本文主要是介绍端到端目标检测 |从DETR 到 GroundingDINO,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文章目录
- 一,DETR
- 1. 简介
- 2. 亮点
- 3. 细节
- 4. 总结一下
- 二,GroundingDINO
- Grounding DINO的整体流程
- Grounding DINO的目标函数
一,DETR
之前的目标检测框架,需要很多的人工干预,很多的先验知识,而且可能还需要很复杂的普通的库不支持的一些算子。
DETR 既不需要proposal, 也不需要anchor,用transformer这种能全局建模的能力,从而把目标检测看成一个集合预测的问题。
因为有了这种全局建模的能力,DETR不会输出那么多冗余的框,而不需要nms,做后处理,让训练和部署都简单了不少。
1. 简介
- 把目标检测 看成 集合预测 的问题。
- 给定一堆图片,预测这些框的坐标和类别
- 这个框就是一个集合
- 任务就是给定一个图片,我要去把这个集合预测出来
- 把目标检测 做成了 端到端 的框架
- 把之前目标检测特别依赖人的部分 (设定anchor, nms) 去掉了,就没有那么多的超惨需要去调,整个网络就变得非常简单了
2. 亮点
- DETR提出了一个目标函数
- 使用了transformer encoder-decoder架构
- 还有一个learned object queries
-
而且是并行计算的,一起出框,而不是串行的
-
新的模型很简答,不需要特殊的库,支持cnn和transformer库就可以做
-
在coco表现四十多,比当时最多的低了十个点。
-
DETR也可以去做前景分割,效果很好。
-
建议去读一下代码
3. 细节
- 之前的目标检测器都是间接的去解决问题,用了anchor, proposal, 预测中心点,nms等等。
- DETR 采用了端到端的方式,直接解决问题,简化了目标检测的流程。
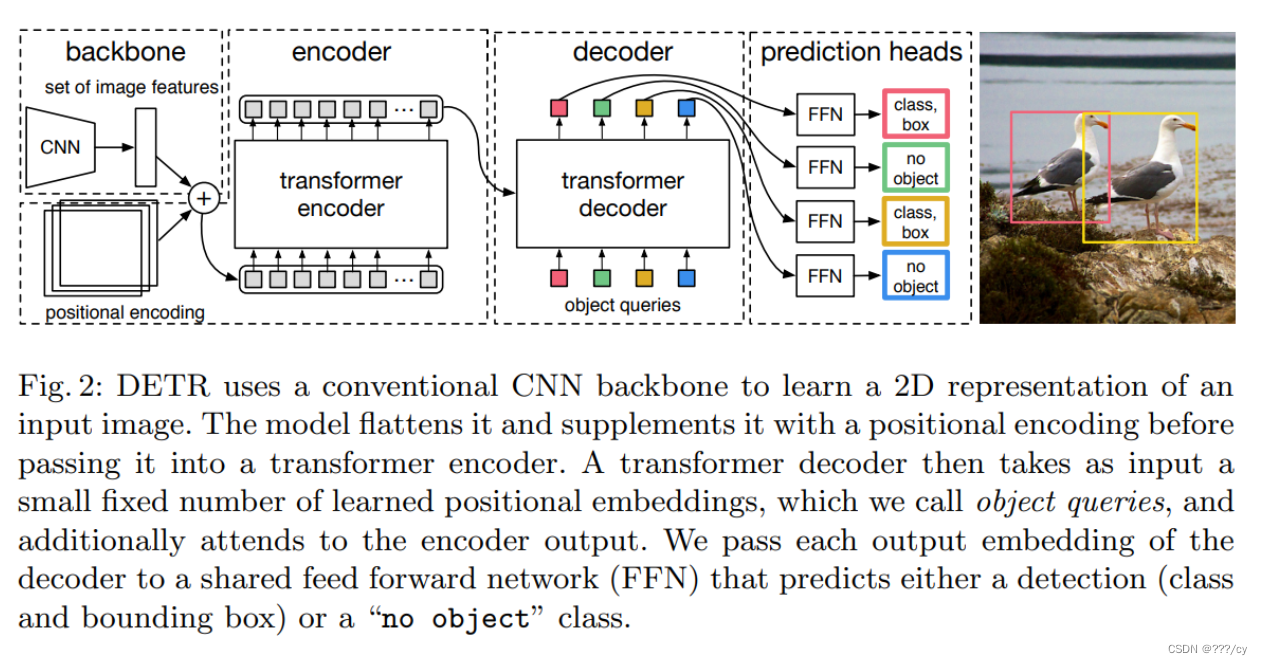
- 用卷积神经网络抽取一个图像特征,拉直,送给一个transfomer
- transfomer encoder学习一个全局的信息,为接下来的 decoder(出预测框)来做铺垫
- 使用transformer encoder, 就意味着每一个特征,都会与全局每一个特征有交互了,这样她大概就知道哪块是哪个物体,哪块又是另外一个物体,对同一个物体来说,只需要出一个框,而不是好多个框。 这种全局的特征,特别有利于去除这种冗余的框。
- 用transfomer decoder 做框的输出。当有了图像的特征之后,还有一个object quirer, 它限定了你要出多少个框,通过queire和特征去做交互,在decoder里做自注意力操作,得到了最后输出的框。
- 作者设定出100个框,100个框如何与ground truth做匹配,计算损失呢?他把这个问题看成一个集合预测的问题,用 二分图匹配的方法计算这个loss。
- 比如,ground truth有两个框,通过这输出的100个框计算与2个框的matching loss,而决定出,在这一百个预测中,哪两个框是独一无二的对应到这个红色和黄色的ground truth框的。一旦匹配好之后,就计算bbox, cls的loss, 对于没有匹配到的框就会被标记为背景类。
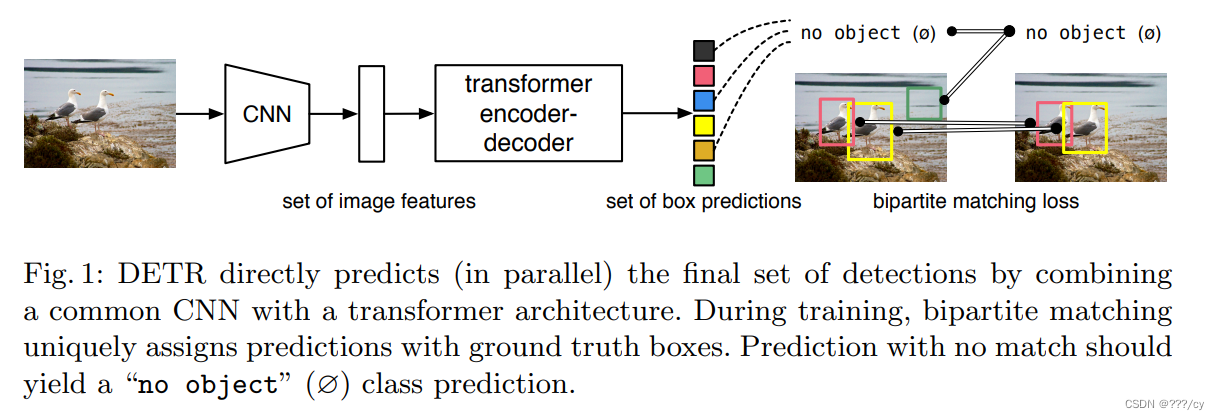
- 比如,ground truth有两个框,通过这输出的100个框计算与2个框的matching loss,而决定出,在这一百个预测中,哪两个框是独一无二的对应到这个红色和黄色的ground truth框的。一旦匹配好之后,就计算bbox, cls的loss, 对于没有匹配到的框就会被标记为背景类。
4. 总结一下
- 四步:
- 用神经网络抽特征
- 用transformer encoder学全局特征, 帮助后面做检测
- 用transformer decoder 生成很多的预测框
- 把预测框与ground truth的框做匹配,在匹配上的这些框里面去算目标检测的损失
-
推理的时候:
前三步都是一致的,直接用阈值,卡一下box preditions的置信度 > 0.7是前景物体, <0.7 就被当作背景物体了。 -
在coco与faster rcnn AP结果差不多,对大物体表现非常好,对小物体小物体效果一般。半年之后有一篇论文解决了这个问题,也解决了DETR训练太慢的问题。
损失函数:
- 匈牙利损失:基于匈牙利算法进行预测框和真实框之间的匹配,并计算匹配后的分类损失和框回归损失。
- 分类损失:采用交叉熵损失,用于预测每个框的类别。
- 框回归损失:采用GIoU损失和L1损失的组合,用于预测框的坐标。GIoU损失是IoU损失的一种改进,考虑了框的大小。
- DICE/F1损失:用于分割分支,用于预测每个框的分割掩码。
- 辅助解码损失:在解码器每层之后添加预测头,并计算匈牙利损失,有助于模型输出正确数量的每个类别的对象。
通过匈牙利匹配强制预测唯一对应真实框,同时利用分类、框回归和分割损失来训练模型,实现了端到端的检测和分割。
二,GroundingDINO
GroundingDINO 论文总结
| GroundingDINO 论文的总结,请点击上方的 跳转链接 |
- 其实和DETR的结构一模一样,各位reader从以下几个方面可以自己对比一下。
- encoder-decoder
- object query
- 二分图匹配
Grounding 与 DETR 的不同:就是引入了文本信息,把文本图像相互融合了三次。做到文本指导图片的这么一个能力。

Language-guide Query Selection 给定图像特征和文本特征,Language-guide Query Selection模块首先计算两者的相关性得分,然后根据得分选择最相关的图像特征作为queries。这些queries包含了图像和文本的信息,随后会被送入解码器进行进一步处理。
Grounding DINO的整体流程
1. 特征提取: 首先,通过图像backbone和文本backbone分别提取输入图像和文本的特征。
2. 特征增强: 接着,将提取的图像特征和文本特征输入特征增强模块,通过自注意力、图像到文本的交叉注意力和文本到图像的交叉注意力实现跨模态特征融合。
3. 查询选择: 然后,利用语言指导的查询选择模块,从增强后的图像特征中选出与输入文本更相关的特征作为解码器的查询。
4. 解码器: 接着,将选择的查询输入跨模态解码器,解码器包含自注意力层、图像交叉注意力层、文本交叉注意力层和FFN层,用于进一步融合图像和文本特征,并更新查询表示。
5. 预测输出: 最后,利用解码器最后一层的输出查询进行目标框预测和对应短语提取。
6. 损失函数: 在整个流程中,使用对比损失、框回归损失和GIOU损失进行多任务学习。
总体来说,Grounding DINO通过在特征增强、查询选择和解码器等多个阶段进行跨模态特征融合,实现了对任意文本指定的目标检测。
Grounding DINO的目标函数
- 对比损失(Contrastive Loss):用于预测对象和语言标记之间的分类。使用点积计算每个查询与文本特征之间的预测logits,然后计算每个logit的Focal loss。
- 框回归损失(Box L1 Loss):用于预测对象的边界框坐标。用于计算预测框和真实框坐标之间的绝对误差。
- GIOU损失(GIOU Loss):用于预测对象边界框的准确度。用于衡量预测框和真实框的形状和位置重叠情况,考虑到重叠区域和整体框的面积。
这些损失首先用于进行预测与真值之间的匈牙利匹配,然后计算最终损失。 此外,在模型的每个解码器层和解码器输出之后,还添加了辅助损失。对比损失、框回归损失和GIOU损失在匹配和最终损失计算中的权重分别为2.0、5.0和2.0。
这篇关于端到端目标检测 |从DETR 到 GroundingDINO的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[数据集][目标检测]血细胞检测数据集VOC+YOLO格式2757张4类别](https://i-blog.csdnimg.cn/direct/22c867ab717d44c78b985ed667169b42.png)