本文主要是介绍MySQL - 4种基本索引、聚簇索引和非聚索引、索引失效情况,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、索引
1.1、简单介绍
1.2、索引的分类
1.2.1、主键索引
1.2.2、单值索引(单列索引、普通索引)
1.2.3、唯一索引
1.2.4、复合索引
1.2.5、复合索引经典问题
1.3、索引原理
1.3.1、主键自动排序
1.3.2、索引的底层原理
1.3.3、B 树和 B+树的区别
1.4、聚簇索引和非聚簇索引
1.4.1、innoDB 中的主键索引
1.4.2、使用聚簇索引的优势
1.4.3、使用聚簇索引需要注意什么
1.4.4、为什么主键通常建议使用自增 id
1.5、索引失效的场景
一、索引
1.1、简单介绍
索引就是一种帮助 mysql 提高查询效率的数据结构.
优点:
- 大大增加了查询速度.
缺点:
- 索引实际上是一张表,因此需要消耗一部分空间资源.
- 对表中的数据进行增删改的时候,需要更新索引,因此速度会受到一定影响.
1.2、索引的分类
1.2.1、主键索引
实际上就是我们创建数据库时指定的主键(主键索引值不能为空、不能重复.),会自动创建索引,叫做 “主键索引”,在 innodb 引擎中就是所谓的 “聚簇索引”.
例如,以 id 为主键建表
create table user(id int PRIMARY KEY, name varchar(20), age int);然后通过以下命令查看 user 表的索引
show index from user;
1.2.2、单值索引(单列索引、普通索引)
就是为表中的某一列创建的索引,一个表中可以有多个单列索引.
例如,表中有字段 id、name、age,那么为 其中的 name 创建一个索引,就叫单列索引.
创建方式有以下两种:
a)建表时创建(注意,这种方式创建,索引名和字段名一致)
# 给 name 单独创建索引
create table user(id int primary key, name varchar(20), age int, key(name));# 给 name 和 age 分别创建索引
create table user(id int primary key, name varchar(20), age int, key(name), key(age));

b)建表后创建
create table user(id int primary key, name varchar(20), age int);create index index_name on user(name);

c)删除索引
drop index 索引名 on 表明
1.2.3、唯一索引
在创建表的时候,有时候我们会通过 unique 指定某个字段唯一,这个时候就会创建唯一索引.
Ps:允许有 null 值,并且可以有多个.
创建方式有以下两种:
a)建表时指定
# 第一种写法
create table user(id int primary key, name varchar(20) unique, age int);# 第二种写法
create table user(id int primary key, name varchar(20), age int, unique(name));

b)建表后创建
create unique index index_name on user(name);

1.2.4、复合索引
就是我们为表中的多个字段一起创建一个索引.
Ps:查询时,在 where 条件后,必须要使用 and 连接复合索引字段,否则不生效.
创建方式有以下两种:
a)建表时创建
create table user(id int primary key, name varchar(20), age int, key(name, age));

b)建表后创建
create index name_age_index on user(name, age);

1.2.5、复合索引经典问题
问题:有一个用户表,给 name、age、gender 三个字段创建了一个复合索引 key(name, age, gender),以下场景,哪种查询索引会生效?
以下是 where 查询后通过 and 拼接的字段.
- name 生效
- name age 生效
- name age gender 生效
- name gender age 生效
- age gender 失效
- gender 失效
- gender age name 生效
该怎么判断呢?符合索引生效只要满足以下任意一个原则即可:
- 最左前缀元组:必须包含做前缀,也就意味着 name、 name age、name age gender 是生效的.
- mysql 引擎为了更好的利用索引,在查询过程中会动态调整查询字段顺序,便于利用索引,也就意味着只要包含所有索引字段即可(任意的组合都可以).
1.3、索引原理
1.3.1、主键自动排序
当我创建一个 user 表(含主键 id),然后按照无序 id 的方式插入数据,会发现查询结果尽然按照 主键 id 排序了

为什么会进行排序呢?
排序之后相对来说,查询更快. 例如有 10 个自增 id,现在查询 id = 3 的,那么只需要向下对比三次即可得到,而对于无序数据来说每次都需要遍历一遍数据才能得到.
这也就说明为啥主键不建议使用 uuid 去建立,而是使用 int 类型?因为在主键建立索引的时候,会先根据表中的主键去排序,排序后在查询效率会更高.
1.3.2、索引的底层原理
假设有如下表和信息

索引的数据结构就是一个 b+ 树,原理如下
a)排序,形成链表:表中的每一条数据组织成一个链表中的一个节点,结构由三部分构成:“主键 + 数据 + 指针”,数据就是表中的非主键索引字段(name, age),指针就是用来指向下一个节点,这些节点会现经过主键 id 的排序,最后组织成一个链表的结构,得到b+树的叶子节点 如下
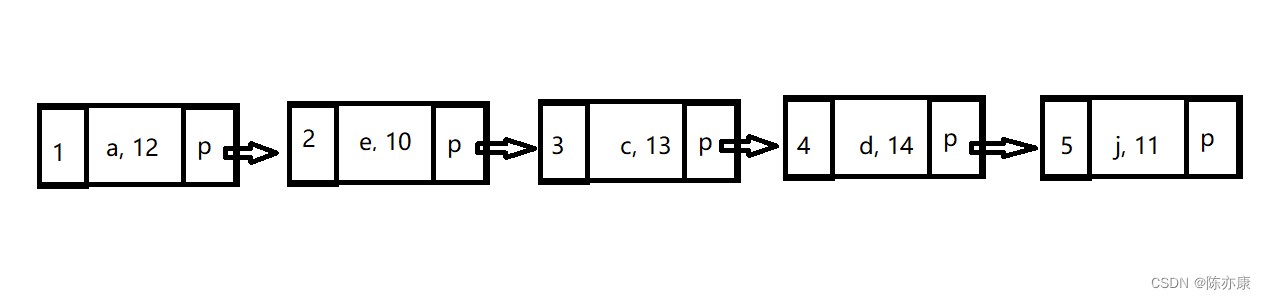
b)页管理:将链表进行分页管理,每一页的大小默认存储 16kb,假设如下图(真实情况一页存放的数据有很多).

c)页目录管理:将每一页最左边节点的主键 和 指针 拿出来存放到页目录中,页目录的默认大小也是 16kb
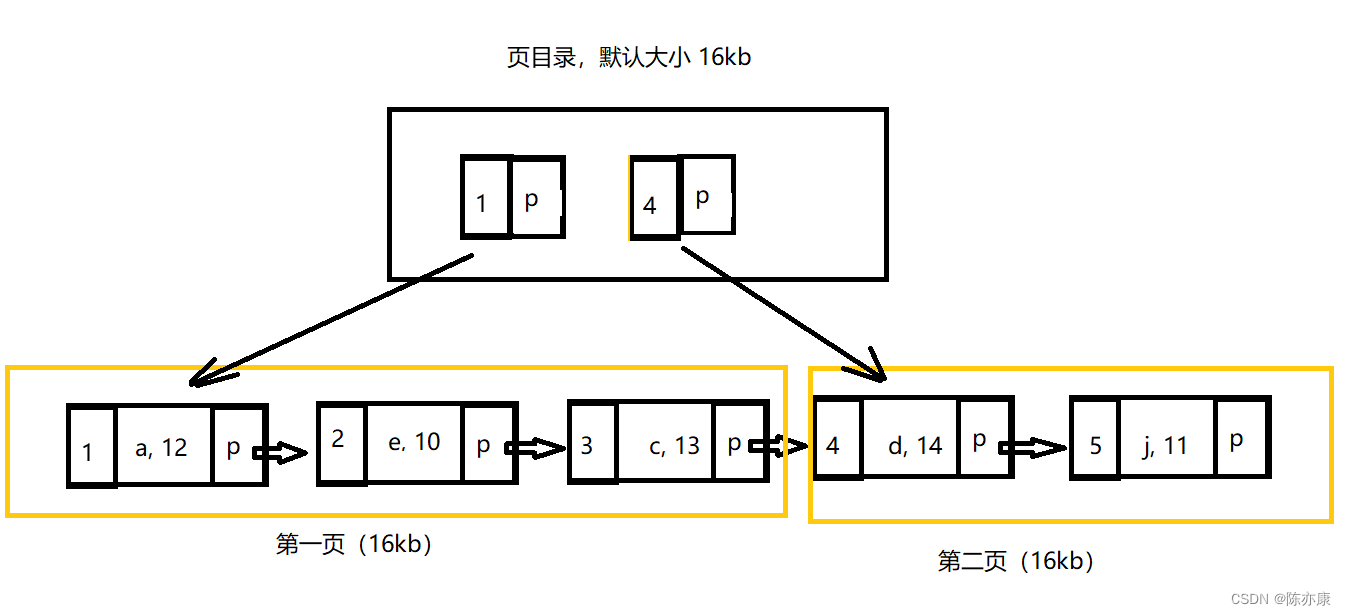
d)如果页目录的大小占满了,那么可能还会继续向上生成页目录(父节点),不过一般开发存储的数据,树的高度都不会超过 4 的,也就是说,当需要查找某一数据时,最多只需要 1~3 次 I/O 操作(注意:顶层的根节点时在内存中的).
1.3.3、B 树和 B+树的区别
B+ 树相当于是在 B 上的一种优化,主要区别如下:
- B+ 树非叶子节点只存储键值对信息,B 树 data 数据也需要存储,而每一页的存储空间是有限的(默认 16 kb),那么如果 data 数据较大时,每个节点能存储的 key 就很少,进而导致树的深度较大,增大了查询时的磁盘 IO 次数(每一层都进行一次 IO).
- B+ 树的叶子节点保存全集数据,是一个链表结构,而非叶子节点只存储 key,大大增加了非叶子节点存储 key 的数量,降低了树高.
1.4、聚簇索引和非聚簇索引
1.4.1、innoDB 中的主键索引
聚簇索引:由 主键索引 和 辅助索引 构成.
主键索引:主键索引中,叶子节点保存表中每一行的所有数据,当需要查找例如 where Id = 14,就会去主键索引 B+ 树上找到的叶子节点,然后获取行数据.
Ps:如果没有定义主键,就会选择唯一且非空的索引代替,如果非空索引也没有,就会自己隐式定义一个主键作为聚簇索引
辅助索引(innoDB 中的非聚簇索引就是辅助索引):就是在聚簇索引之上建立的索引,一般来说就是表中给其他字段建立的索引(非主键索引),也就是 复合索引、单列索引、唯一索引,并且的叶子节点存储的不再是行物理地址,而是主键值,因此辅助索引最少需要二次查询才能找到数据,例如 where name='cyk',步骤如下
- 在辅助索引 B+ 树种检索 name,然后到达叶子节点获取对应的主键.
- 根据主键在聚簇索引 B+ 树种在及进行一次检索操作,最终到达叶子节点获取整行数据.

非聚簇索引:在 myisam 使用的是非聚簇索引,也由两颗 B+ 树构成(主键索引、辅助索引),主键索引B+树节点存储了主键,辅助索引 B+ 树种存储了辅助键. 叶子节点都是用一个地址指向真正的表的数据,因此辅助键无需像 innoDB 一样访问主键索引树.

1.4.2、使用聚簇索引的优势
问题:每次使用辅助索引检索都需要经过两次 B+ 树查询,看上去聚簇索引的效率明显低于非聚簇索引,这不是多此一举么,聚簇索引优势在哪?
- 访问同一数据也不同记录时,会把页加载到缓存中,再次访问的时候,会在内存中完成访问,不必访问磁盘,而主键和数据又是一起被载入内存的,因此按照主键 id 来组织数据(排好序的),获取更快.
- innoDB 中的辅助索引叶子节点存储主键值,而不是物理地址,因此当行数据发生改变时(对表进行增删改),叶子节点也无需像 myisam 非聚簇索引的辅助索引一样改变地址,只需要维护索引树即可.
- innoDB 中的辅助索引叶子节点存放的是主键值,而 myisam 中存储的是物理地址,因此空间占用更小.
1.4.3、使用聚簇索引需要注意什么
主键最好不要使用 uuid,因为 uuid 值过于离散,不适合排序,并且有可能生成的 uuid 插入在索引树的中间位置,导致树调整复杂度变大,查询时消耗更多的时间.
建议使用 int 或者 bigint 类型的自增,方便排序并且默认会在索引树的末尾增加主键值,对索引树的结构影响最小.
1.4.4、为什么主键通常建议使用自增 id
聚簇索引的数据物理地址存放顺序和索引主键 id 顺序时一致的,因此索引是相邻的,对应的数据也是在相邻的磁盘上. 如果主键不是自增 id,那么会不断调整数据的物理地址,来进行分页. 如果是自增,就只要一页一页写,磁盘碎片也就少了.
1.5、索引失效的场景
1. 查询语句中使用 like 关键字,如果匹配字符串的第一个字符为 "%",索引不会被使用;如果 "%" 不是在第一个位置,索引就会被使用.
2. 查询语句中使用复合索引,需要满足匹配原则才可以(上面讲到过了)。
3. 查询语句中使用 or 关键字时,如果 or 前后的两个条件都是索引,那么就会使用索引,如果任意一个不是索引,那么查询中不使用索引.

这篇关于MySQL - 4种基本索引、聚簇索引和非聚索引、索引失效情况的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




