本文主要是介绍Python 全栈体系【四阶】(五十三),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第五章 深度学习
十二、光学字符识别(OCR)
2. 文字检测技术
2.3 DB(2020)
DB全称是Differentiable Binarization(可微分二值化),是近年提出的利用图像分割方法进行文字检测的模型。前文所提到的模型,使用一个水平矩形框或带角度的矩形框对文字进行定位,这种定位方式无法应用于弯曲文字和不规范分布文字的检测。DB模型利用图像分割方法,预测出每个像素的类别(是文字/不是文字),可以用于任意形状的文字检测。如下图所示:

2.3.1 基本流程
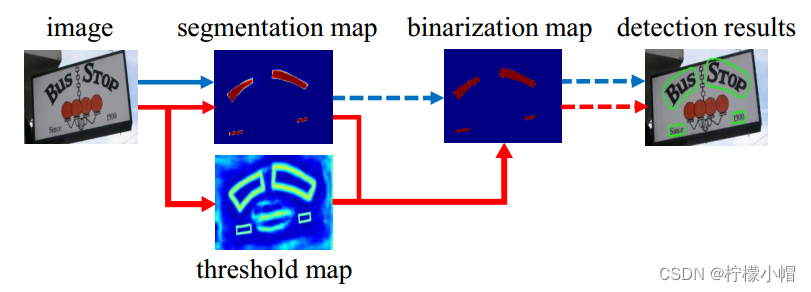
DB之前的一些基于图像分割的文字检测模型,识别原理如上图蓝色箭头所标记流程:
-
第一步,对原图进行分割,预测出每个像素的属于文本/非文本区域的概率;
-
第二步,根据第一步生成的概率,和某个固定阈值进行比较,产生一个二值化图;
-
第三步,采用一些启发式技术(例如像素聚类)将像素分组为文本示例。
DB模型的流程如上图红色箭头所示流程:
-
第一步,对原图进行分割,预测出每个像素的属于文本/非文本区域的概率。同时,预测一个threshold map(阈值图)
-
第二步,采用第一步预测的概率和预测的阈值进行比较(不是直接和阈值比较,而是通过构建一个公式进行计算),根据计算结果,得到二值化图。在计算二值化图过程中,采用了一种二值化的近似函数,称为可微分二值化(Differentiable Binarization),在训练过程中,该函数完全可微分;
-
第三步,根据二值化结果生成分割结果。
2.3.2 标签值生成
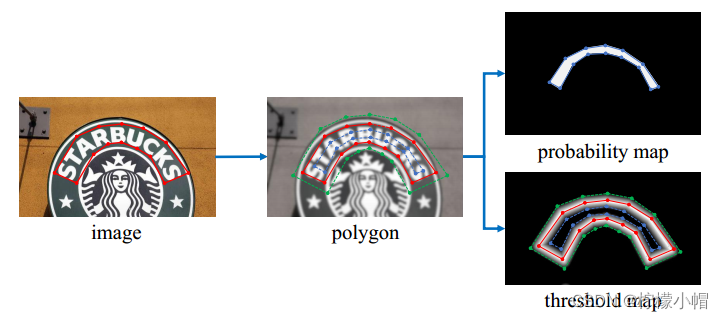
对于每个经过原始标记的样本(上图中第一张图像),采用Vatti clipping algorithm算法(一种用于计算多边形裁剪的算法)对多边形进行缩放,得到缩放后的多边形作为文字边沿(如上图中第二张图像绿色、蓝色多边形所示)。计算公式:
D = A ( 1 − r 2 ) L D = \frac{A(1 - r^2)}{L} D=LA(1−r2)
其中,D是收缩放量,A为多边形面积,L为多边形周长,r是缩放系数,设置为0.4. 根据计算出的偏移量D进行缩小,得到缩小的多边形(第二张图像蓝色边沿所示);根据偏移量D放大,得到放大的多边形(第二张图像绿色边沿所示),两个边沿间的部分就是文字边界。
2.3.3 模型结构
Differentiable Binarization模型结构如下图所示:

模型经过卷积,得到不同降采样比率的特征图,经过特征融合后,产生一组分割概率图、一组阈值预测图,然后微分二值化算法做近似二值化处理,得到预测二值化图。传统的二值化方法一般采用阈值分割法,计算公式为:
B i , j = { 1 , i f P i , j ≥ t 0 , o t h e r w i s e (1) B_{i, j} = \begin{cases} 1,\quad if \ P_{i,j} \ge t \\ 0, \quad otherwise \end{cases} \tag{1} Bi,j={1,if Pi,j≥t0,otherwise(1)
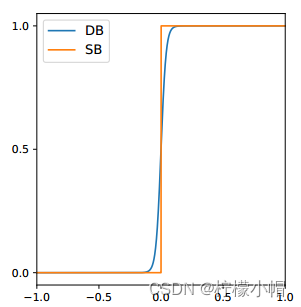
上式描述的二值化方法是不可微分的,导致在训练期间无法与分割网络部分一起优化,为了解决这个问题,DB模型采用了近似阶跃函数的、可微分二值化函数。函数定义如下:
B ^ i , j = 1 1 + e − k ( P i , j − T i , j ) \hat B_{i, j} = \frac{1}{1+e^{-k(P_{i,j} - T_{i, j})}} B^i,j=1+e−k(Pi,j−Ti,j)1
其中, P i , j P_{i,j} Pi,j表示预测概率, T i , j T_{i, j} Ti,j表示阈值,两个值相减后经过系数 K K K放大,当预测概率越大于阈值,则输出值越逼近1。
# 可谓分二值化函数示例
import mathP1 = 0.6 # 预测概率1
P2 = 0.4 # 预测概率2
T = 0.5 # 阈值
K = 50B1 = 1.0 / (1 + pow(math.e, -K * (P1 - T)))
print("B1:", B1) # B1:0.9933 趋近于1B2 = 1.0 / (1 + pow(math.e, -K * (P2 - T)))
print("B2:", B2) # B2:0.00669 趋近于0
2.3.4 损失函数
DB模型损失函数如下所示:
L = L s + α × L b + β × L t L = L_s + \alpha \times L_b + \beta \times L_t L=Ls+α×Lb+β×Lt
其中, L s L_s Ls是预测概率图的loss部分, L b L_b Lb是二值图的loss部分, α \alpha α和 β \beta β值分别设置为1和10. L s L_s Ls和 L b L_b Lb均采用二值交叉熵:
L s = L b = ∑ i ∈ S l y i l o g x i + ( 1 − y i ) l o g ( 1 − x i ) L_s = L_b = \sum_{i \in S_l} y_i log x_i + (1 - y_i) log(1-x_i) Ls=Lb=i∈Sl∑yilogxi+(1−yi)log(1−xi)
上式中 S l S_l Sl是样本集合,正负样本比例为1:3.
L t Lt Lt指经过膨胀后的多边形区域中的像素预测结果和标签值之间的 L 1 L1 L1距离之和:
L t = ∑ i ∈ R d ∣ y i ∗ − x i ∗ ∣ L_t = \sum_{i \in R_d} |y_i ^* - x_i ^*| Lt=i∈Rd∑∣yi∗−xi∗∣
R d R_d Rd值膨胀区域 G d G_d Gd内的像素索引, y i ∗ y_i ^* yi∗是阈值图的标签值。
2.3.5 涉及到的数据集
模型在以下6个数据集下进行了实验:
- SynthText:合成数据集,包含80万张图像,用于模型训练
- MLT-2017:多语言数据集,包含9种语言,7200张训练图像,1800张验证图像及9000张测试图像,用于模型微调
- ICDAR 2015:包含1000幅训练图像和500幅测试图像,分辨率720*1280,提供了单词级别标记
- MSRA-TD500:包含中英文的多语言数据集,300张训练图像及200张测试图像
- CTW1500:专门用于弯曲文本的数据集,1000个训练图像和500个测试图像,文本行级别标记
- Total-Text:包含各种形状的文本,及水平、多方向和弯曲文字,1255个训练图像和300个测试图像,单词级别标记
为了扩充数据量,论文采用了随机旋转(-10°~10°角度内)、随机裁剪、随机翻转等策略进行数据增强。

2.3.6 效果
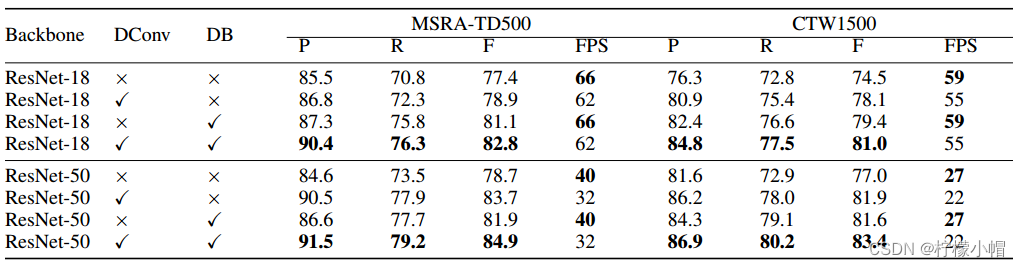
- 不同设置结果比较,“DConv”表示可变形卷积。“P”、“R”和“F”分别表示精度、召回率和F度量。
- Total-Text数据集下测试结果,括号中的值表示输入图像的高度,“*”表示使用多尺度进行测试,“MTS”和“PSE”是Mask TextSpotter和PSENet的缩写

- CTW1500数据集下测试结果。括号中的值表示输入图像的高度。
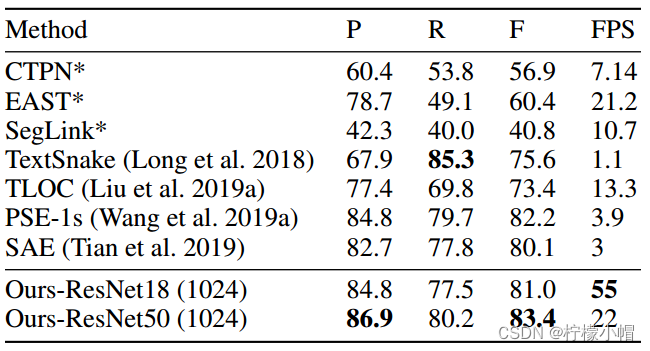
- ICDAR 2015数据集下测试结果。括号中的值表示输入图像的高度,“TB”和“PSE”是TextBoxes++和PSENet的缩写。
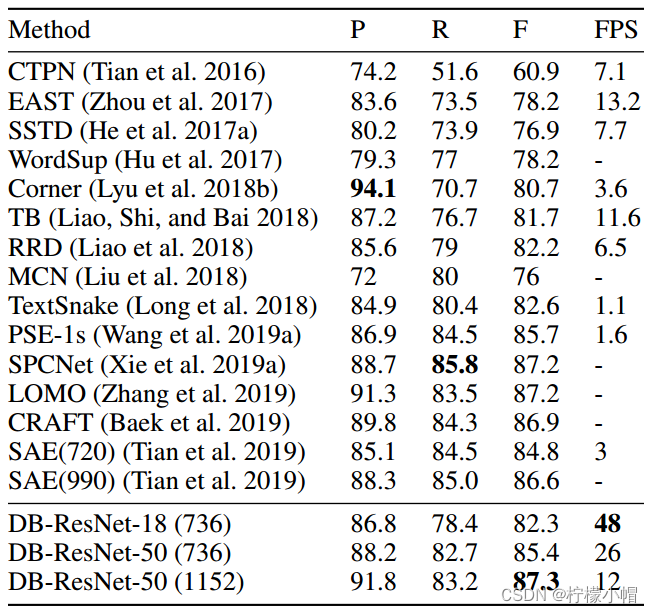
- MSRA-TD500数据集下测试结果。括号中的值表示输入图像的高度。
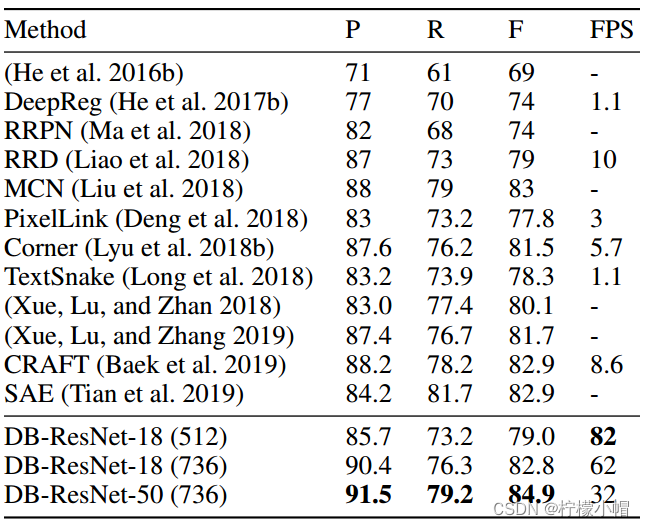
- MLT-2017数据集下测试结果。“PSE”是PSENet的缩写。
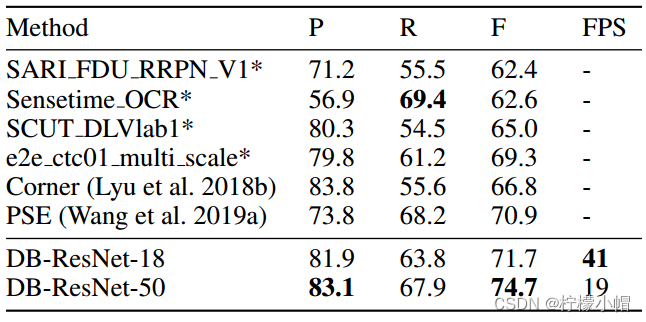
2.3.7 结论
- 能有效检测弯曲文本、不规范分布文本
- 具有较好的精度和速度
- 局限:不能处理文本中包含文本的情况
这篇关于Python 全栈体系【四阶】(五十三)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




