本文主要是介绍v4l2抓取rv1126图像,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0.准备工作
本文是基于正点原子的rv1126开发板使用mx415摄像头对不同节点的图像进行抓取
1.数据流向

图1
mx415采集到的数据为原始的拜尔格式(也就是raw格式),我们需要通过isp进行图像的调节才符合视觉,其中isp和ispp是两个处理的模块,RKAiq是其调整时候需要用到的文件,如何指定见图4,经过isp和ispp两个模块处理后的数据不再是raw数据而是可以指定的(见图3),其数据输出到/dev/videox节点上了,不同的video节点对应了四个节点分别为rkispp_m_bypass,rkispp_scale0,rkispp_scale1,rkispp_scale2其对应关系如下图2,最后再把图片输出给rkmedia。

图2
上图中红色为板子cs0摄像头的对应的节点,紫色为摄像头插在cs1时候对应的节点。
其中这四个节点也分别对应着/dev/media节点其中板子上cs0对应media的1、3,cs1对应2、4.
当我们想查询可输出什么格式图像时候我们可以执行如下代码:
v4l2-ctl --list-formats-ext --device /dev/video30
图3
最后我们来说一下如何指定iq文件,在我们执行以及编写好的文件如某个可执行文件test1的时候我们可以使用./test1 -a (iq文件路径)即 ./test1 -a /etc/iqfiles/,或者我们可以打开ispserver,即在命令框输入ispserver &让其后台运行即可,前者属于深红色的那条线即在代码直接指定了为什么使用路径,后者是橙红色的那条线即通过ispserver启动。但是也有一些注意事项:
1.不可同时指定路径并启动ispserver
2.当我们只插了一个摄像头的时候ispserver默认启动了cs0处的ispserver如果你把摄像头插在cs1则isp功能是无效的,除非插入两个摄像头。
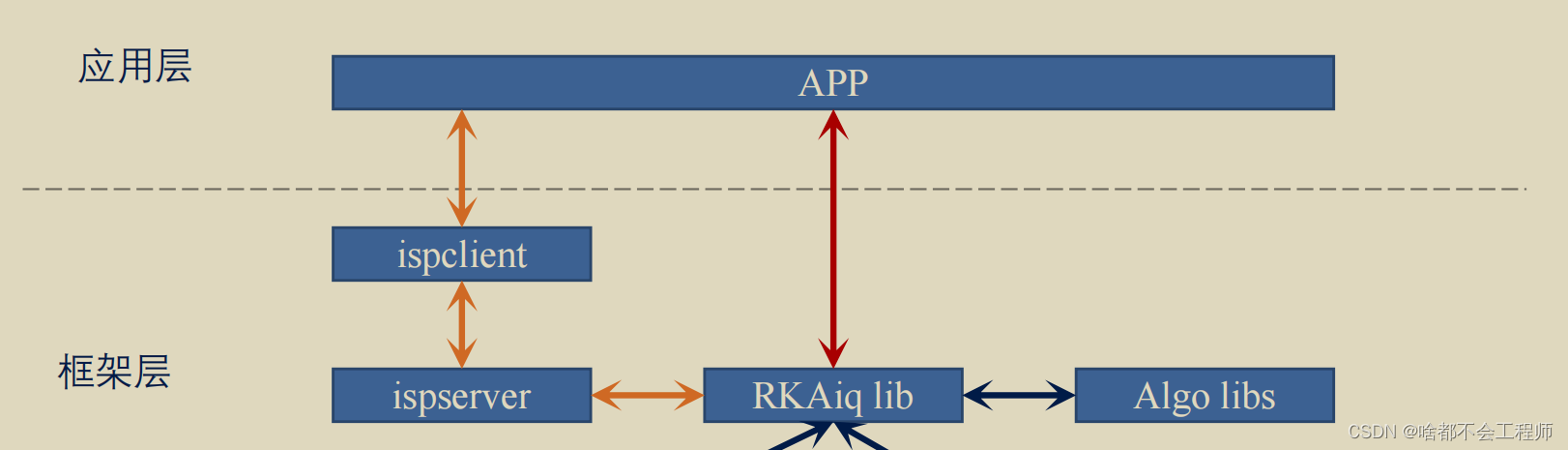
图4
但是对于我们使用v4l2抓图我们使用ispserver的方法来使用isp,因为方法以指定iq文件其实是和驱动代码相配合,我们只是抓图没有代码这一说因此使用ispserver,所以根据我们的注意事项2我们应该吧摄像头插在cs1处合适。
抓图命令,这里我们抓的是cs0的rkispp_by_pass节点下的图即/dev/video30这里我们要提前打开ispserver在后台运行即ispserver &。
v4l2-ctl -d /dev/video30 \
--set-fmt-video=width=3840,height=2160,\
pixelformat=NV12 \
--stream-mmap=3 \
--stream-skip=30 \
--stream-to=/tmp/bypass0.raw \
--stream-count=1 \
--stream-poll这里第一行指定了从哪里抓图,set fmt video指定了抓图分辨率(该接口只可以全分辨率抓),pixelformat制定了抓图的格式即输出图片格式为NV12,mmap是内存映射不管,skip是跳过前面30帧因为前面ispserver可能未初始好,to是制定了抓取图片存放的位置与名称(由于前面以及指定输出为NV12格式因此,这里的raw只是名称没有实际意义),count说明抓取一张图片,最后poll开始抓图
抓图成功之后使用adb命令从ubuntu把图片拉过来即
adb pull /tmp/bypass0.raw ./再打开查看
ffplay -f rawvideo -video_size 3840x2160 -pixel_format nv12 bypass0.raw这篇关于v4l2抓取rv1126图像的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








