非聚专题

聚簇索引和非聚簇索引(相关小知识点)
前言 终于有时间写写博客,记录下聚簇索引与非聚簇索引的相关小知识点。 知识点 1、聚簇索引和非聚簇索引的各自适用场景? 2、聚簇索引和非聚簇索引的优劣势? 优势: 叶子节点会存储数据,找到叶子节点就找到了数据行,无需回表; 对于辅助索引,使用主键作为指针而不是地址值,,减少了出现行移动或者数据页分裂时辅助索引的维护工作; 在排序场景下,由于聚簇索引的物理位置和数据行的逻辑位置
MySQL索引(聚簇索引、非聚簇索引)
了解MySQL索引详细,本文只做整理归纳:https://blog.csdn.net/wangfeijiu/article/details/113409719 概念 索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。 索引分类 主键索引:primary key 设定为主键后,数据库自动建立索引,InnoDB为聚簇索引,主键索引列值不能为空(Null

数据库聚簇索引和非聚簇索引的区别
聚簇索引(Clustered Index)和非聚簇索引(Non-clustered Index)是数据库中两种不同的索引类型,它们的主要区别在于数据的存储方式和索引的结构: 数据存储方式: 聚簇索引:索引的叶子节点存储的是数据行本身,而不是指向数据行的指针。换句话说,聚簇索引决定了数据的物理存储顺序,因此表中的数据行实际上是按照聚簇索引的顺序存储的。 非聚簇索引:索引的叶子节点存储的是

B+树以及非聚簇索引和聚簇索引
1 B树以及B+树 1.1 B树 是一种多路搜索树,假设为M叉树 1. 每个节点中的关键字,比指向儿子的指针少一,即每个节点最多有M-1个关键字和M个指针 2. 关键字集合分布在整棵树中,任何一个关键字出现且只出现在一个节点中,即是说,有可能在非叶子节点命中。 1.2 B+树 B+树是B树的变种,也是一种多路搜索树,假设为M叉树 1. 每个节点的关键字个数和指向儿子的指针
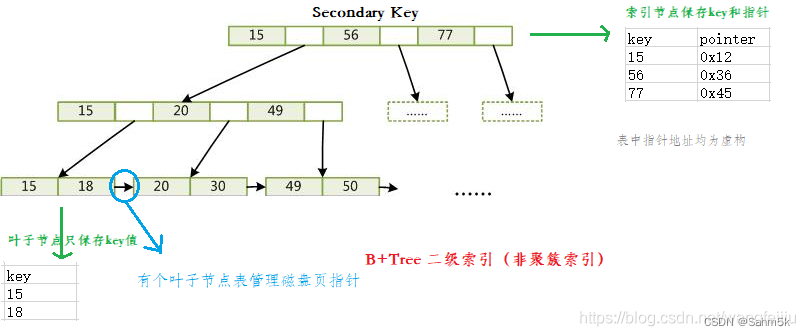
MySQL - 聚簇索引和非聚簇索引
1. 聚簇索引 聚簇索引是一种数据存储方式:在 InnoDB 中,聚簇索引是通过将表的数据存储在按照索引键值排序的 B+ 树结构中来实现的。 B+Tree 的叶子节点就是行记录,行记录和主键值紧凑地存储在一起, 这也意味着 InnoDB 的主键索引就是数据表本身,它按主键顺序存放了整张表的数据,占用的空间就是整个表数据量的大小。通常说的主键索引就是聚集索引。 InnoDB 的表要求必须要有聚簇
MySQL--优化(索引--聚簇和非聚簇索引)
MySQL–优化(索引–聚簇和非聚簇索引) 定位慢查询SQL执行计划索引 存储引擎索引底层数据结构聚簇和非聚簇索引索引创建原则索引失效场景 SQL优化经验 一、聚簇索引 聚簇索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据特点:必须有,而且只有一个 聚簇索引在 B+树中的数据结构 二、非聚簇索引(二级索引) 非聚簇索引(二级索引):将数据与索引分开存储,索

聚簇索引、非聚簇索引、回表、索引下推、覆盖索引
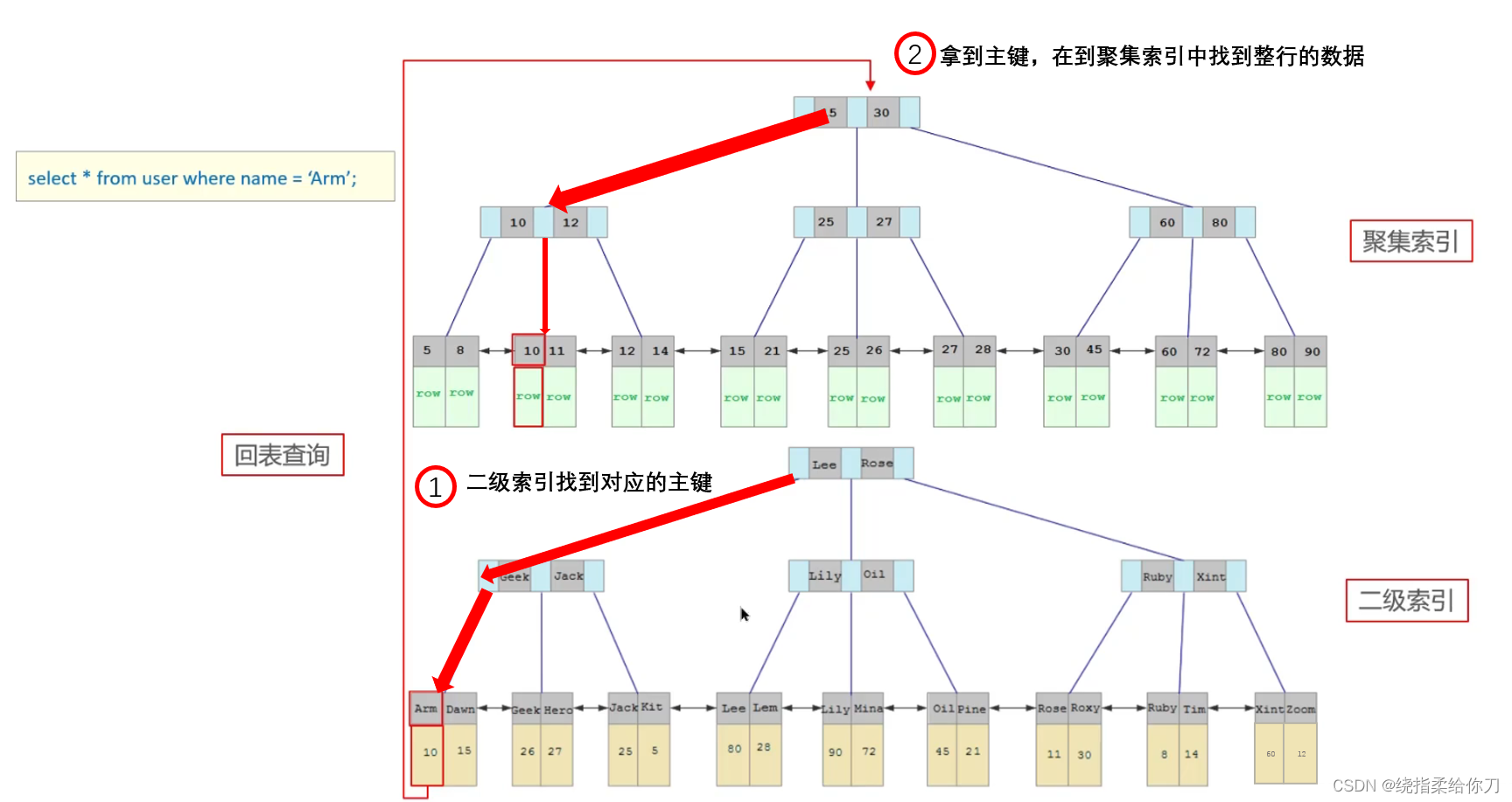
聚簇索引(主键索引) 非叶子节点上存储的是索引值,叶子节点上存储的是整行记录。 非聚簇索引(非主键索引、二级索引) 非叶子节点上存储的都是索引值,叶子节点上存储的是主键的值。非聚簇索引需要回表,IO消耗。 回表 非聚簇索引先执行一次主键查询,再通过适配的主键的值之后,再进行一次二级索引,这个过程就是回表。 覆盖索引 一次索引就可以得到数据,无需回表。覆盖索引发生在联合索引,where

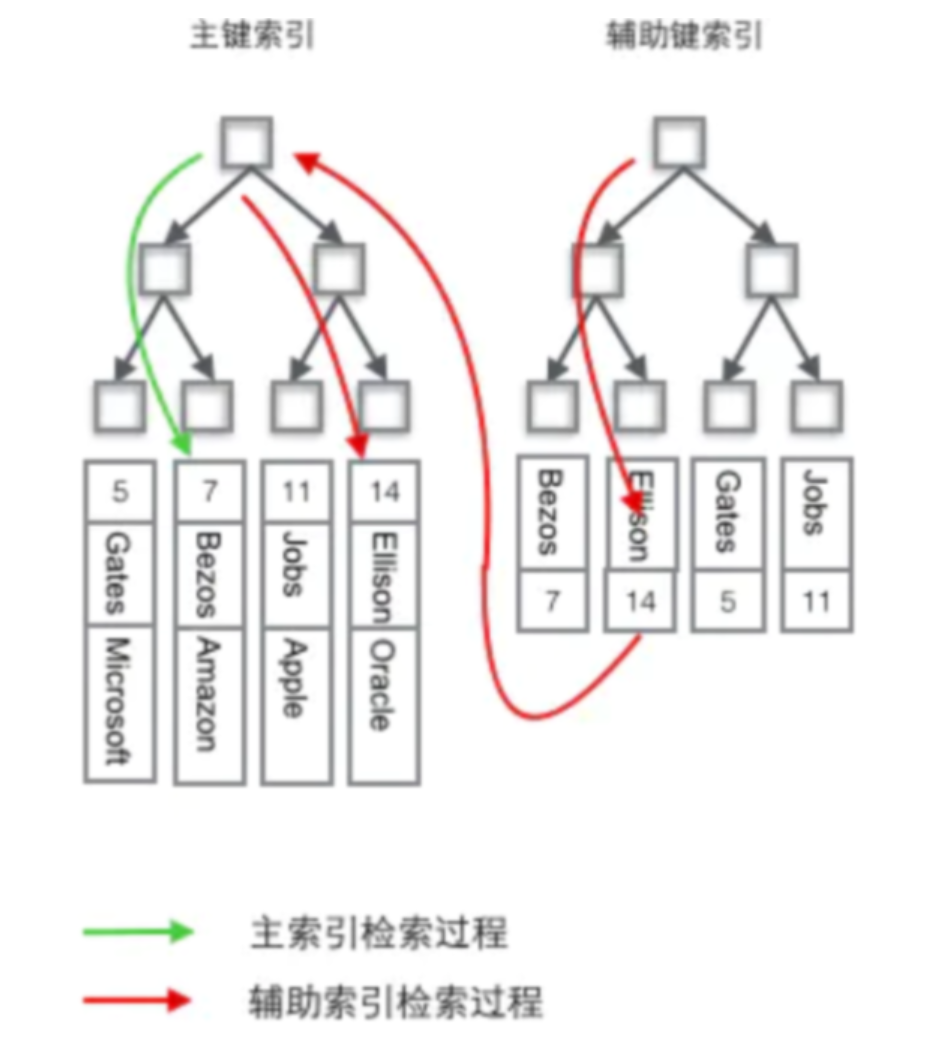
聚簇索引的效率明显要低于非聚簇索引,为什么还需要聚簇索引?
每次使用辅助索引检索都要经过两次B+树查找,看上去聚簇索引的效率明显要低于非聚簇索引,这不是多此一举吗?聚簇索引的优势在哪? 由于行数据和聚簇索引的叶子节点存储在一起,同一页中会有多条行数据,访问同一数据页不同行记录时,已经把页加载到了Buffer中(缓冲池), 再次访问时,会在内存中完成访问,不必访问磁盘。这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了, 如果按照主
mysql聚簇索引和非聚簇索引
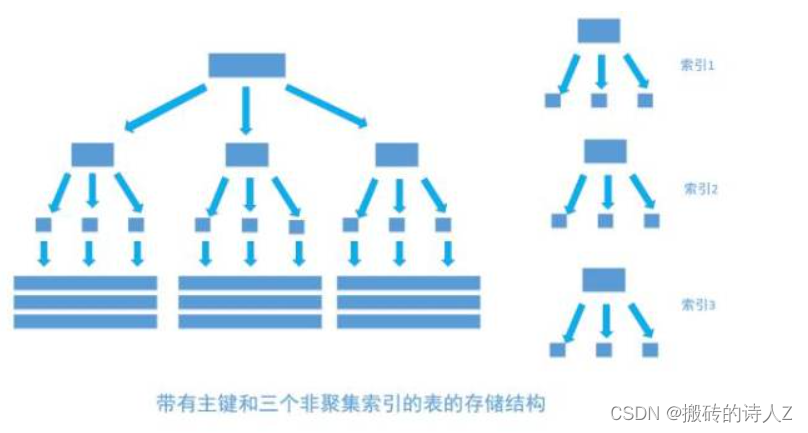
目录 InnoDB引擎MylSAM引擎聚簇索引的优点和缺点参考 聚簇索引和非聚簇索引的区别:叶节点是否存放一整行记录。 聚簇索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据。 非聚簇索引:将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置。 InnoDB主键使用的是聚簇索引,MylSAM不管是主键索引,还是二级索引(辅助键索引)都使用的都是非聚簇索引。
MySQL聚簇索引和非聚簇索引的区别
前言: 聚簇索引和非聚簇索引是数据库中的两种索引类型,他们在组织和存储数据时有不同的方式。 聚簇索引: 简单理解,就是将数据和索引放在了一起,找到了索引也就找到了数据。对于聚簇索引来说,他的非叶子节点上存储的是存储数据的值,而它的叶子节点上存储的是这条记录的整行数据。 在InnoDB中,聚簇索引是按照每张表的主键构建的一种索引方式,它是将表数据按照主键的顺序存储在磁盘上的一种方式,这
MySQL的聚簇索引和非聚簇索引的区别以及示例
MySQL的聚簇索引和非聚簇索引 聚簇索引 聚簇索引是一种索引结构,它与数据行存储在一起,即索引的叶子节点就是数据行本身。在MySQL中,主键索引就是一种典型的聚簇索引。 涉及情况 当查询需要按照主键或唯一索引进行精确查找时,会涉及到聚簇索引。 数据结构 聚簇索引的数据结构是B+树,它的叶子节点存储了完整的数据行。 速度 由于数据行和索引在一起,所以在使用聚簇索引进行查询时,速度比

Mysql的聚簇索引(聚集索引)和非聚簇索引的区别
MySQL中的索引分为两种主要类型:聚簇索引(Clustered Index)和非聚簇索引(Non-clustered Index)。这两种索引的主要区别在于它们如何组织数据和索引的方式。 聚簇索引(Clustered Index) 聚簇索引决定了数据行的物理存储顺序。也就是说,表中的数据行实际上按照聚簇索引的键值顺序存储在磁盘上。在InnoDB存储引擎中,每个表只能有一个聚簇索引,通常默认情
Mysql的聚簇索引(聚集索引)和非聚簇索引的区别
MySQL中的索引分为两种主要类型:聚簇索引(Clustered Index)和非聚簇索引(Non-clustered Index)。这两种索引的主要区别在于它们如何组织数据和索引的方式。 聚簇索引(Clustered Index) 聚簇索引决定了数据行的物理存储顺序。也就是说,表中的数据行实际上按照聚簇索引的键值顺序存储在磁盘上。在InnoDB存储引擎中,每个表只能有一个聚簇索引,通常默认情
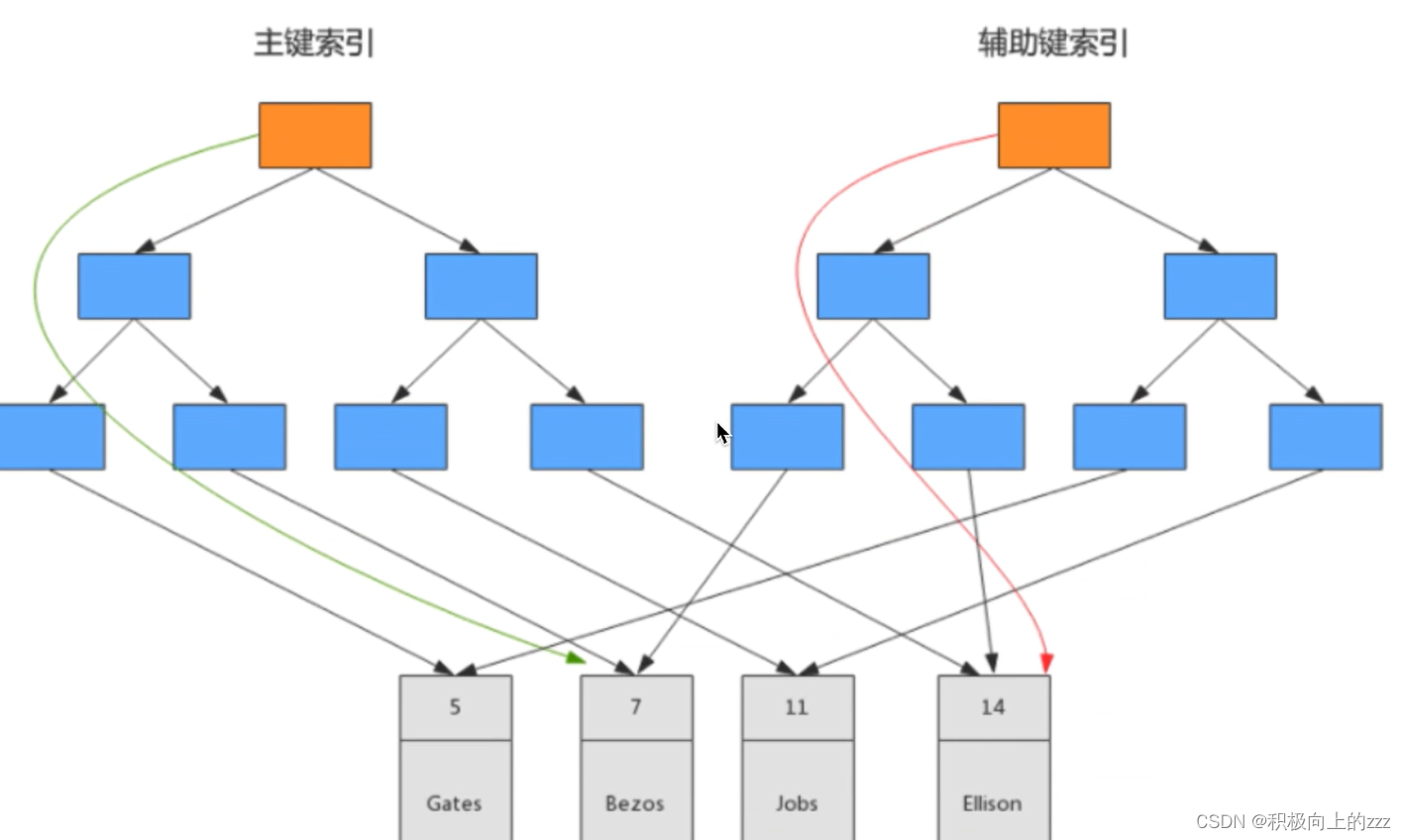
MySQL - 聚簇索引和非聚簇索引,回表查询,索引覆盖,索引下推,最左匹配原则
聚簇索引和非聚簇索引 聚簇索引和非聚簇索引是 InnoDB 里面的叫法 一张表它一定有聚簇索引,一张表只有一个聚簇索引在物理上也是连续存储的 它产生的过程如下: 表中有无有主键索引,如果有,则使用主键索引作为聚簇索引;如果没有主键索引,则看表中有无唯一索引,那么使用第一个唯一索引;如果以上两个条件都不满足,InnoDB 则会生成隐藏聚簇索引。 聚簇索引 聚簇索引一般是主键索引, 例
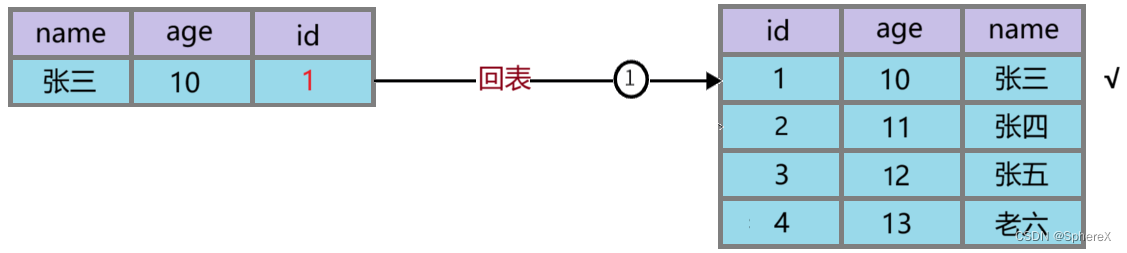
聚簇索引和非聚簇索引的区别;什么是回表
聚簇索引和非聚簇索引的区别 什么是聚簇索引?(重点) 聚簇索引就是将数据(一行一行的数据)跟索引结构放到一块,InnoDB存储引擎使用的就是聚簇索引; 注意点: 1、InnoDB使用的是聚簇索引(聚簇索引默认使用主键作为其索引),将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之
mysql索引分为哪几类,聚簇索引和非聚簇索引的区别,MySQL索引失效的情况有哪几种情况,MySQL索引优化的手段,MySQL回表
文章目录 索引分为哪几类?聚簇索引和非聚簇索引的区别什么是[聚簇索引](https://so.csdn.net/so/search?q=聚簇索引&spm=1001.2101.3001.7020)?(重点)非聚簇索引 聚簇索引和非聚簇索引的区别主要有以下几个:什么叫回表?(重点) MySQL索引失效的几种情况(重点)MySQL索引优化手段有哪些?什么叫回表?(重点)什么叫索引覆盖?(重点)

MySQL - 4种基本索引、聚簇索引和非聚索引、索引失效情况
目录 一、索引 1.1、简单介绍 1.2、索引的分类 1.2.1、主键索引 1.2.2、单值索引(单列索引、普通索引) 1.2.3、唯一索引 1.2.4、复合索引 1.2.5、复合索引经典问题 1.3、索引原理 1.3.1、主键自动排序 1.3.2、索引的底层原理 1.3.3、B 树和 B+树的区别 1.4、聚簇索引和非聚簇索引 1.4.1、innoDB 中的主键索

聚簇索引、非聚簇索引、覆盖索引 区别
目录 1、聚簇索引 优点 缺点 聚簇索引在 InnoDB 和 MyISAM 中的区别 2、非聚簇索引 3、覆盖索引 优点 应用覆盖索引 1、聚簇索引 一篇聚簇索引数据结构的文章:聚簇索引数据结构 聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。InnoDB存储引擎的聚簇索引的背后数据结构就是 B-Tree或者B-Tree的变种B+Tree。 当表有聚簇索引时,它

聚簇索引和非聚簇索引有什么区别?什么情况用聚集索引?
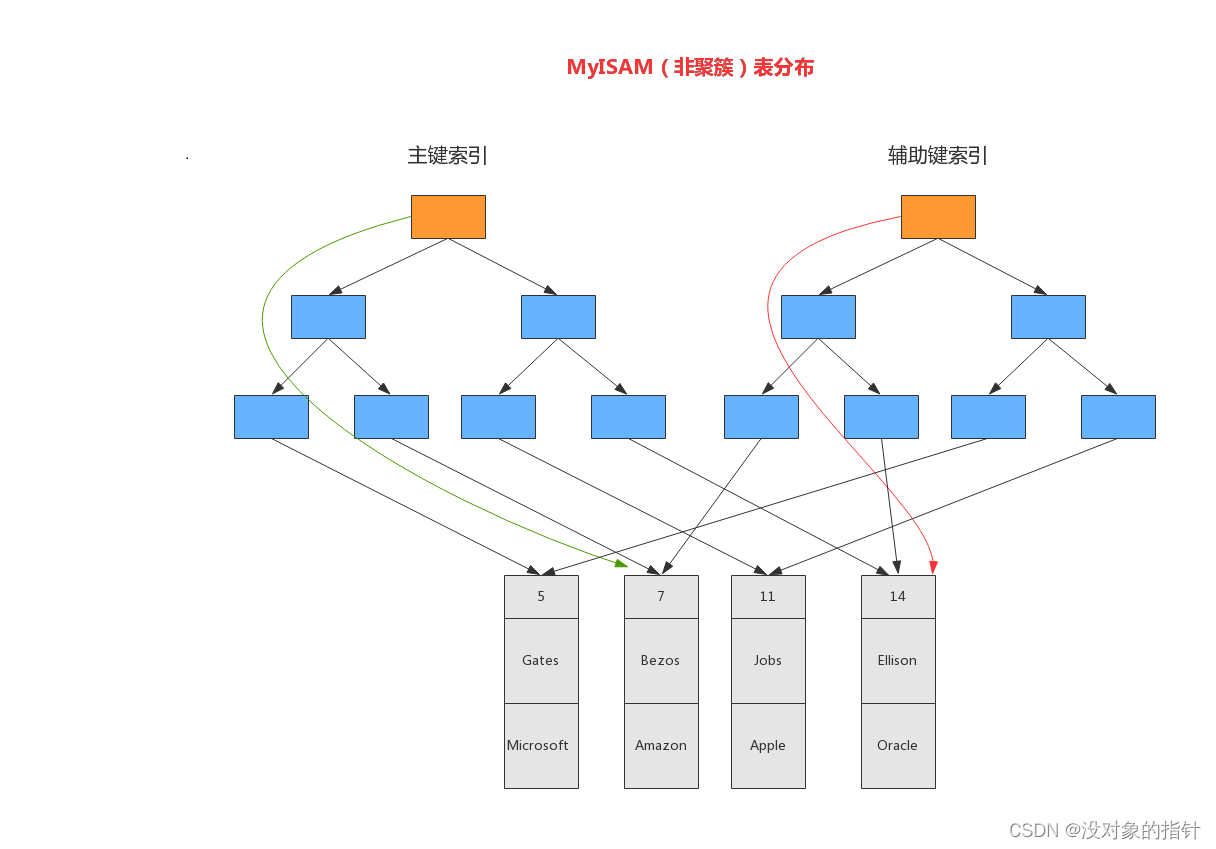
MyISAM索引实现 使用B+树 叶子节点的data域存储数据记录的地址(非聚簇索引) 主键索引与普通索引结构一样 查询数据时,首先找到data域中的地址,然后再根据地址去磁盘中读数据 图示 InnoDB的索引实现 使用B+树 主键索引叶子节点data域保存着完整的数据记录(聚簇索引) 普通索引叶子节点data域保存着主键值(非聚簇索引) 每个表只能有一个聚簇索引 主键索
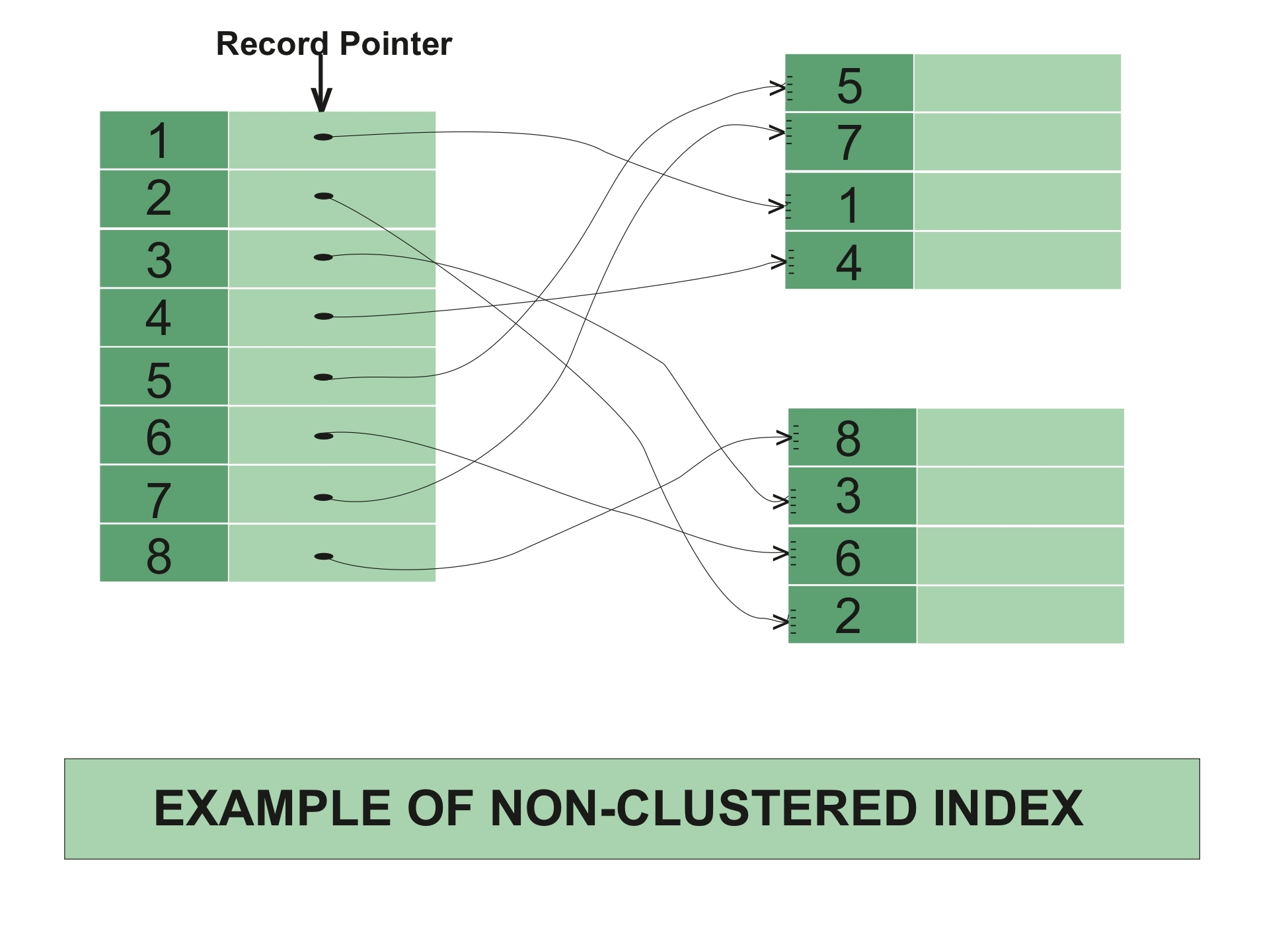
聊聊MySQL的聚簇索引和非聚簇索引
文章目录 1. 索引的分类1. 存储结构维度2. 功能维度3. 列数维度4. 存储方式维度5. 更新方式维度 2. 聚簇索引2.1 什么是聚簇索引2.2 聚簇索引的工作原理 3. 非聚簇索引(MySQL官方文档称为`Secondary Indexes`)3.1 什么是非聚簇索引3.2 非聚簇索引的工作原理 4. 聚簇索引与非聚簇索引的区别 MySQL的聚簇索引和非聚簇索引翻译