时间(ideal_runtime)和已执行时间的增量(delta_exec)。
(2)使用sched_slice()函数计算出当前调度实体的理想运行时间。
(3)计算当前调度实体的已执行时间的增量,即sum_exec_runtime减去prev_sum_exec_runtime。
(4)如果已执行时间的增量大于理想运行时间,表示当前任务运行时间超过了预期,将当前任务重新调度,并清除与当前任务相关的伙伴(buddy)任务的优先级。
(5)如果已执行时间的增量小于sysctl_sched_min_granularity(最小调度粒度),则直接返回,避免任务因为执行时间过短而被抢占。
(6)选取CFS运行队列中的第一个调度实体,并计算当前调度实体的虚拟运行时间与选取的调度实体的虚拟运行时间之间的差值(delta)。
(7)如果delta小于0,表示当前调度实体的虚拟运行时间较小,不进行抢占。
(8)如果delta大于理想运行时间,表示当前调度实体的虚拟运行时间较大,将当前任务重新调度。
这段代码用于检查是否需要抢占当前任务。它比较当前任务的已执行时间与理想运行时间的差异,并根据一定的条件决定是否重新调度当前任务。如果当前任务的运行时间超过了预期,或者与其他任务的虚拟运行时间相比较大,将触发任务的重新调度。
因此抢占决策很容易做出决定, 如果检查发现当前进程运行需要被抢占, 那么通过resched_task发出重调度请求.这会在task_struct中设置TIF_NEED_RESCHED标志, 核心调度器会在下一个适当的时机发起重调度.
其实需要抢占的条件有下面两种可能性:
(1)curr进程的实际运行时间delta_exec比期望的时间间隔ideal_runtime长
此时说明curr进程已经运行了足够长的时间
(2)curr进程与红黑树中最左进程left虚拟运行时间的差值大于curr的期望运行时间ideal_runtime
此时说明红黑树中最左结点left与curr节点更渴望处理器, 已经接近于饥饿状态, 这个我们可以这样理解, 相对于curr进程来说, left进程如果参与调度, 其期望运行时间应该域curr进程的期望时间ideal_runtime相差不大, 而此时如果curr->vruntime - se->vruntime > curr.ideal_runtime, 我们可以初略的理解为curr进程已经优先于left进程多运行了一个周期, 而left又是红黑树总最饥渴的那个进程, 因此curr进程已经远远领先于队列中的其他进程, 此时应该补偿其他进程。
如果检查需要发生抢占, 则内核通过resched_curr(rq_of(cfs_rq))设置重调度标识, 从而触发延迟调度
2.5 resched_curr
/** resched_curr - mark rq's current task 'to be rescheduled now'.** On UP this means the setting of the need_resched flag, on SMP it* might also involve a cross-CPU call to trigger the scheduler on* the target CPU.*/
void resched_curr(struct rq *rq)
{struct task_struct *curr = rq->curr;int cpu;if (test_tsk_need_resched(curr))return;cpu = cpu_of(rq);if (cpu == smp_processor_id()) {set_tsk_need_resched(curr);set_preempt_need_resched();return;}
}
这段代码是调度器中的重新调度当前任务的函数。以下是对代码的详细说明:
(1)首先,获取当前运行队列的当前任务指针curr。
(2)如果当前任务的need_resched标志已经被设置,则直接返回,无需进行重新设置。
(3)如果当前处理器ID等于当前运行队列的处理器ID(即在本处理器上执行),则设置当前任务的need_resched标志,并设置调度器的preempt_need_resched标志,表示当前任务需要重新调度。
周期性调度器并不显式进行调度, 而是采用了延迟调度的策略, 如果发现需要抢占, 周期性调度器就设置进程的重调度标识PREEMPT_NEED_RESCHED, 然后由主调度器完成调度工作.
TIF_NEED_RESCHED标识, 表明进程需要被调度, TIF前缀表明这是一个存储在进程thread_info中flag字段的一个标识信息
在内核的一些关键位置, 会检查当前进程是否设置了重调度标志TLF_NEDD_RESCHED, 如果该进程被其他进程设置了TIF_NEED_RESCHED标志, 则函数重新执行进行调度
前面我们在check_preempt_tick中如果发现curr进程已经运行了足够长的时间, 其他进程已经开始饥饿, 那么我们就需要通过resched_curr来设置重调度标识TIF_NEED_RESCHED
参考资料
https://kernel.blog.csdn.net/article/details/52068050
https://xiaolizai.blog.csdn.net/article/details/128646726
https://www.cnblogs.com/LoyenWang/p/12249106.html
https://www.cnblogs.com/LoyenWang/p/12495319.html
https://scslab-intern.gitbooks.io/linux-kernel-hacking/content/chapter04.html
这篇关于Linux CFS调度器之周期性调度器scheduler_tick函数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





