本文主要是介绍【传知代码】无监督动画中关节动画的运动表示-论文复现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 概述
- 动画技术的演进
- 原理介绍
- 核心逻辑
- 环境配置/部署方式
- 小结
本文涉及的源码可从无监督动画中关节动画的运动表示该文章下方附件获取
概述
该文探讨了动画在教育和娱乐中的作用,以及通过数据驱动方法简化动画制作的尝试。近期研究通过无监督运动转移减少对真实数据的依赖,取得一定进展,但仍面临关节和非刚性对象运动的表示、运动序列动画化及背景运动处理等问题。为解决这些挑战,文章提出三个贡献:
-
使用区域表示一阶运动以增强稳定性;
-
明确建模背景运动以提高点识别的稳定性;
-
在无监督空间中解耦对象的形状和姿态,防止形状转移。这些改进提升了无监督运动转移的精度,特别是对于关节对象的动画。
作者还提出一个新的TED演讲者数据集以验证方法,其性能优于现有无监督动画技术。
动画技术的演进
图像动画方法相关工作总结
图像动画方法可以大致分为监督和无监督两类,每种方法都有其独特的挑战和局限性。这篇总结概述了这两类方法中的已有工作,为论文关注的无监督方法提供背景。

检测实现的静止源图像动画
监督图像动画:
监督方法在训练期间需要关于动画对象的先验知识,通常以地标、语义分割或参数化的3D模型的形式存在。这些方法受到标记数据的需求的限制,仅适用于具有丰富标记数据集的少数对象类别,例如面部和人体。早期的面部再现工作利用3D可塑模型,使用图形技术进行动画和渲染。神经网络后来被引入以提高渲染质量,有时需要每个身份的多个图像 。
监督方法的重要部分将动画视为图像到图像或视频到视频的转换问题,将问题限制为对单个对象实例进行动画处理,无论是面部还是人体。尽管这些方法取得了一些有希望的结果,但在更广泛的对象类别范围内进行泛化仍然具有挑战性。此外,它们往往不仅传递了运动,还传递了驱动对象的形状 。
无监督图像动画:
无监督方法旨在克服监督方法的局限性,通过消除对动画对象形状或地标的标记数据的需求。这一类别包括基于视频生成的动画方法,其根据初始帧和动画类别标签预测未来帧 。值得注意的是,Menapace等人引入了可玩的视频生成,允许在每个时间戳选择动作 。
另一组无监督方法专注于将动画从驱动视频重新定向到源帧。X2Face构建了输入面的规范表示,生成了一个基于驱动视频的变形场 。Monkey-Net学习无监督关键点以生成动画,随后的工作,包括第一阶段运动模型(FOMM),通过考虑每个关键点的局部仿射变换来增强动画质量。
从经验上看,这些无监督方法通常在动画对象的边界上提取关键点,对于人体等关节对象,内部运动建模不足,导致动画不自然。
原理介绍
在无监督学习的动画领域中,关节动画的运动表示原理主要基于对人体或物体运动的模拟。关节动画是一种常用的计算机动画技术,它通过模拟人体或物体的关节运动来实现复杂的动画效果。以下是无监督动画中关节动画的运动表示原理的详细介绍:
一、关节动画的基本原理
关节动画的基本原理是将一个复杂的物体或角色(如人体)分解为一系列相互连接的关节(或骨骼),然后通过控制这些关节的运动来实现整个物体或角色的运动。在动画中,这些关节之间的连接关系形成了一种层次结构,类似于生物体的骨骼系统。
二、关节动画的表示方法
- 骨架:关节动画的核心是骨架,它由一系列具有层次关系的关节(骨骼)和关节链组成。这些关节通过连接形成了一种树结构,其中一个关节被选作根关节,其他关节则是根关节的子孙。通过平移和旋转根关节,可以移动并确定整个骨架在世界空间中的位置和方向。
- 关节的表示:通常,每个关节都会包含一些基本信息,如关节名、父关节索引、关节绑定姿势的逆变换矩阵(offset矩阵)等。关节的绑定姿势是指蒙皮网格顶点绑定至骨骼时,关节的位置、朝向和缩放。这些信息对于确定关节的运动状态和动画效果至关重要。
- 姿势的表示:关节的姿势被定义为关节相对于某坐标系的位置、朝向和缩放。在关节动画中,通常存在三种姿势:绑定姿势、局部姿势和全局姿势。绑定姿势是网格绑定到骨骼之前的姿势,局部姿势是关节相对于父关节来指定的,全局姿势则是关节在整个动画模型所在的坐标空间中的变换。
三、无监督动画中的关节动画
在无监督学习的动画中,关节动画的运动表示原理与传统关节动画类似,但更加注重从数据中学习和推断关节的运动规律。通过大量的无标签视频数据,无监督学习算法可以自动提取出物体或角色的运动特征,并学习到关节之间的运动约束和相互关系。这样,即使在没有明确标注的情况下,算法也能够生成符合自然规律的关节动画效果。
核心逻辑

- 一阶运动模型
FOMM 主要包括两个部分:运动估计和图像生成,其中运动估计进一步包含粗糙运动估计和密集运动预测。粗糙运动被建模为分离对象部分之间的稀疏运动,而密集运动则生成整个图像的光流和置信度图。我们用S和D分别表示源帧和驱动帧,这两者来自同一视频。
首先从S和D估计各个对象部分的粗糙运动。每个对象部分的运动由仿射变换表示,Ak ∈ R^2x3,到一个抽象的共同参考帧R;X可以是S或D。针对K个不同的部分估计运动。编码器-解码器关键点预测网络输出K个热图,M1到MK,这些热图对输入图像进行建模,然后经过softmax,使得Mk ∈ [0,1]^HW,满足∑Mk(z) = 1,其中z是图像中的像素位置。这样,仿射变换的平移分量(即Ak的最后一列)可以使用softargmax进行估计。
在FOMM 中,剩余的仿射参数通过每个像素进行回归,形成4个附加通道。用于索引仿射矩阵。这个模型被称为基于回归的模型,因为仿射参数由网络预测并进行池化以计算。D和S之间的每个部分k的运动然后通过公共参考帧计算。
- 基于PCA的运动估计
准确的运动估计是实现高质量图像动画的主要要求。与FOMM不同,我们采用了不同的运动表示方式,即所有运动直接从热图Mk中测量。我们像以前一样计算平移,而x和y方向的平面旋转和缩放则通过热图Mk的主成分分析(PCA)进行计算。
这里使用奇异值分解(SVD)方法来计算PCA,将热图的协方差分解为酉矩阵Uk和V_k以及奇异值的对角矩阵S_k。我们称这种方法为基于PCA的方法,与基于回归的方法相对。尽管这两者在此使用相同的区域表示和编码器,但由于我们创新的前景运动表示,编码的区域之间存在显著的差异,将前景映射到有意义的对象部分,例如关节。
- 背景运动估计
背景占据图像的大部分。因此,即使在帧之间有微小的背景运动,例如由于摄像机运动引起的运动,也会对动画质量产生负面影响。FOMM未将背景运动单独处理,因此必须使用关键点对其进行建模。这带来了两个负面影响:(i)需要额外的网络容量,因为关键点用于模拟背景而不是前景;(ii)过度拟合训练集,因为这些关键点集中在背景的特定部分上,而这些部分可能在测试集中不存在。因此,我们使用编码器网络额外预测背景仿射变换。由于我们的框架是无监督的,背景网络可能将前景的某些部分包
含到背景运动中。实际上,这并没有发生,因为对于网络来说,使用前景的更适当的基于PCA的运动表示要比使用S和D编码前景运动更简单。从经验上讲,我们证明了所提出的运动表示可以在完全无监督的情况下分离背景和前景。
- 图像生成
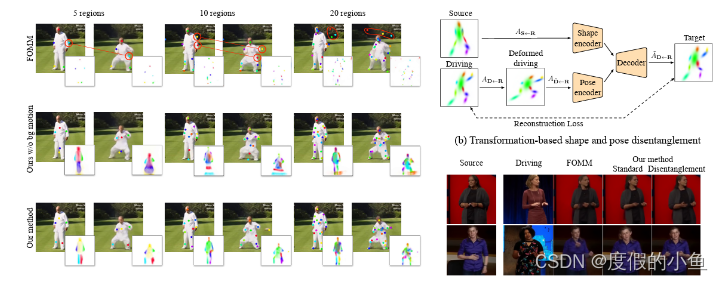
- 与FOMM 类似,我们将目标图像分为两个阶段进行渲染:像素级的光流生成器将粗糙运动转换为密集光流,然后根据光流对源的编码特征进行变形,随后对缺失区域进行修补。密集光流预测器的输入是一个HxWx(4K+3)张量,每个区域有四个通道,每个区域有三个用于根据区域的仿射变换变形的源图像通道,一个用于区域的热图的高斯近似,另外三个通道用于根据背景的仿射变换变形的源图像。与FOMM不同,后者使用常数方差,我们从热图中估计协方差。
这种模型在背景运动略有变化时会变得复杂。当有轻微的背景运动时,该模型会自动适应通过将一些可用关键点分配给模拟背景来进行调整。我们还通过使用相同的网络预测置信度图C来处理源图像中缺失的部分。最后,S通过编码器传递,然后通过光流变形生成的特征图乘以置信度图。一个解码器然后重建驱动图像D。在测试时,FOMM 有两种动画模式:标准模式和相对模式。在标准动画中,逐帧计算源和驱动之间的运动。对于相对动画,为了生成帧t,首先计算D1和Dt之间的运动,然后应用于s。
通过上述改进,我们提出的方法克服了以前方法在处理关节对象时无法捕捉完整对象部分、形状和姿势的局限性。我们的基于PCA的运动表示以及背景运动估计模块提供了更高的稳定性和区域分布的改善,同时能够更好地适应不同数量的区域。我们的方法在多个数据集和任务上都取得了令人满意的定量和定性结果,为未来在这一领域的改进提供了有力的基准。
环境配置/部署方式
-
命令行参数解析:
parser = ArgumentParser() parser.add_argument("--config", required=True, help="path to config") parser.add_argument("--mode", default="train", choices=["train", "reconstruction", "animate"]) parser.add_argument("--log_dir", default='log', help="path to log into") parser.add_argument("--checkpoint", default=None, help="path to checkpoint to restore") parser.add_argument("--device_ids", default="0", type=lambda x: list(map(int, x.split(','))),help="Names of the devices comma separated.") parser.add_argument("--verbose", dest="verbose", action="store_true", help="Print model architecture") opt = parser.parse_args()- 使用
ArgumentParser解析命令行参数,包括配置文件路径--config、运行模式--mode(默认为 “train”)、日志目录--log_dir(默认为 ‘log’)、检查点路径--checkpoint、设备编号--device_ids、是否输出模型架构--verbose。 - 参数解析结果保存在
opt对象中。
- 使用
-
加载配置文件:
with open(opt.config) as f:config = yaml.load(f)- 使用
yaml.load读取配置文件,其中配置了模型参数、数据集参数等。配置信息保存在config字典中。
- 使用
-
初始化模型和数据集:
generator = OcclusionAwareGenerator(**config['model_params']['generator_params'],**config['model_params']['common_params']) discriminator = MultiScaleDiscriminator(**config['model_params']['discriminator_params'],**config['model_params']['common_params']) kp_detector = KPDetector(**config['model_params']['kp_detector_params'],**config['model_params']['common_params'])- 创建了生成器
generator、判别器discriminator和关键点检测器kp_detector。 - 模型的参数从配置文件中获取。
- 创建了生成器
-
设备配置和模型移动:
if torch.cuda.is_available():generator.to(opt.device_ids[0])discriminator.to(opt.device_ids[0])kp_detector.to(opt.device_ids[0])- 如果 GPU 可用,将模型移动到指定的 GPU 设备上。
-
日志目录和配置文件的保存:
if not os.path.exists(log_dir):os.makedirs(log_dir) if not os.path.exists(os.path.join(log_dir, os.path.basename(opt.config))):copy(opt.config, log_dir)- 创建日志目录,如果不存在的话。
- 将配置文件拷贝到日志目录中。
-
选择运行模式并调用相应函数:
if opt.mode == 'train':print("Training...")train(config, generator, discriminator, kp_detector, opt.checkpoint, log_dir, dataset, opt.device_ids) elif opt.mode == 'reconstruction':print("Reconstruction...")reconstruction(config, generator, kp_detector, opt.checkpoint, log_dir, dataset) elif opt.mode == 'animate':print("Animate...")animate(config, generator, kp_detector, opt.checkpoint, log_dir, dataset)- 根据命令行参数中的
--mode的值,选择运行训练、重建还是动画生成。 - 分别调用相应的函数:
train、reconstruction或animate。
- 根据命令行参数中的
整个代码实现了一个端到端的图像动画生成流程,用户可以通过命令行参数选择不同的模式,并在配置文件中指定模型和数据集的参数。训练模型时,通过调用 train 函数,进行模型的训练;重建时,通过调用 reconstruction 函数,进行图像的重建;动画生成时,通过调用 animate 函数,生成动画。
小结
动画技术在教育和娱乐领域的重要性不言而喻,它不仅能够提供丰富多样的视觉体验,还能有效地传达信息和知识。然而,传统的动画制作方法通常要求专业技能、昂贵的硬件和大量的时间投入,这在一定程度上限制了动画的广泛应用。
为了解决这些问题,近年来数据驱动的方法逐渐受到关注,其中无监督动画框架是一个重要的研究方向。这种框架试图通过自动学习和分析大量数据来生成动画,从而减少了对专业技能和硬件的依赖。然而,无监督动画框架在处理关节对象时面临一些挑战,其传统的表示方法往往无法准确捕捉关节的运动规律。
为了解决这一问题,研究人员提出了一种全新的PCA-Based区域运动表示方法。这种方法利用主成分分析(PCA)技术,对动画中的区域运动进行建模和表示。PCA是一种强大的数据分析工具,它能够识别数据中的主要模式和趋势,从而简化数据的复杂性。在动画中,PCA可以帮助我们更容易地学习到区域运动的关键特征,并鼓励网络学习到语义丰富的对象部分。
具体来说,PCA-Based区域运动表示方法通过以下几个步骤实现:
- 数据预处理:首先,从动画数据中提取出与关节运动相关的区域特征,例如关节的位置、速度、加速度等。
- 主成分分析:然后,利用PCA对这些区域特征进行降维处理,以识别出其中的主要运动模式。这些主要模式代表了关节运动的关键特征,可以用于后续的动画生成。
- 网络学习:接下来,将PCA提取的主要运动模式作为输入,训练一个深度学习网络来学习关节运动的规律。这个网络可以是一个循环神经网络(RNN)或卷积神经网络(CNN),具体取决于问题的复杂性和数据量。
- 动画生成:最后,利用训练好的网络生成新的动画。在生成过程中,可以根据需要调整PCA提取的主要运动模式的权重,以实现不同的动画效果。
此外,为了进一步提高动画质量,研究人员还引入了背景运动估计模块。这个模块能够有效地区分前景和背景的运动,从而避免了在动画中出现不自然的背景运动。通过解耦前景和背景的运动,可以使动画看起来更加真实和自然。
综上所述,PCA-Based区域运动表示方法以及背景运动估计模块的引入为无监督动画框架提供了新的思路和技术手段。这些方法不仅能够更准确地捕捉关节对象的运动规律,还能够提高动画的质量和真实性。随着技术的不断发展和完善,相信未来无监督动画框架将在教育和娱乐领域发挥更加重要的作用。

这篇关于【传知代码】无监督动画中关节动画的运动表示-论文复现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






