本文主要是介绍读论文 | Small object detection model for UAV aerial image based on YOLOv7,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1、前言
2、摘要
3、论文的方法
3.1 方法描述
3.2 方法改进
3.3 本论文的模型图
3.4 本文的数据集:
3.5 论文实验
3.6 解决的问题
3.7 论文总结
(1)文章优点
(2)方法创新点
(3)未来展望
1、前言
该论文代码未公开,大家看看方法啥的就好,里面详细的细节不用深究。没有公开代码的论文,一般是不看的。
原文:《Small object detection model for UAV aerial image based on YOLOv7》
2、摘要
本文介绍了一种基于YOLOv7的无人机航拍图像小目标检测模型(SOD-YOLOv7)。该模型通过结合Swin Transformer和卷积模块来捕捉图像中小物体的全局上下文信息,并引入Bi-Level Routing Attention机制以增强对小物体的关注度。此外,为了提高模型在多个尺度上的检测能力,还添加了检测分支。对于遮挡问题,采用了动态检测头与变形卷积和注意力机制相结合的方式以增强模型的目标空间感知能力。实验结果表明,在VisDrone和CARPK无人机图像数据集上,该模型的平均精度达到了53.2%和98.5%,比原始YOLOv7方法分别提高了4.3%和0.3%。
提炼如下:
(1)本文提出了一种新的方法:SOD-YOLOv7,用来解决航拍图像中小目标检测问题。
(2)通过添加STC(Swin Tansformer Conv)模块、BRA注意力机制、动态检测头等相关模块。不同模块有不同的功能。
- STC模块:可以从不同尺度的输入特征映射中提取特征,增强了模型表示输入特征图的能力,从而提高了检测性能。
- BRA注意力:是一种新的动态系数注意力,能够实现更灵活的计算分配和内容感知。它允许模型具有动态查询感知的稀疏性。增加BRA注意力模块,主要专注于密集的小目标区域。
- 动态检测头:通过利用特征层、空间位置和输出通道之间的注意机制,实现尺度感知、空间感知和任务感知。
(3)实验结果表明,增加的这些模块,使得模型精度都有所提升。
3、论文的方法
3.1 方法描述
该论文提出了一种新的目标检测模型,其架构基于YOLOv7,并引入了几个关键的改进来提高小物体检测性能。这些改进包括:
- STC模块:这是一种结合了Swin Transformer和卷积层的模块,用于提取图像中的全局信息。
- BRA注意力机制:这是一种动态稀疏注意力机制,允许更灵活的计算分配和内容感知。它使模型具有动态查询感知稀疏性。
- 四重下采样分支:这个分支将输入图像分成160x160网格单元,每个单元更小,以提高小物体检测准确性。
- 动态头:这是一个带有注意力机制的头部,可以根据不同任务、空间位置和尺度自适应地调整处理方式。
通过这些改进,该模型能够更好地捕捉小物体的细节信息并提高检测性能。
3.2 方法改进
与原始的YOLOv7相比,该模型在以下几个方面进行了改进:
- 增加了STC模块,使其能够在不同尺度上捕捉更多的全局信息。
- 引入了BRA注意力机制,可以更灵活地关注密集的小物体区域,从而减少有用特征的损失。
- 添加了四重下采样分支,提高了小物体检测的准确性。
- 使用了动态头,可以根据不同的任务、空间位置和尺度自适应地调整处理方式。
这些改进使得模型在小物体检测方面表现更好。
3.3 本论文的模型图
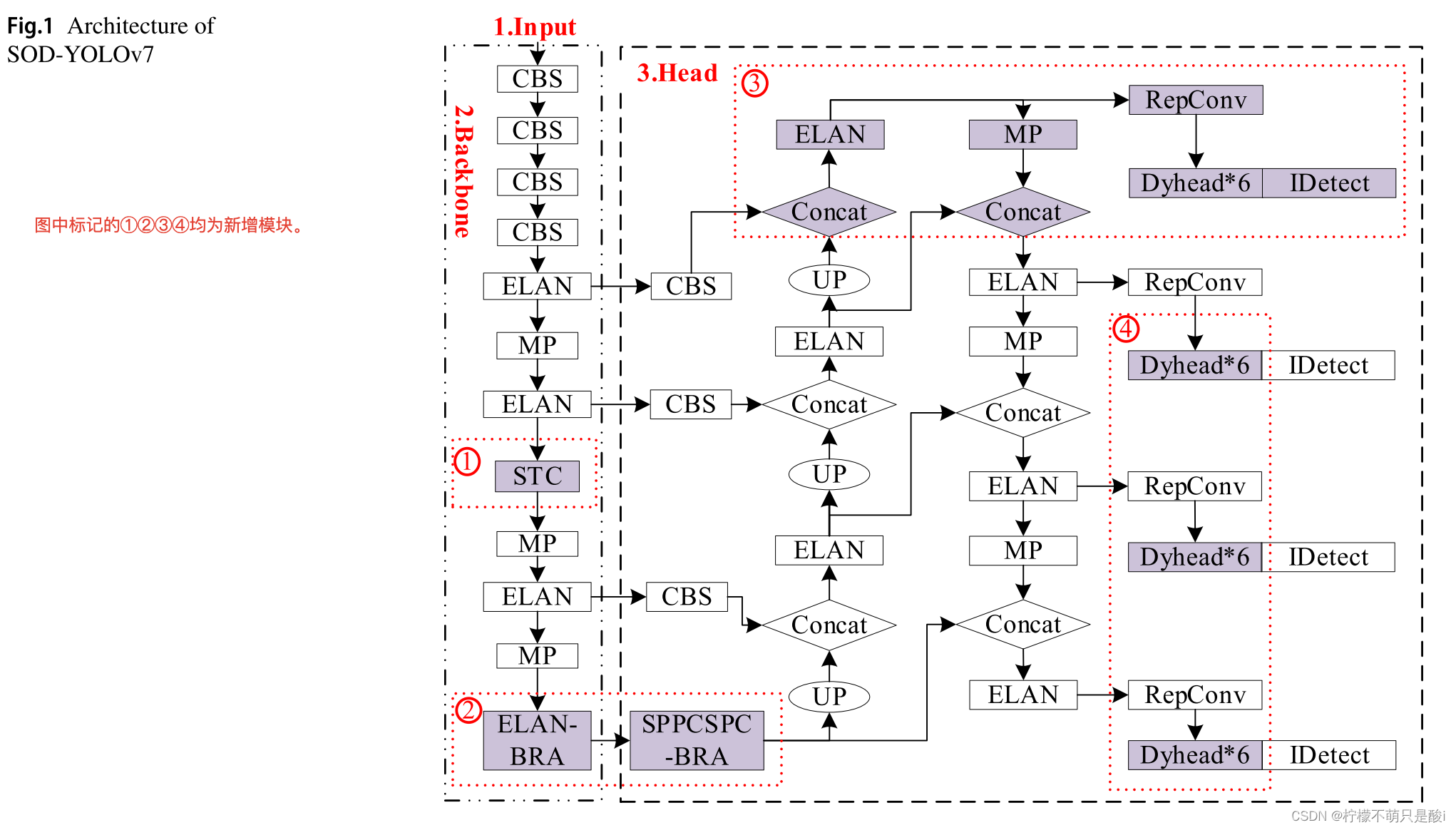
图中,红色区域的模块,为基于YOLOv7的基础上新添加的模块。
3.4 本文的数据集:
数据集:VisDrone 和 CARPK
3.5 论文实验
本文主要介绍了作者在无人机航拍图像中进行物体检测的实验,并进行了多个对比实验来验证模型的效果和改进方法的有效性。
首先,作者使用了两个数据集:VisDrone和CARPK,其中VisDrone包含了来自不同场景、天气和光照条件下的10个类别的物体,而CARPK则专注于汽车类别。作者将这些数据转换为适合YOLO模型训练的格式,并使用单个RTX A5000 GPU和PyTorch框架进行训练和推理。作者使用的评估指标包括平均精度(mAP)、参数数量、浮点运算次数(GFLOPs)、每秒帧数(FPS)以及GPU占用率等。
接着,作者进行了四个对比实验:
-
① 在VisDrone数据集上与YOLOv7的比较:SOD-YOLOv7相对于YOLOv7提高了mAP@0.5的值,但在计算复杂度和参数数量方面也有所增加。
-
② 在CARPK数据集上与YOLOv7的比较:SOD-YOLOv7相对于YOLOv7提高了mAP@0.5的值,但差异相对较小。
-
③ 对于VisDrone数据集中每个类别的mAP@0.5的分析:SOD-YOLOv7相对于YOLOv7在所有10个类别中的检测性能都有所提高,特别是对于行人、自行车和其他小物体的检测效果更好。
-
④ Ablation study:通过逐步添加增强模块,如STC模块、BRA注意力机制、四倍下采样分支和动态头模块,对模型进行改进,证明了这些模块的有效性。
此外,作者还进行了定性分析,比较了SOD-YOLOv7和YOLOv7在不同场景下的检测性能,结果表明SOD-YOLOv7能够更好地检测小物体,减少漏检和误报的情况。
总的来说,本文通过多个对比实验验证了SOD-YOLOv7模型在无人机航拍图像中进行物体检测的有效性,并探讨了一些改进方法的有效性。

3.6 解决的问题
该模型的主要目的是提高小物体检测的性能。在实际应用中,小物体往往难以被准确地检测到,因为它们通常包含较少的像素,并且与其他物体或背景相似。为了解决这个问题,研究人员提出了上述改进,以帮助模型更好地捕捉小物体的细节信息并提高检测性能。
3.7 论文总结
(1)文章优点
- 该研究针对无人机图像中存在大量小物体和物体遮挡的问题,提出了一种基于YOLOv7的小目标检测模型SOD-YOLOv7。
- 研究人员结合了Swin Transformer和Bi-Level Routing Attention等技术,设计了一个特征提取网络,专门用于解决小目标检测问题,并引入了一个多尺度特征聚合网络来处理不同尺度下的小目标。
- 实验结果表明,在VisDrone和CARPK数据集上,SOD-YOLOv7相比于其他同类模型在平均精度上有显著提升,并且能够有效地提高小目标的检测准确率,同时保持大目标的检测准确性。
(2)方法创新点
- 研究人员采用了多种先进技术,如Swin Transformer、Bi-Level Routing Attention等,以增强模型对小目标的识别能力。
- 设计了一个多尺度特征聚合网络,可以有效处理不同尺度下的小目标,提高了模型的鲁棒性和泛化性能。
- 引入了对象检测头中的注意力机制和空间感知能力,进一步增强了模型对遮挡物体的识别能力。
(3)未来展望
- 尽管SOD-YOLOv7在实验中表现出了优异的性能,但仍然需要进一步探索如何减少模型参数和计算资源的需求,以便实现实时检测。
- 可以考虑将深度学习技术和传统计算机视觉算法相结合,以更好地应对无人机图像中小目标检测的问题。
- 可以尝试使用更多的数据增强技术,如旋转、缩放、裁剪等,以增加训练样本的数量,从而提高模型的泛化性能。
这篇关于读论文 | Small object detection model for UAV aerial image based on YOLOv7的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





