本文主要是介绍AI日报:百度发布文心大模型学习机;Open-Sora 1.1可生成21秒视频;Canva可以自动剪辑视频了;超牛ComfyUI节点AnyNode来了,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。
新鲜AI产品点击了解:AIbase - 智能匹配最适合您的AI产品和网站
1、百度文心大模型学习机“小度学习机Z30”发布
这篇文章介绍了百度旗下的小度科技推出的首款基于文心大模型的学习机Z30,旨在重新定义AI老师,通过先进的AI技术助力孩子主动学习,同时让家长享受全陪伴的超省心体验。该学习机拥有出色的视觉体验和多项先进技术,以及针对多个学习环节的全面重构,提供科学、高效的学习方案。AI老师能够提供丰富的教育内容,支持多轮交互和个性化定制,让学习更加生动有趣和高效有针对性。

【AiBase提要:】
📚 小度Z30学习机采用文心大模型技术,逼真还原课文情景,帮助孩子更好地理解和掌握知识。
👩🏫 小度Z30支持AI师生互动课和课后个性化练习,量身定制学习计划,实现全科全学段的随时答疑。
💡 AI老师基于文心知识增强的大模型,为孩子提供权威且丰富的教育内容,支持多模态感知和拟人化呈现,让学习更加生动有趣。
2、Open-Sora 1.1发布 视频质量提升,生成时长延长至21秒
Open-Sora1.1发布带来了显著提升,尤其在视频生成质量和时长方面。新版本模型能生成最长约21秒视频,使用高质量视觉数据和字幕训练,提升对世界运作的理解。CausalVideoVAE架构优化提高性能和推理效率。

【AiBase提要:】
🚀 视频生成质量和时长提升: 新版本能生成最长约21秒视频,通过高质量视觉数据和字幕训练,提升对世界运作的理解。
🔍 高质量视觉数据和字幕训练: 使用更高质量的视觉数据和字幕进行训练,增强模型对世界运作的理解。
⚙️ CausalVideoVAE架构优化: 优化后的架构提高了视频生成的性能和推理效率,与Sora基础模型性能相似。
详情链接:Open-Sora-Plan-v1.1.0使用入口地址 Ai模型最新工具和软件app下载
在线体验地址:https://huggingface.co/spaces/LanguageBind/Open-Sora-Plan-v1.1.0
3、Canva上线多个好用功能:文本生成插画、自动剪辑视频精华片段
Canva设计平台最新更新旨在提升专业团队和工作空间的吸引力,包括重新设计平台、推出企业版、提供AI风格匹配功能等。更新内容涵盖多项功能和改进,使设计工作更高效便捷。
【AiBase提要:】
🎨 Canva推出企业版,提供更多协作和安全性控制。
🌟 新增AI风格匹配功能,定制工作区显示文件夹。
💡 Canva Docs推出建议模式和彩色突出显示块,提供编辑建议和强调文本区域。
4、超牛ComfyUI节点AnyNode来了!要啥功能让AI帮你编写
AnyNode是ComfyUI中一个令人印象深刻的新节点,利用了大型语言模型(LLMs)的能力,允许用户通过输入提示词来创建具有特定功能的节点。它为用户提供了在ComfyUI中进行多样化操作的工具,极大地扩展了用户在创建自定义节点和工作流时的可能性。对于希望实现高级功能和自动化任务的用户来说,无疑是一个宝贵的资源。
作者发布的视频教程
【AiBase提要:】
🔑 功能编写: 用户可以根据要求编写Python函数,实现任何功能。
🔧 灵活性: 用户可以通过提示词让LLM帮助编写不同类型的节点,如文本总结、颜色通道调整、Ins滤镜效果等。
🔗 与ComfyUI的兼容性: AnyNode作为ComfyUI中的节点,可以与其他节点配合使用,链接到所需的输出格式节点。
详情链接:https://top.aibase.com/tool/anynode
5、ChatTTS:一个专为对话场景设计的语音生成模型
ChatTTS是一个专为对话场景设计的语音生成模型,支持中文和英文,通过大量数据训练,提供高质量和自然度的语音合成。项目团队计划开源一个基础模型,注重模型的可控性和安全性。用户在使用ChatTTS时需注意免责声明,开源模型将为社区带来新的学习和创新机会。

【AiBase提要:】
🔑 应用场景广泛:ChatTTS适用于大型语言模型助手的对话任务、对话语音和视频介绍,提供自然流畅的交互体验。
🔑 多语言支持:模型支持中文和英文,跨越语言障碍,服务于更广泛的用户群体。
🔑 开源计划:团队计划开源一个基础模型,促进学术界和开发者社区的研究和开发。
详情链接:https://www.bilibili.com/video/BV1zn4y1o7iV/
项目地址:ChatTTS使用入口地址 Ai模型最新工具和软件app下载
6、视频修复项目ProPainter发布Comfyui节点
这篇文章介绍了ComfyUI_ProPainter_Nodes项目,它是一个专门针对视频修复的解决方案,基于ProPainter框架并实现了ComfyUI界面。该项目提供了高级视频帧编辑和无缝的视频修复任务,为视频编辑和修复领域带来了强大的工具。
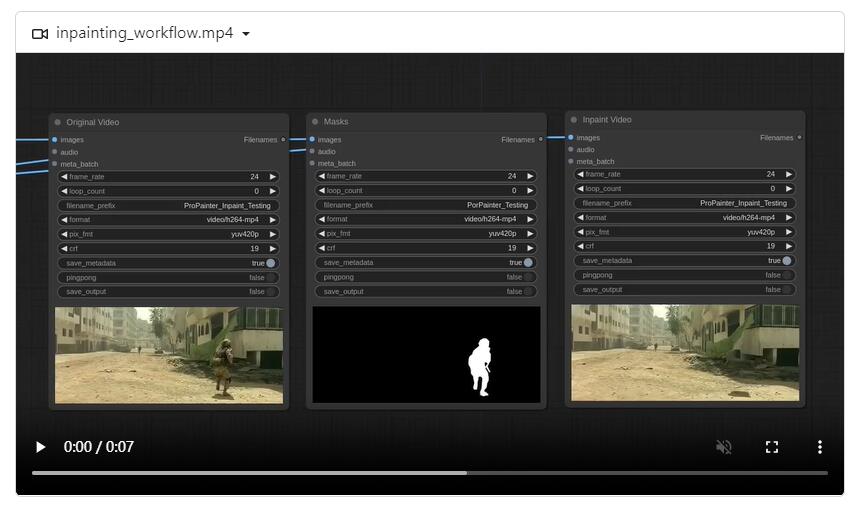
【AiBase提要:】
🔧 基于ProPainter框架,提供高级视频帧编辑和无缝的视频修复任务。
🎨 提供视频修复节点,包括ProPainter节点和ProPainter Outpainting节点。
📚 提供详细的安装说明、工作流程示例和推荐节点,丰富的输入参数和节点参考信息。
详情链接:https://top.aibase.com/tool/comfyui-propainter-nodes
7、AI可以生成手语手势视频了!SignLLM通过文字描述即可生成手语视频
SignLLM是一项创新的多语言手语模型,为听力障碍者提供了重要的沟通工具,推动了人工智能在语言理解和生成领域的研究。它通过文字描述生成手语视频,促进信息的无障碍交流。
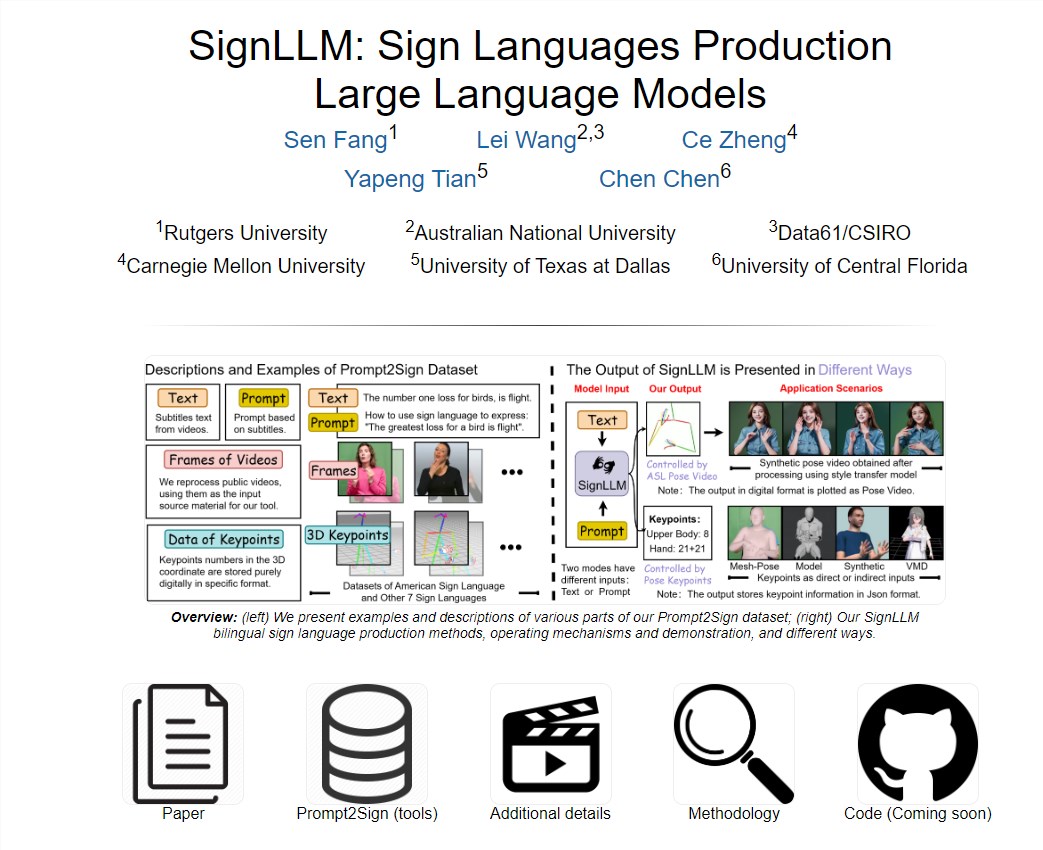
【AiBase提要:】
🤖 文本到手语视频转换:SignLLM模型能将文本转化为手语手势视频,直观易懂。
🌍 支持多种手语:包括美国手语(ASL)、德国手语(GSL)等八种手语,适用性广泛。
📊 首创多语言手语数据集:引入Prompt2Sign数据集,对模型训练和发展至关重要。
详情链接:https://top.aibase.com/tool/signllm
8、降噪黑科技Look Once to Hear!只需看一眼说话的人 除了他以外的声音就消失了
这篇文章介绍了一种先进的降噪耳机技术“Look Once to Hear”,通过用户的视觉输入来控制声音的放大或消除。这项技术在嘈杂环境中提供了专注和便利,让用户能够清晰听到目标说话者的声音。可能结合了人工智能、机器学习和声音处理算法,对听力障碍者尤其有用。

【AiBase提要:】
👀 视觉控制: 用户只需短暂看向想要聆听的说话者,耳机便能识别并放大该说话者的声音。
🌆 环境适应性: 适用于嘈杂环境,帮助用户在街道、咖啡馆等场合中清晰听到目标说话者的声音。
🚶 移动中使用: 即使用户在移动中,耳机能持续追踪并播放目标说话者的语音,提供专注和便利。
详情链接:https://top.aibase.com/tool/lookoncetohear
9、Meta被曝使用Instagram等照片训练AI模型引发隐私争议
这篇文章揭露了Meta利用Instagram和Facebook用户照片训练AI模型的隐私争议。用户隐私受到严重侵犯,数据隐私搜集条例被严重违反。Meta声称用户可以退出数据搜集模式,但之前搜集的数据仍可能保存在AI模型中,引发关注和担忧。在数据隐私和保护方面,企业应加强合规措施,确保用户个人信息得到妥善处理和保护。
【AiBase提要:】
📷 Meta使用用户照片训练AI模型,违反数据隐私搜集条例
🔍 用户隐私受到侵犯,引发广泛关注
❌ 用户可以退出数据搜集模式,但之前搜集的数据仍可能保存在AI模型中
10、比对口型还牛!InstructAvatar:实现文字生成指定面部的表情和动作
InstructAvatar 是一项最新的对话形象生成模型,通过文本引导方法实现了对情感和面部动作的细粒度控制,提升了虚拟形象的互动性和泛化能力。该模型在细粒度情感控制、口型同步质量和自然性方面优于现有方法,能指定面部的表情和动作,为生成具有情感表达的2D虚拟形象带来了突破性进展。

【AiBase提要:】
👄 InstructAvatar 实现了对情感和面部动作的细粒度控制,提升了虚拟形象的互动性和泛化能力。
😊 实验结果显示,InstructAvatar 在细粒度情感控制、口型同步质量和自然性方面优于现有方法,能指定面部的表情和动作。
🎭 InstructAvatar 的框架包括变分自动编码器(VAE)和基于扩散模型的动作生成器,通过自然语言界面实现了对生成视频的细粒度控制。
详情链接:https://top.aibase.com/tool/instructavatar
11、马斯克的 xAI 融资 60 亿美元,估值达 240 亿美元
Elon Musk的xAI公司在B轮融资中成功筹集了60亿美元,使公司估值达到240亿美元。该公司致力于开发先进的人工智能系统,旨在为全人类提供真实、有能力且最大限度有益的AI技术。最新融资将用于推出首个产品、建设先进基础设施,并加速未来技术的研发。
【AiBase提要:】
💰 xAI公司在B轮融资中筹集了60亿美元,估值达240亿美元
🚀 最新融资将用于推出首个产品、建设先进基础设施,并加速未来技术的研发
🤖 xAI正在开发先进的人工智能系统,旨在为全人类提供真实、有能力且最大限度有益的AI技术
12、苹果的“Greymatter 项目”将是普通用户在日常中可使用的AI工具
苹果将在即将到来的WWDC上展示其最新的人工智能进展,重点放在普通用户可以在日常生活中使用的AI工具上。新计划名为“Project Greymatter”,将整合AI工具到主要应用中,并改进操作系统通知功能。苹果的AI策略是追赶竞争对手,利用用户基础和隐私品牌形象继续引领市场。
【AiBase提要:】
🔍 苹果将在WWDC展示最新的人工智能进展,专注于普通用户可用的AI工具。
🛠 苹果计划将AI工具整合到主要应用中,改进操作系统通知功能。
💬 苹果与OpenAI合作开发聊天机器人,但不会在WWDC展示,而是作为插件显示在iOS18中。
这篇关于AI日报:百度发布文心大模型学习机;Open-Sora 1.1可生成21秒视频;Canva可以自动剪辑视频了;超牛ComfyUI节点AnyNode来了的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








