comfyui专题
从0到1,AI我来了- (7)AI应用-ComfyUI-II(进阶)
上篇comfyUI 入门 ,了解了TA是个啥,这篇,我们通过ComfyUI 及其相关Lora 模型,生成一些更惊艳的图片。这篇主要了解这些内容: 1、哪里获取模型? 2、实践如何画一个美女? 3、附录: 1)相关SD(稳定扩散模型的组成部分) 2)模型放置目录(重要)

Differential Diffusion,赋予每个像素它应有的力量,以及在comfyui中的测试效果
🥽原论文要点 首先是原论文地址:https://differential-diffusion.github.io/paper.pdf 其次是git介绍地址:GitHub - exx8/differential-diffusion 感兴趣的朋友们可以自行阅读。 首先,论文开篇就给了一个例子: 我们的方法根据给定的图片和文本提示,以不同的程度改变图像的不同区域。这种可控性允许我们再现
![[ComfyUI]Flux:不花钱免费白嫖最强反推JoyCaption,仅需几步无门槛轻松搞定](https://img-blog.csdnimg.cn/direct/4a2d3a791f754642af3f0383c95ee9c7.png#pic_center)
[ComfyUI]Flux:不花钱免费白嫖最强反推JoyCaption,仅需几步无门槛轻松搞定
大家好我是极客菌!!! 今天文章主题将为大家介绍一款优秀的图像反推模型:Joy Caption。这是由作者Fancy Feast开发的Joy Caption模型,是在谷歌的SigLIP模型和Meta的最新Llama3.1 模型的基础之上,使用Adapter适配模式,并通过精心训练出的优秀图像反推描述LLM模型。能够根据用户设置参数,输出相应的具有丰富细节的图像描述提示语。 • Google
2024最新comfyui保姆级教程来啦!comfyui工作流搭建看这一篇就够了!
前言 一、SD主流 UI Stable Diffusion(SD)因为其开源特性,有着较高的受欢迎程度,并且基于SD的开源社区及教程、插件等,都是所有工具里最多的。基于SD,有不同的操作界面,可以理解为一个工具的不同客户端。WebUI和ComfyUI是两种较为流行的操作界面选项 1. WebUI : 优点:界面友好,插件丰富,新手小白基本也能秒上手 缺点:吃显存,对配置要求较高,出图较慢

ComfyUI上手使用记录
文章目录 资料安装基础概念常用的工具和插件放大图像从裁剪到重绘SDXL工作流搭建Clip的多种不同的应用Lcm-Turbo极速出图集成节点 资料 AI绘画之ComfyUI Stable Diffusion WEUI中的SDV1.5与SDXL模型结构Config对比 stable-diffusion-webui中stability的sdv1.5和sdxl模型结构config对比

ComfyUI 中 Safetensors 文件的介绍
什么是安全张量? Safetensors是Hugging Face开发的一种新的序列化格式; 它就像一种保存和检索大而复杂的数据块(称为张量)的特殊方法,这在深度学习中至关重要; 深度学习涉及处理大量数据,有时处理这些大数据可能很棘手; Safetensors 有助于在处理深度学习时更轻松、更高效地处理这些大型且复杂的数据部分。 什么是 Safetensors 文件? Safetensors
[ComfyUI]Flux:黑神话-水墨悟空,增强写实和水墨插画风格强化
大家好我是极客菌!!! ComfyUI是一款功能强大的AI图像编辑软件,以其便捷的操作和丰富的功能,深受广大艺术爱好者和专业人士的喜爱。而Flux,一款基于深度学习的图像生成模型,以其强大的图像生成能力和个性化风格迁移能力,在艺术创作领域掀起了一场革命。 水墨融合风格模型简介 今天介绍一款国产Flux LORA模型:水墨融合风格效果强化flux.1,这是一款专注于中国画水墨融合风格
IC-Light还原细节的节点 DetailTransfer使用时报错-comfyui
🎈问题描述 今天在调试一个工作流节点的时候,遇到一个问题: Error occurred when executing DetailTransfer: The size of tensor a (848) must match the size of tensor b (853) at non-singleton dimension 2 File "F:\ComfyUI-aki\execu

从0到1,AI我来了- (6)AI应用-ComfyUI-I
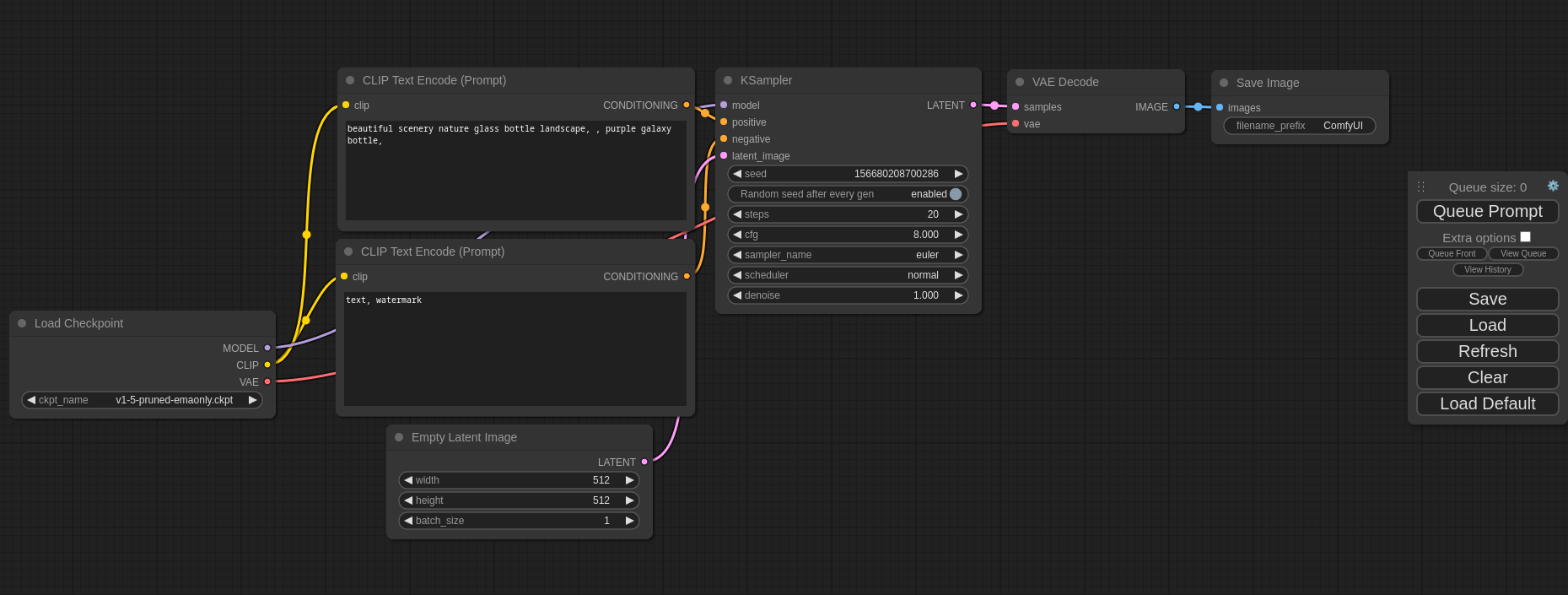
满天飞的AI图片生成,是否激发了你的创作欲望? 我们来认识下Comfy,然后看下如何安装?再跑几个案例,看下comfyUI给我们带来的 ComfyUI 是什么?解决什么问题?如何安装,并使用ComfyUI ?跟Stable Diffusion 是什么关系? 1、ComfyUI 是什么? The most powerful and modular stable diffusio

Win11 本地部署大模型 WebUI + ComfyUI
Open WebUI 是一个可扩展、功能丰富且用户友好的自托管 Web 用户界面(WebUI),它被设计用于完全离线操作。该项目最初被称为 Ollama WebUI,后来更名为 Open WebUI。Open WebUI 的主要目的是为本地的大语言模型(LLMs)提供一个图形化的交互界面,使得用户能够更加方便地调试和调用本地模型,它不仅支持本地模型,还兼容 Ollama 和 OpenAI 的 AP

comfyUI使用flux模型报错got promptUsing pytorch attention in VAE,
使用的flux模型如下,应该下载的模型都已经下载好放在正确位置 但是执行之后报错如下 got prompt Using pytorch attention in VAE Using pytorch attention in VAE 然后comfyUI的命令行就强制退出了。 解决方法: 改虚拟内存为系统管理的大小即可
全网首发!comfyui大版本更新,新版界面,操作效率爆炸
前言 所有的AI设计工具,模型和插件,都已经整理好了,👇获取~ 1、界面升级 新版 旧版 2、页面改版 1.新版的右上方这里两个蓝色的按钮是最关键的,一个是节点管理器,一个是执行队列,画图用的。 2.左上角这边包含了,创建,保存、刷新、清除等常见功能 3.左侧你会发现有个菜单栏,里面有3个栏目,分别是 队列、节点库、Nodes Map 3、搜索功能介
ComfyUI 常用的节点
总的来说,如果可以的话 最佳实践是直接访问每个节点仓库,仔细阅读作者提供的文档和说明。然后,手动执行 git clone 来获取仓库的代码。 接着,你可以通过手动执行 pip install -r requirements.txt 来安装每个项目的依赖。这种方法可以让你更好地理解每个项目的依赖关系,同时也可以在遇到问题时提供更多的调试信息。 1. Co

「ComfyUI」增强图像细节只需要一个节点,SD1.5、SDXL、FLUX.1 全支持,简单好用!
前言 前 言 今天听雨给小伙伴们介绍一个非常简单,但又相当好使的一个插件。 功能很简单,就是增加或者减少图像的细节,节点也很简单,就一个节点,只需要嵌入我们的 ComfyUI 的基础工作流中就可以了,随插随用。 而且该插件不仅支持 SD1.5 和 SDXL,甚至最新出的 FLUX.1 模型也是支持的哦! 好了,话不多说,我们直接开整。 我们先来看效果,这里使用的是 FLUX.
深夜小灶|如何利用comfyUI生成《黑神话:悟空》风格的建筑效果图
前言 近期大卖《黑神话:悟空》,因其完美的融合了中国传统文化与现代游戏元素而广受好评 而其中极具中式特点建筑风格也让不少玩家眼前一亮。 因此在本篇教程中我将介绍如何使用ComfyUI这一强大的AI工具,来生成具有《黑神话:悟空》风格的建筑效果图。 所有的AI设计工具,模型和插件,都已经整理好了,👇获取~ 前期准备 要完成黑神话:悟空》风格的建筑效果图的绘制,首先

comfyUI和SD webUI都有哪些差别呢?
ComfyUI和SD WebUI都是用于AI绘画的用户界面,它们各自有着不同的特点和适用场景。以下是两者之间的一些关键差别: 1、用户体验与界面友好性: SD WebUI(Stable Diffusion Web User Interface)以其直观易用著称,特别受初学者欢迎。它的界面布局清晰,功能模块一目了然,用户可以很容易地找到所需的功能,降低了使用难度。ComfyUI虽然

comfyUI工作流-Flux大模型应用/黑神话悟空角色生成(附lora)
是什么让悟空开始搬砖,这莫不是新的副本 其实我们用AI就能生成这种黑神话悟空的衍生图片 让悟空做ceo,做老师,上工地搬砖 七十二变,体验人生百态 操作很简单,只需要一个comfyUI工作流,你就能任意生成黑神话悟空的不同职业图片 前期准备: 确保ComfyUI和Flux大模型已部署 首先,需要确保你的ComfyUI已经部署好了Flux大
基于 ComfyUI 原生的 FLUX.1 分区域融合出图技巧,效果超级棒!
前言 今天给小伙伴们分享一下 ComfyUI 的原生的分区域融合出图技巧,不需要额外下载插件哦! 简单来介绍一下,就是把一张大图分割成几个部分,然后每个部分写自己区域的提示词,最终汇总融合成一张图片,可能不太准确,但是差不多就是这么个意思! 最近 Flux.1 比较火嘛,我们就用 Flux.1 来做下演示! 好了,话不多说,我们直接开整。 — 还是一样,我们先来看效果: 首先,我们可

ComfyUI 和 WebUI
概述 ComfyUI:像拼积木一样,你可以用各种“模块”搭建出一个复杂的图像生成“机器”。适合那些喜欢自己动手折腾、希望精确控制每个步骤的人。WebUI:更像是一个智能“图像生成器”,你只需要输入文字描述,它就能生成图片。适合那些想快速得到结果,不想研究复杂流程的人。 ComfyUI ComfyUI 是一个非常灵活的图像生成工具。你可以想象它是一个“搭积木”的系统,你把不同的功能模块(比如颜

AI绘画ComfyUI-插件-面部修复,快速入门安装使用!
这期给大家分享一个插件AI绘画 ComfyUI的——Impact Pack ComfyUI也是隶属于Stable Diffusion的工作流形式的AI绘画工具。 这是一个综合节点,这期先介绍下这个插件中的面部修复功能 Impact Pack插件 1、下载插件 在ComfyUI管理器中安装节点,搜索Impact Pack 点击安装,然后重启,这时候右键【新建节点】可以看到多了一个【Imp
emm, ComfyUI的作者从Stability.AI离职了
🍖背景 今天在更新ComfyUI的过程中,看到Manager中有这样一段描述: 嗯?做了新的官方网站?然后开始新篇章? 难道说ComfyUI的作者从Stability.AI离职了? 赶紧点开链接看了下,emm,还真的是这样的,那ComfyUI后续的维护和更新会是如何呢?新篇章又会如何发展呢?我们可以一起看看作者写的更新日志。 👑ComfyUI的下一站 (以下内容直接翻译原作者

Ollama(docker)+ Open Webui(docker)+Comfyui
Windows 系统可以安装docker desktop 相对比较好用一点,其他的应该也可以 比如rancher desktop podman desktop 安装需要windows WSL 安装ollama docker docker run -d --gpus=all -v D:\ollama:/root/.ollama -p 11434:11434 --name ollama ol

comfyui虚拟试衣、ai换装、电商换装源码
一、AI换装技术博客 1. 项目介绍 IDM-VTON 是一个虚拟试衣模型,可以在 ComfyUI 中进行部署。相比于其他虚拟试衣模型,如 OOTDiffusion,IDM-VTON 提升了图像保真度和细节保留,更强调真实感,而且就算是侧面的模特或者背面的模特都能上身,已经完全达到了商用的水平。该项目简化了部署过程,是一个不错的选择。 项目地址 GitHub项目地址:https://gith

【第10章】如何获取免费“工作流”?(国内外网站推荐/下载/使用)ComfyUI基础入门教程
使用ComfyUI的一个重点,就是可以快速使用别人分享的工作流,来完成特定的图像生成任务,从而提升工作效率。 那么,去哪儿可以找到别人分享的工作流呢? 这节课我们了解下,比较知名的工作流网站有哪些?以及如何下载? 备注:下节课再讲如何使用。 🎆“老牌” workflow网站Openart.ai 【网址】https://openart.ai/home 【网络】需要魔法,才能

【第11章】别人的工作流,如何使用和调试(上)?(2类必现报错/缺失节点/缺失模型/思路/实操/通用调试步骤)ComfyUI基础入门教程
经过前面章节的学习,相信大家对于工作流是什么?如何搭建?怎么使用基础的工作流?已经很清楚了。 那么,接下来的课程,我们会上一点难度, 并且更接近实战状态了。 这节课,我们就用一套从“文本 - 静帧 - 视频”的AI短片全流程工作流,讲一下,网络上下载的工作流,需要如何调试才能正常使用? 🏀前期准备 首先,我们需要从网盘找到本节课需要用到的工作流——AI短片全流程 【AI短