本文主要是介绍将 cuda kernel 编译成 ptx 和 rocm的hip asm,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1,cuda 源码编译
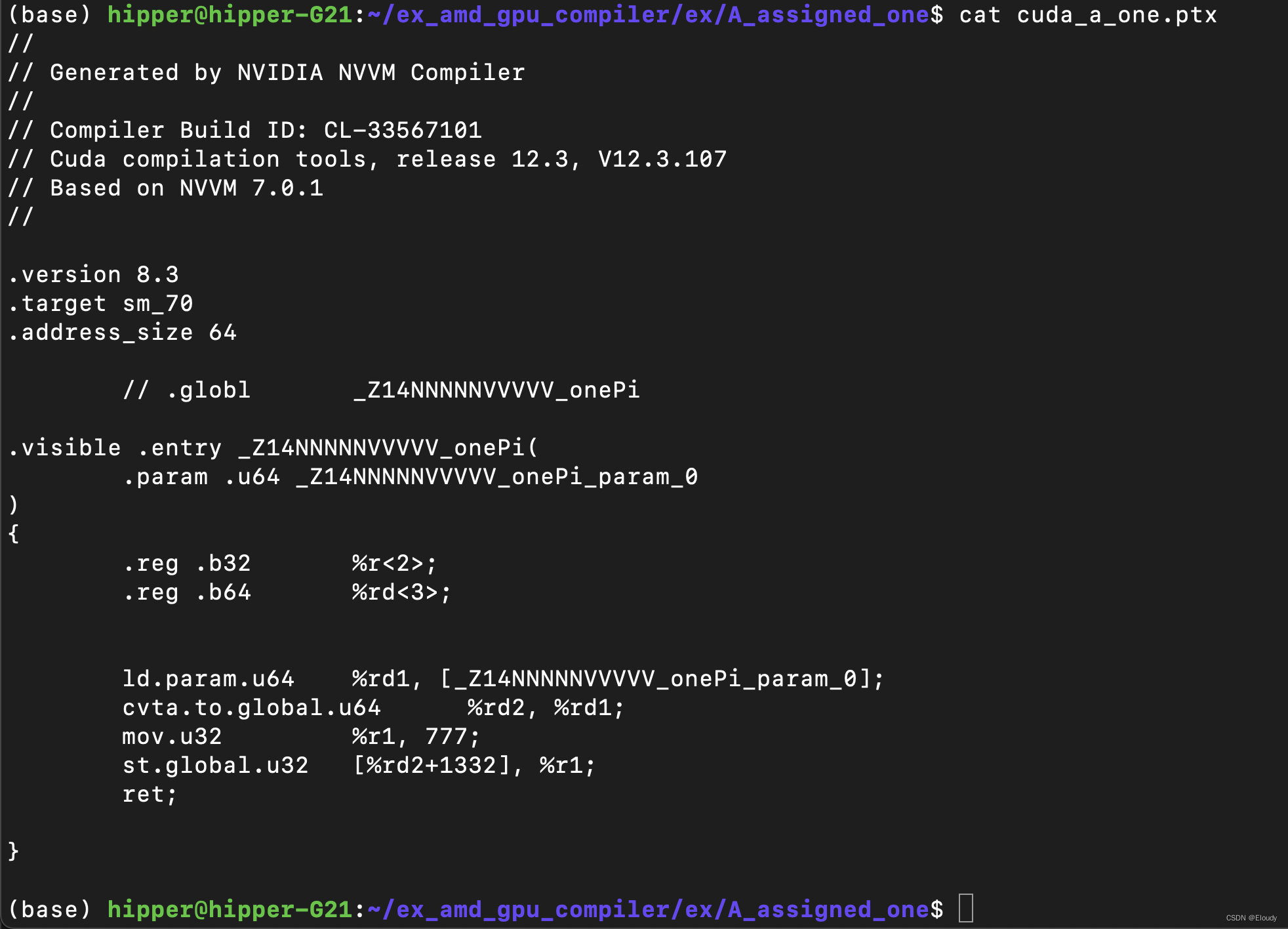
cuda_a_one.cu __global__ void NNNNNVVVVV_one(int *A)
{A[333] = 777;
}
编译命令:
%.ptx: %.cu
nvcc -arch=sm_70 -ptx $< -o $@
生成的结果:
2, hip 源码编译
hip_a_one.hip__global__ void AAAAAMMMMM_one(int *A)
{A[0x333] = 0x777;
}
编译命令:
%.hip.s: %.hip
$(HIPCC) $< -o $@ -S --offload-device-only
生成的结果:
存储为文本:
.text.amdgcn_target "amdgcn-amd-amdhsa--gfx906".protected _Z14AAAAAMMMMM_onePi ; -- Begin function _Z14AAAAAMMMMM_onePi.globl _Z14AAAAAMMMMM_onePi.p2align 8.type _Z14AAAAAMMMMM_onePi,@function
_Z14AAAAAMMMMM_onePi: ; @_Z14AAAAAMMMMM_onePi
; %bb.0:s_load_dwordx2 s[0:1], s[4:5], 0x0v_mov_b32_e32 v0, 0v_mov_b32_e32 v1, 0x777s_waitcnt lgkmcnt(0)global_store_dword v0, v1, s[0:1] offset:3276s_endpgm.section .rodata,#alloc.p2align 6, 0x0.amdhsa_kernel _Z14AAAAAMMMMM_onePi.amdhsa_group_segment_fixed_size 0.amdhsa_private_segment_fixed_size 0.amdhsa_kernarg_size 8.amdhsa_user_sgpr_count 6.amdhsa_user_sgpr_private_segment_buffer 1.amdhsa_user_sgpr_dispatch_ptr 0.amdhsa_user_sgpr_queue_ptr 0.amdhsa_user_sgpr_kernarg_segment_ptr 1.amdhsa_user_sgpr_dispatch_id 0.amdhsa_user_sgpr_flat_scratch_init 0.amdhsa_user_sgpr_private_segment_size 0.amdhsa_uses_dynamic_stack 0.amdhsa_system_sgpr_private_segment_wavefront_offset 0.amdhsa_system_sgpr_workgroup_id_x 1.amdhsa_system_sgpr_workgroup_id_y 0.amdhsa_system_sgpr_workgroup_id_z 0.amdhsa_system_sgpr_workgroup_info 0.amdhsa_system_vgpr_workitem_id 0.amdhsa_next_free_vgpr 2.amdhsa_next_free_sgpr 6.amdhsa_reserve_vcc 0.amdhsa_reserve_flat_scratch 0.amdhsa_reserve_xnack_mask 1.amdhsa_float_round_mode_32 0.amdhsa_float_round_mode_16_64 0.amdhsa_float_denorm_mode_32 3.amdhsa_float_denorm_mode_16_64 3.amdhsa_dx10_clamp 1.amdhsa_ieee_mode 1.amdhsa_fp16_overflow 0.amdhsa_exception_fp_ieee_invalid_op 0.amdhsa_exception_fp_denorm_src 0.amdhsa_exception_fp_ieee_div_zero 0.amdhsa_exception_fp_ieee_overflow 0.amdhsa_exception_fp_ieee_underflow 0.amdhsa_exception_fp_ieee_inexact 0.amdhsa_exception_int_div_zero 0.end_amdhsa_kernel.text
.Lfunc_end0:.size _Z14AAAAAMMMMM_onePi, .Lfunc_end0-_Z14AAAAAMMMMM_onePi; -- End function.section .AMDGPU.csdata
; Kernel info:
; codeLenInByte = 36
; NumSgprs: 10
; NumVgprs: 2
; ScratchSize: 0
; MemoryBound: 0
; FloatMode: 240
; IeeeMode: 1
; LDSByteSize: 0 bytes/workgroup (compile time only)
; SGPRBlocks: 1
; VGPRBlocks: 0
; NumSGPRsForWavesPerEU: 10
; NumVGPRsForWavesPerEU: 2
; Occupancy: 8
; WaveLimiterHint : 1
; COMPUTE_PGM_RSRC2:SCRATCH_EN: 0
; COMPUTE_PGM_RSRC2:USER_SGPR: 6
; COMPUTE_PGM_RSRC2:TRAP_HANDLER: 0
; COMPUTE_PGM_RSRC2:TGID_X_EN: 1
; COMPUTE_PGM_RSRC2:TGID_Y_EN: 0
; COMPUTE_PGM_RSRC2:TGID_Z_EN: 0
; COMPUTE_PGM_RSRC2:TIDIG_COMP_CNT: 0.ident "AMD clang version 17.0.0 (https://github.com/RadeonOpenCompute/llvm-project roc-6.0.2 24012 af27734ed982b52a9f1be0f035ac91726fc697e4)".section ".note.GNU-stack".addrsig.amdgpu_metadata
---
amdhsa.kernels:- .args:- .address_space: global.offset: 0.size: 8.value_kind: global_buffer.group_segment_fixed_size: 0.kernarg_segment_align: 8.kernarg_segment_size: 8.language: OpenCL C.language_version:- 2- 0.max_flat_workgroup_size: 1024.name: _Z14AAAAAMMMMM_onePi.private_segment_fixed_size: 0.sgpr_count: 10.sgpr_spill_count: 0.symbol: _Z14AAAAAMMMMM_onePi.kd.uniform_work_group_size: 1.uses_dynamic_stack: false.vgpr_count: 2.vgpr_spill_count: 0.wavefront_size: 64
amdhsa.target: amdgcn-amd-amdhsa--gfx906
amdhsa.version:- 1- 2
....end_amdgpu_metadata
3,hipcc 的概述编译流程
首先,hipcc是一个perl脚本:
#!/usr/bin/env perl
# Copyright (c) 2015 - 2021 Advanced Micro Devices, Inc. All rights reserved.
#
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
# THE SOFTWARE.# Need perl > 5.10 to use logic-defined or
use 5.006; use v5.10.1;use warnings;use File::Basename;
use File::Spec::Functions 'catfile';# TODO: By default select perl script until change incorporated in HIP build script.
my $USE_PERL_SCRIPT = $ENV{'HIP_USE_PERL_SCRIPTS'};
$USE_PERL_SCRIPT //= 1; # use defined-or assignment operator. Use env var, but if not defined default to 1.my $isWindows = ($^O eq 'MSWin32' or $^O eq 'msys');
# escapes args with quotes SWDEV-341955
foreach $arg (@ARGV) {if ($isWindows) {$arg =~ s/[^-a-zA-Z0-9_=+,.:\/\\ ]/\\$&/g;}
}my $SCRIPT_DIR=dirname(__FILE__);
if ($USE_PERL_SCRIPT) {#Invoke hipcc.plmy $HIPCC_PERL=catfile($SCRIPT_DIR, '/hipcc.pl');system($^X, $HIPCC_PERL, @ARGV);
} else {$BIN_NAME="/hipcc.bin";if ($isWindows) {$BIN_NAME="/hipcc.bin.exe";}my $HIPCC_BIN=catfile($SCRIPT_DIR, $BIN_NAME);if ( -e $HIPCC_BIN ) {#Invoke hipcc.binsystem($HIPCC_BIN, @ARGV);} else {print "hipcc.bin not present; install HIPCC binaries before proceeding\n";exit(-1);}
}# Because of this wrapper we need to check
# the output of the system command for perl and bin
# else the failures are ignored and build fails silently
if ($? == -1) {exit($?);
}
elsif ($? & 127) {exit($?);
}
else {$CMD_EXIT_CODE = $? >> 8;
}
exit($CMD_EXIT_CODE);具体工作流程:
未完待续。。。
这篇关于将 cuda kernel 编译成 ptx 和 rocm的hip asm的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![[Linux Kernel Block Layer第一篇] block layer架构设计](https://i-blog.csdnimg.cn/direct/6f402f42143b4aac927657769404055e.png)





