本文主要是介绍聚簇索引和非聚簇索引有什么区别?什么情况用聚集索引?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
-
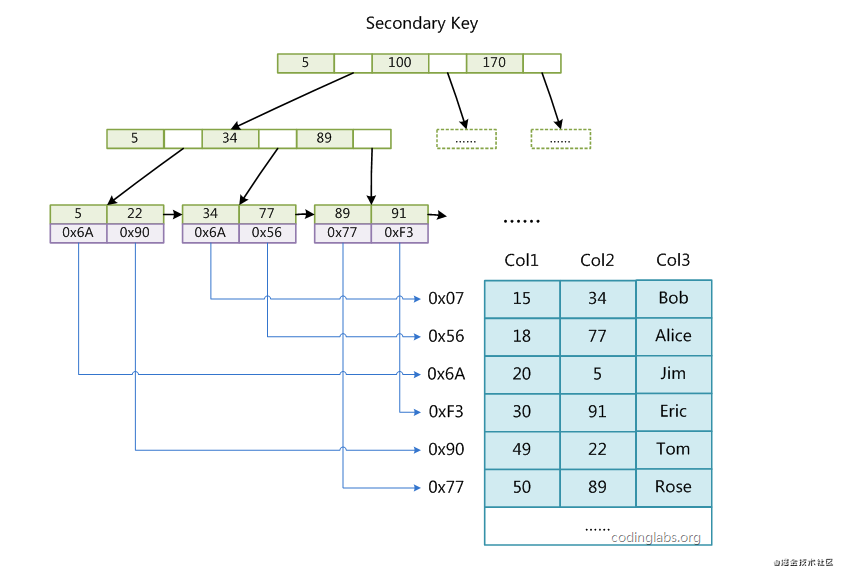
MyISAM索引实现
-
使用B+树
-
叶子节点的data域存储数据记录的地址(非聚簇索引)
-
主键索引与普通索引结构一样
-
查询数据时,首先找到data域中的地址,然后再根据地址去磁盘中读数据
-
图示
-
-
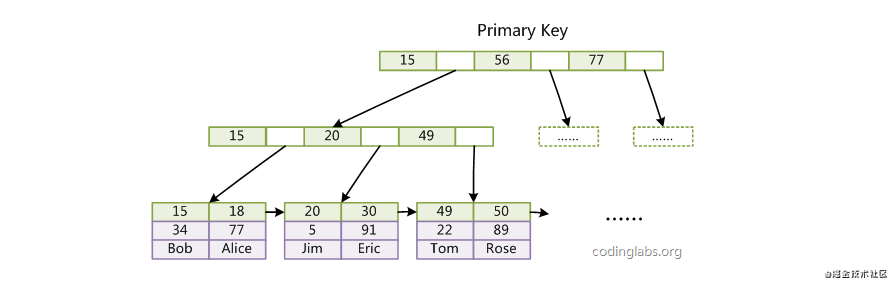
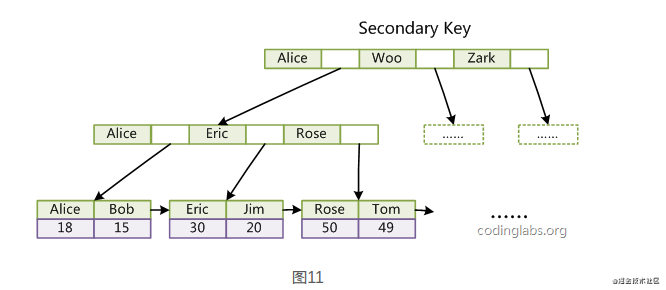
InnoDB的索引实现
-
使用B+树
-
主键索引叶子节点data域保存着完整的数据记录(聚簇索引)
-
普通索引叶子节点data域保存着主键值(非聚簇索引)
-
每个表只能有一个聚簇索引
-
主键索引查询数据,只需根据主键值拿到叶子节点中data域的数据即可。而对于普通索引查询数据时,首先找到叶子节点data域中的主键值,然后再去主键索引中根据主键值去查数据。
-
图示
-
主键索引
-
辅助索引
-
-
聚簇索引与非聚簇索引定义
叶子节点data域保存完整数据记录的就是聚簇索引,叶子节点data域只保存主键值或数据地址的就是非聚簇索引
-
什么是回表
通过辅助索引查询到主键值后,再拿主键值去主键索引中查找数据的过程就叫做回表
-
什么是索引覆盖
- 当sql语句中的select列(查询的字段)和where列(条件字段)都在一个索引中,则不需要进行回表,这就是索引覆盖。
- 例如:select id, name from users where name = 'jack'; (对name建立辅助索引)。这个示例中由于对name字段建立辅助索引,而辅助索引每个叶子节点的data域保存主键值,则不需要进行回表操作,即可拿到id和name。
- 所有不需要回表的查询操作都是索引覆盖。
- 可利用索引覆盖来减少IO操作,从而提高查询效率。比如select id, name,age from users where name = 'jack'; 可对name和age建立联合索引,从而避免回表。
-
为什么尽量使用短的字段作为索引
- 由于每个B+树的节点大小是固定的,过大的字段会导致每个节点存储的key数量表少,从而使树的层级变高,增加IO消耗
- 如果使用长的字段作为主键,则也会使辅助索引占用空间变大,因为辅助索引叶子节点data域存储的是主键值
-
为什么尽量使用单调递增的字段作为主键
非单调的主键会使在插入新数据时,为了维护B+树的特性而频繁的分裂调整,十分低效。
-
如果没有设置主键,innodb会怎么处理?
- 如果表定义了主键,则会以这个主键作为key,进行构建聚簇索引
- 如果没有定义主键,则会选择一个唯一索引作为key,进行构建聚簇索引
- 如果没有主键也没有唯一索引,那么就会创建一个隐藏的row-id作为key,进行构建聚簇索引。
更多精彩请关注公众号(持续更新中)

-
这篇关于聚簇索引和非聚簇索引有什么区别?什么情况用聚集索引?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





