聚簇专题

聚簇索引和非聚簇索引(相关小知识点)
前言 终于有时间写写博客,记录下聚簇索引与非聚簇索引的相关小知识点。 知识点 1、聚簇索引和非聚簇索引的各自适用场景? 2、聚簇索引和非聚簇索引的优劣势? 优势: 叶子节点会存储数据,找到叶子节点就找到了数据行,无需回表; 对于辅助索引,使用主键作为指针而不是地址值,,减少了出现行移动或者数据页分裂时辅助索引的维护工作; 在排序场景下,由于聚簇索引的物理位置和数据行的逻辑位置

【面试题】MySQL的聚簇索引与非聚簇索引与主键索引:深入理解与应用
文章目录 引言基础知识核心概念引擎上的区别InnoDBMyISAM 示例演示实际应用深入与最佳实践常见问题解答结语学习资源互动环节 引言 聚簇索引、非聚簇索引和主键索引的有什么区别你知道吗 在数据库设计中,索引是提高查询性能的关键。MySQL中的聚簇索引和非聚簇索引是两种不同的索引类型,它们在数据存储和检索方面有着显著的差异。理解这些差异对于优化数据库性能至关重要。 基

哈希表的应用-浅析顶点聚簇网格简化算法的实现
前言 本篇接顶点去重那一篇,继续使用哈希表来实现网格算法。这次介绍的是一种比较简单的网格简化算法,叫做顶点聚簇。 网格简化 为了介绍这个算法,首先说明一下网格简化算法。随着计算机绘图在现代科技领域中的广泛应用, 计算机图形在现代制造业中发挥着重要的作用。计算机图形学中对模型的要求更加精密, 也更加复杂, 生成的面片数也更加庞大, 庞大的数据量必然对计算机的计算能力提出
sql优化之利用聚簇索引减少回表次数:limit 100000,10
1. 问题描述 产品:我要对订单列表页做一个分页功能,每页10条数据,商家可以根据金额过滤订单 技术:好的,我写一个sql实现分页,x表示偏移页数,自测limit 10,10耗时200ms: SELECT * FROM `order` WHERE `amount` > 0 limit x,10; 功能演示时,产品点击第1000万页,页面因为接口超时空白,查看sql耗时10000ms 技术
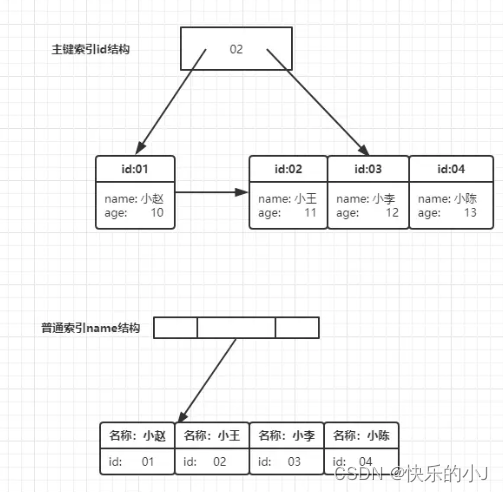
MySQL索引(聚簇索引、非聚簇索引)
了解MySQL索引详细,本文只做整理归纳:https://blog.csdn.net/wangfeijiu/article/details/113409719 概念 索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。 索引分类 主键索引:primary key 设定为主键后,数据库自动建立索引,InnoDB为聚簇索引,主键索引列值不能为空(Null

数据库聚簇索引和非聚簇索引的区别
聚簇索引(Clustered Index)和非聚簇索引(Non-clustered Index)是数据库中两种不同的索引类型,它们的主要区别在于数据的存储方式和索引的结构: 数据存储方式: 聚簇索引:索引的叶子节点存储的是数据行本身,而不是指向数据行的指针。换句话说,聚簇索引决定了数据的物理存储顺序,因此表中的数据行实际上是按照聚簇索引的顺序存储的。 非聚簇索引:索引的叶子节点存储的是
![[MySQL] innoDB引擎的主键与聚簇索引](/front/images/it_default.gif)
[MySQL] innoDB引擎的主键与聚簇索引
mysql的innodb引擎本身存储的形式就必须是聚簇索引的形式 , 在磁盘上树状存储的 , 但是不一定是根据主键聚簇的 , 有三种情形: 1. 有主键的情况下 , 主键就是聚簇索引 2. 没有主键的情况下 , 第一个非空null的唯一索引就是聚簇索引 3. 如果上面都没有 , 那么就是有一个隐藏的row-id作为聚簇索引 大部分情况下 , 我们建表的时候都会创建主键 , 因此大部分都是根据

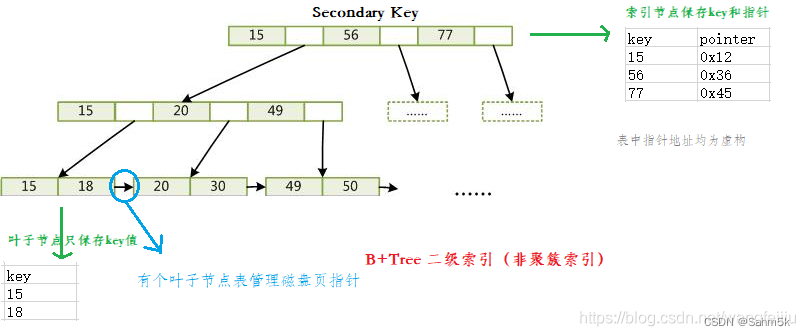
B+树以及非聚簇索引和聚簇索引
1 B树以及B+树 1.1 B树 是一种多路搜索树,假设为M叉树 1. 每个节点中的关键字,比指向儿子的指针少一,即每个节点最多有M-1个关键字和M个指针 2. 关键字集合分布在整棵树中,任何一个关键字出现且只出现在一个节点中,即是说,有可能在非叶子节点命中。 1.2 B+树 B+树是B树的变种,也是一种多路搜索树,假设为M叉树 1. 每个节点的关键字个数和指向儿子的指针
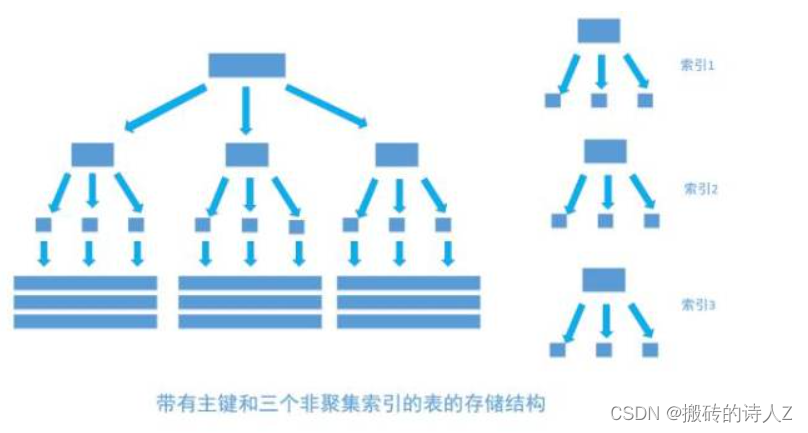
MySQL - 聚簇索引和非聚簇索引
1. 聚簇索引 聚簇索引是一种数据存储方式:在 InnoDB 中,聚簇索引是通过将表的数据存储在按照索引键值排序的 B+ 树结构中来实现的。 B+Tree 的叶子节点就是行记录,行记录和主键值紧凑地存储在一起, 这也意味着 InnoDB 的主键索引就是数据表本身,它按主键顺序存放了整张表的数据,占用的空间就是整个表数据量的大小。通常说的主键索引就是聚集索引。 InnoDB 的表要求必须要有聚簇
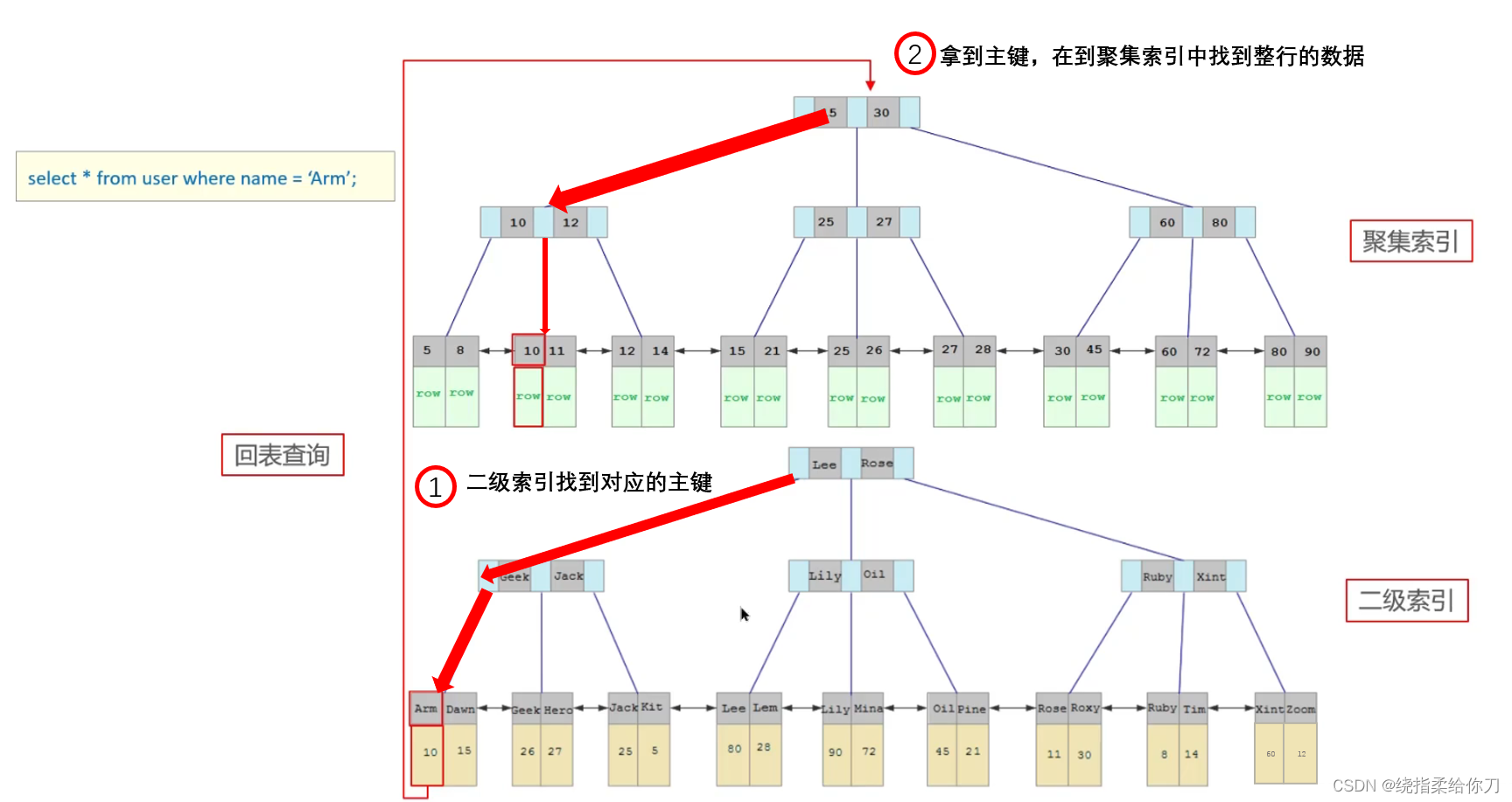
MySQL--优化(索引--聚簇和非聚簇索引)
MySQL–优化(索引–聚簇和非聚簇索引) 定位慢查询SQL执行计划索引 存储引擎索引底层数据结构聚簇和非聚簇索引索引创建原则索引失效场景 SQL优化经验 一、聚簇索引 聚簇索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据特点:必须有,而且只有一个 聚簇索引在 B+树中的数据结构 二、非聚簇索引(二级索引) 非聚簇索引(二级索引):将数据与索引分开存储,索
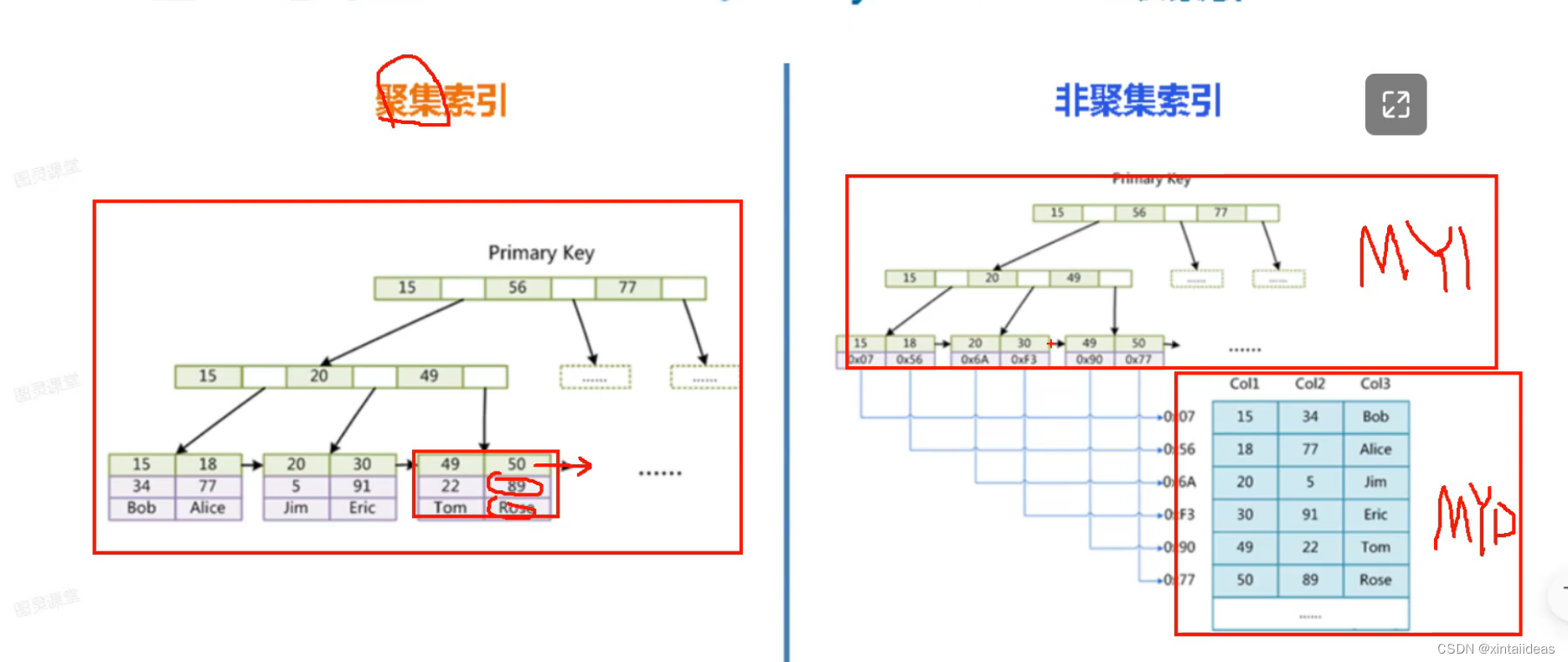
什么是聚簇索引与非聚集索引和区别?
什么是聚簇索引与非聚集索引和区别? 按物理存储分类:InnoDB的存储方式是聚集索引,MVISAM的存储方式是非聚集索引 test innodb.frm 测试 innodb.ibd Frame=表结构 数据表索引+数据 test myisam.frm ---->Frame=表结构test myisam.MYD_---数据=表数据test_myisam.MYl----MyISAM Index=表索引

【MySQL】数据库索引详解 | 聚簇索引 | 最左匹配原则 | 索引的优缺点
创作不易,本篇文章如果帮助到了你,还请点赞 关注支持一下♡>𖥦<)!! 主页专栏有更多知识,如有疑问欢迎大家指正讨论,共同进步! 🔥c++系列专栏:C/C++零基础到精通 🔥 给大家跳段街舞感谢支持!ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ 目录 索引概述索引的使用 为什么不使用 AVL、 红黑树作为索引?为什么不使用哈希作为索引?B
oracle行预取(raw prefecting)和聚簇因子(clustering_factor)
oracle行预取(raw prefecting)和聚簇因子(clustering_factor) 转自:行预取(raw prefecting)和聚簇因子(clustering_factor) 背景介绍 行预取: 每次应用程序请求驱动从数据库返回1条记录的时候,会预取多条记录并将它们存储在客户端的内存中。这样,多个连续的请求就不需要执行数据库的调用来读取数据。可以直接从客户端内存中得到他们
聚簇索引、非聚簇索引、回表、索引下推、覆盖索引
聚簇索引(主键索引) 非叶子节点上存储的是索引值,叶子节点上存储的是整行记录。 非聚簇索引(非主键索引、二级索引) 非叶子节点上存储的都是索引值,叶子节点上存储的是主键的值。非聚簇索引需要回表,IO消耗。 回表 非聚簇索引先执行一次主键查询,再通过适配的主键的值之后,再进行一次二级索引,这个过程就是回表。 覆盖索引 一次索引就可以得到数据,无需回表。覆盖索引发生在联合索引,where

聚簇索引、回表与覆盖索引
聚簇索引一般指的是主键索引(如果存在主键索引的话)。 作为一个正常开发,建表时主键肯定是必须的。 而即使如果表中没有定义主键,InnoDB 会隐式选择一个唯一的非空索引代替。 所以我们就直接含糊点说: 聚簇索引就是主键索引!其余的都是非聚簇索引。 那到底什么是聚簇索引,什么是非聚簇索引? 聚簇就是扎一堆儿。 聚簇索引就是将数据存储与索引放到了一块,找到索引也就找到了数据。 在
聚簇索引的效率明显要低于非聚簇索引,为什么还需要聚簇索引?
每次使用辅助索引检索都要经过两次B+树查找,看上去聚簇索引的效率明显要低于非聚簇索引,这不是多此一举吗?聚簇索引的优势在哪? 由于行数据和聚簇索引的叶子节点存储在一起,同一页中会有多条行数据,访问同一数据页不同行记录时,已经把页加载到了Buffer中(缓冲池), 再次访问时,会在内存中完成访问,不必访问磁盘。这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了, 如果按照主
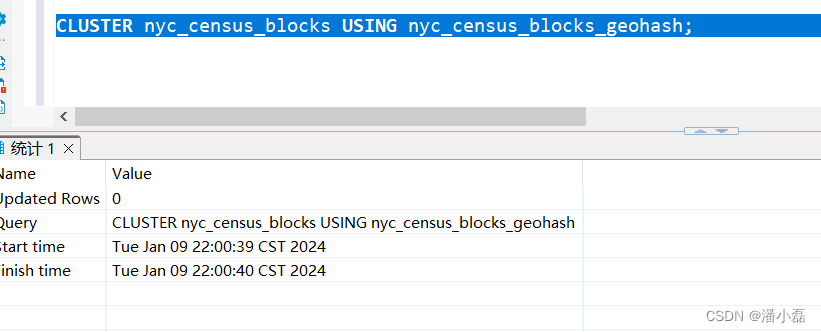
PostGIS教程学习十九:基于索引的聚簇
PostGIS教程学习十九:基于索引的聚簇 数据库只能以从磁盘获取信息的速度检索信息。小型数据库将完全位于于RAM缓存(内存),并摆脱物理磁盘访问速度慢的限制。但是对于大型数据库,对物理磁盘的访问将限制数据库的信息检索速度。 数据是偶尔写入磁盘的,因此存储在磁盘上的有序数据与应用程序访问或组织该数据的方式之间不需要存在任何关联。 加速数据访问的一种方法是确保可能在同一结果集中一起被检索的记录
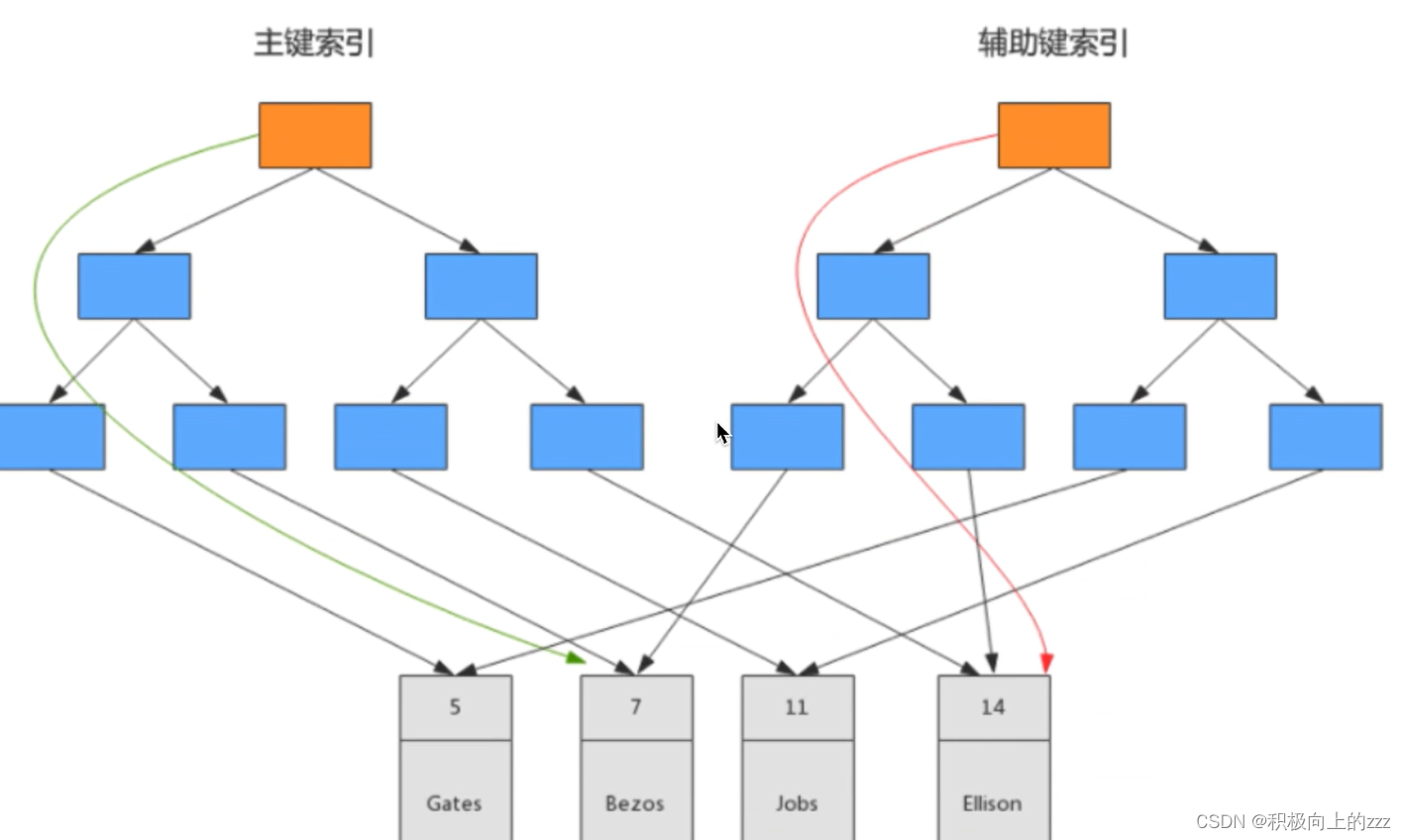
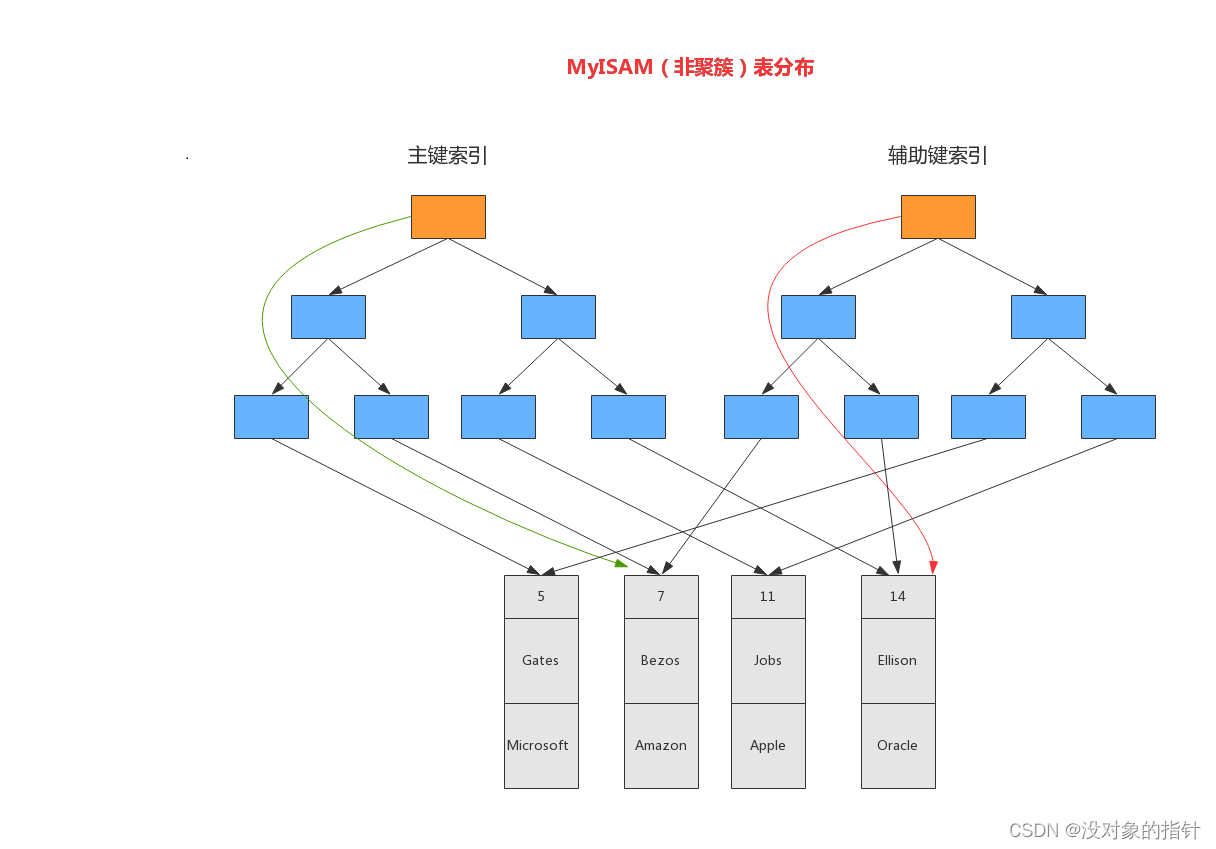
mysql聚簇索引和非聚簇索引
目录 InnoDB引擎MylSAM引擎聚簇索引的优点和缺点参考 聚簇索引和非聚簇索引的区别:叶节点是否存放一整行记录。 聚簇索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据。 非聚簇索引:将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置。 InnoDB主键使用的是聚簇索引,MylSAM不管是主键索引,还是二级索引(辅助键索引)都使用的都是非聚簇索引。
MySQL聚簇索引和非聚簇索引的区别
前言: 聚簇索引和非聚簇索引是数据库中的两种索引类型,他们在组织和存储数据时有不同的方式。 聚簇索引: 简单理解,就是将数据和索引放在了一起,找到了索引也就找到了数据。对于聚簇索引来说,他的非叶子节点上存储的是存储数据的值,而它的叶子节点上存储的是这条记录的整行数据。 在InnoDB中,聚簇索引是按照每张表的主键构建的一种索引方式,它是将表数据按照主键的顺序存储在磁盘上的一种方式,这
MySQL的聚簇索引和非聚簇索引的区别以及示例
MySQL的聚簇索引和非聚簇索引 聚簇索引 聚簇索引是一种索引结构,它与数据行存储在一起,即索引的叶子节点就是数据行本身。在MySQL中,主键索引就是一种典型的聚簇索引。 涉及情况 当查询需要按照主键或唯一索引进行精确查找时,会涉及到聚簇索引。 数据结构 聚簇索引的数据结构是B+树,它的叶子节点存储了完整的数据行。 速度 由于数据行和索引在一起,所以在使用聚簇索引进行查询时,速度比
Mysql的聚簇索引(聚集索引)和非聚簇索引的区别
MySQL中的索引分为两种主要类型:聚簇索引(Clustered Index)和非聚簇索引(Non-clustered Index)。这两种索引的主要区别在于它们如何组织数据和索引的方式。 聚簇索引(Clustered Index) 聚簇索引决定了数据行的物理存储顺序。也就是说,表中的数据行实际上按照聚簇索引的键值顺序存储在磁盘上。在InnoDB存储引擎中,每个表只能有一个聚簇索引,通常默认情

Mysql的聚簇索引(聚集索引)和非聚簇索引的区别
MySQL中的索引分为两种主要类型:聚簇索引(Clustered Index)和非聚簇索引(Non-clustered Index)。这两种索引的主要区别在于它们如何组织数据和索引的方式。 聚簇索引(Clustered Index) 聚簇索引决定了数据行的物理存储顺序。也就是说,表中的数据行实际上按照聚簇索引的键值顺序存储在磁盘上。在InnoDB存储引擎中,每个表只能有一个聚簇索引,通常默认情
索引基本功 聚簇索引与非聚簇索引区别,各种索引的区别
和刚入门的菜鸟们聊聊--什么是聚簇索引与非聚簇索引 https://www.cnblogs.com/auxg/p/Cluster-and-NonCluster-index.html 今天我们来聊一聊关于 聚簇索引和非聚簇索引的问题; 刚开始学数据库SQL的时候,就知道有主键啊(Primary-key),外键啊(Foreign-key)啥的,连个表查询就已经不清楚是要on 那几个字
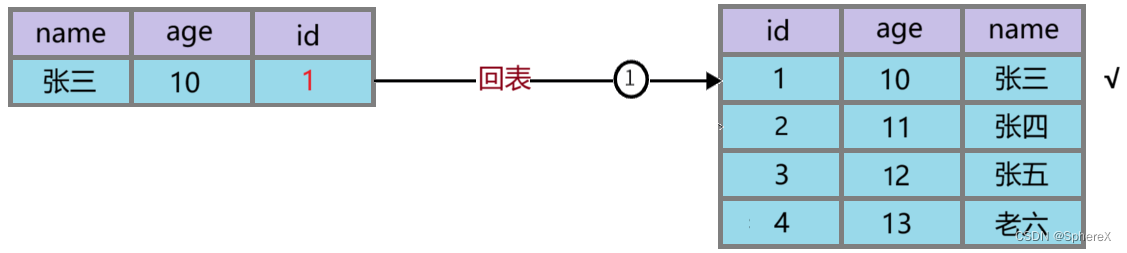
MySQL - 聚簇索引和非聚簇索引,回表查询,索引覆盖,索引下推,最左匹配原则
聚簇索引和非聚簇索引 聚簇索引和非聚簇索引是 InnoDB 里面的叫法 一张表它一定有聚簇索引,一张表只有一个聚簇索引在物理上也是连续存储的 它产生的过程如下: 表中有无有主键索引,如果有,则使用主键索引作为聚簇索引;如果没有主键索引,则看表中有无唯一索引,那么使用第一个唯一索引;如果以上两个条件都不满足,InnoDB 则会生成隐藏聚簇索引。 聚簇索引 聚簇索引一般是主键索引, 例
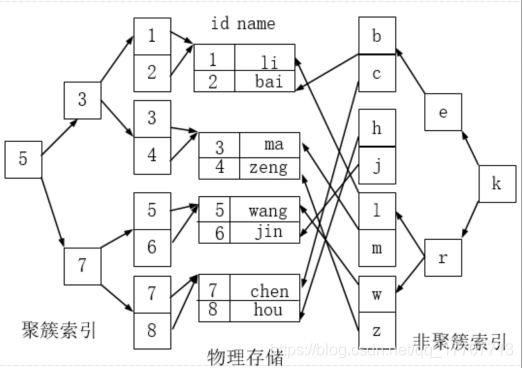
聚簇索引、全文索引与哈希索引
(1)、聚簇索引 聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。 术语“聚簇”表示数据行和相邻的键值进错的存储在一起。 如下图,左侧的索引就是聚簇索引,因为数据行在磁盘的排列和索引排序保持一致。 聚簇索引的好处: 按照聚簇索引排列顺序,查询显示一定范围数据的时候,由于数据都是紧密相连,数据库不用从多个数据块中提取数据,所以节省了大量的io操作。 聚簇索引的限制: 对于m