金字塔专题

c/c++的opencv图像金字塔缩放实现
《c/c++的opencv图像金字塔缩放实现》本文主要介绍了c/c++的opencv图像金字塔缩放实现,通过对原始图像进行连续的下采样或上采样操作,生成一系列不同分辨率的图像,具有一定的参考价值,感兴... 目录图像金字塔简介图像下采样 (cv::pyrDown)图像上采样 (cv::pyrUp)C++ O

以人口金字塔图为例,在线绘制左右双侧堆叠条形图
导读: 人口金字塔(population pyramids)用于展示一个特定人口的年龄和性别分布。本质上是一种水平条形图。左侧是男性的数据,右侧是女性的数据。 Proc Natl Acad Sci U S A.文章《Demographic change and assimilation in the early 21st-century United States》fig 1的人口金字

PMP–知识卡片--SCQA金字塔表达
SCQA模型通过四个关键元素:情景+冲突+疑问+答案,建立了一个精确而有逻辑的表达框架。同时,它也能够帮助你构建合理的逻辑链条,让别人更容易理解和接受你的观点。 情景:通过描述背景和现状引入话题,这个元素帮助别人了解你要讨论的具体情况,并为接下来的表达打下基础。 冲突:介绍完情景之后,引入一个核心问题、挑战或者冲突,以激起别人的兴趣和好奇心。 疑问:在抛出冲突之后,引出一个明确的问题,这个问题将激


OpenCV中使用金字塔LK光流法(上)
有关金字塔LK光流法的原理,可参考这篇文章金字塔LK光流法数学原理学习笔记_lk光流 论文-CSDN博客。这里我们讲解OpenCV中实现的金字塔LK光流法的相关API,并通过一个demo来学习如何使用它。 首先介绍一些API,它们是光流法流程中会用到的功能函数,之后再介绍calcOpticalFlowPyrLK()。 1. cornerHarris() vo

CV-笔记-重读特征金字塔网络 (FPN)
目录 结构实现细节基于特征金字塔(FPN)的RPN打labelFPN的ROI pooling参数细节Region Proposal with RPNObject Detection with Fast/Faster R-CNN 对于网络的卷积特征的几个重要理解: 但由于深度不同,导致了不同层较大的语义差异。高分辨率图的低层特征损害了其对目标识别的表征能力。语义差异:语义差异就


seo网站优化的金字塔模型
我相信很多学习SEO的朋友都曾经看到过SEO金字塔模型,肯定也了解了SEO金字塔包含的细致工作。但是随着搜索引擎的不断发展,尤其在国内百度算法频频更新的情况下,我们如果仍然按照最初的意思去做SEO的话,那么我相信这条理论依然对我们有所帮助,但是作用已经大不如前了。 看到这个理论的时候,是偶然买了一本关于SEO的书《SEO网站营销推广全程实例》在书中的第一章的一个提示处,标注出来了这

2-1基于matlab的拉普拉斯金字塔图像融合算法
基于matlab的拉普拉斯金字塔图像融合算法,可以使部分图像模糊的图片清楚,也可以使图像增强。程序已调通,可直接运行。 2-1 图像融合 拉普拉斯金字塔图像融合 - 小红书 (xiaohongshu.com)
计算机图形学 -- 变换之旋转一 [金字塔旋转] [各种详解哦]
OpenGL之变换 这一次用到的有双缓冲、双缓存技术,空闲调用函数,激活函数(启用功能),平移和旋转等 Code: #include<GL/glut.h>#include<stdlib.h>#pragma comment(linker,"/subsystem:\"windows\" /entry:\"mainCRTStartup\"") GLfloat r

利用SuperGlue算法实现跨尺度金字塔特征点的高效匹配(含py代码)
在计算机视觉领域,特征点匹配是一个基础而关键的任务,广泛应用于图像拼接、三维重建、目标跟踪等方向。传统的特征点匹配方法通常基于相同尺度下提取的特征进行匹配,然而在实际场景中,由于成像距离、分辨率等因素的差异,待匹配图像间存在显著的尺度变化,直接利用原始尺度的特征难以获得理想的匹配效果。为了克服这一难题,构建图像金字塔并在不同层级进行特征提取和匹配成为一种行之有效的策略。本文将给出如
python实现opencv学习十五:高斯金字塔和拉普拉斯金字塔
要求:拉普拉斯金字塔时,图像大小必须是2的n次方*2的n次方,不然会报错 代码如下: # -*- coding=GBK -*-import cv2 as cv#高斯金字塔def pyramid_image(image):level = 3#金字塔的层数temp = image.copy()#拷贝图像pyramid_images = []for i in range(level):dst

牛客网刷题 | BC103 金字塔图案
目前主要分为三个专栏,后续还会添加: 专栏如下: C语言刷题解析 C语言系列文章 我的成长经历 感谢阅读! 初来乍到,如有错误请指出,感谢! 描述 KiKi学习了循环,BoBo老师给他出了一系列打印图案的练习,该任务是打印用“*”组成的金字塔图案。 输入描述: 多组输入,一个整数(2~20),表示金字
牛客网刷题 | BC104 翻转金字塔图案
目前主要分为三个专栏,后续还会添加: 专栏如下: C语言刷题解析 C语言系列文章 我的成长经历 感谢阅读! 初来乍到,如有错误请指出,感谢! 描述 KiKi学习了循环,BoBo老师给他出了一系列打印图案的练习,该任务是打印用“*”组成的翻转金字塔图案。 输入描述: 多组输入,一个整数(2~20),表示
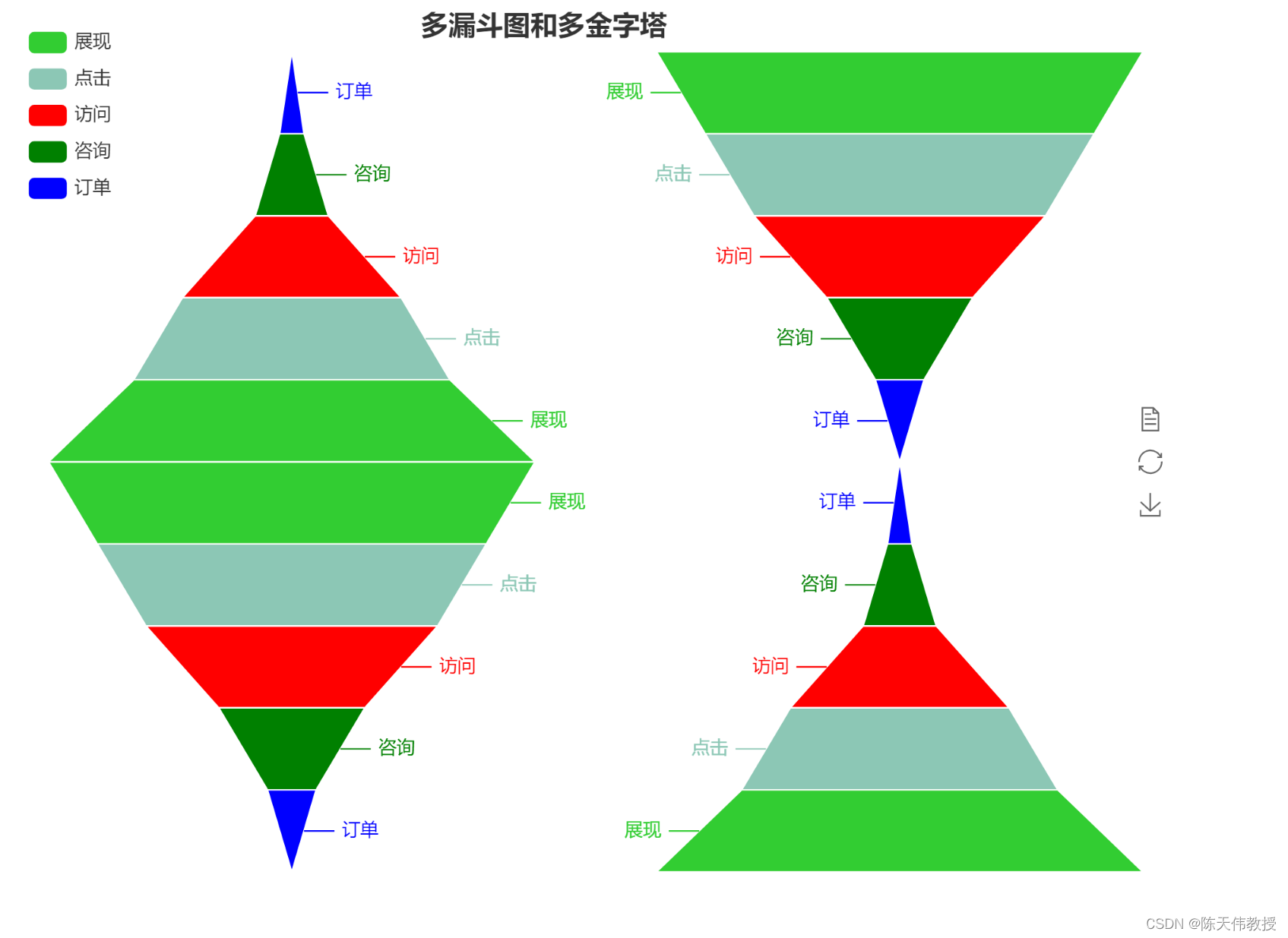
实操专区-第15周-课堂练习专区-漏斗图与金字塔图
实操专区-第15周-课堂练习专区-漏斗图 下载安装ECharts,完成如下样式图形。 代码和截图上传 基本要求:下图3选1,完成代码和截图 完成 3.1.3.16 漏斗图中的任务点 基本要求:2个选一个完成,多做1个加2分。 请用班级+学号+姓名命名。 参考代码: <!DOCTYPE html><html><head><meta charset = "utf-8"><!-- 引入 EC

手撕OpenCV源码之图像金字塔
图像金字塔 图像金字塔式多分辨率处理的一种方法,多分辨率处理理论有效的统一了多个学科的技术,多分辨率处理技术包括来自信号处理的子带编码,来自数字语音识别的正交滤波及金字塔图像处理。如其名称所示,多分辨率理论涉及多个分辨率下的信号(或图像)表示与分析。这种方法的优势很明显,,某种分辨率下无法检测的特性,可以在另外的分辨率下很容易检测。 我们观察图像时,看到的通常是由相似纹理和灰度级连成的区域,他们


特征融合篇 | YOLOv8改进之利用新的空间金字塔池化FocalModulation取代SPPF
前言:Hello大家好,我是小哥谈。Focal Modulation Networks(FocalNets)的基本原理是替换自注意力(Self-Attention)模块,使用焦点调制(focal modulation)机制来捕捉图像中的长距离依赖和上下文信息。本文所做的改进是将新的空间金字塔池化FocalModulation取代SPPF模块。🌈 目录
暑假编程训练---D:打印金字塔
Problem D:打印金字塔 Time Limit:1000MS Memory Limit:65536K Total Submit:5 Accepted:3 Description 请编写程序输出金字塔图形。 Input 多个测试数据。每个测试数据输入一个整数n(1 <= n <= 9) Output 输出n层金字塔。 Sample Input 13 Samp

C语言例题42、打印金字塔
#include <stdio.h>void main() {int i, j;for (i = 0; i < 5; i++) {for (j = 4; j > i; j--) {//输出空格printf(" ");}for (j = 0; j < 2 * i + 1; j++) {//输出星号printf("* ");}printf("\n");}} 运行结果: 本章C语言经典例题合集
习题:输入任意大写字母,生成金字塔图形
package com.test.code;import java.io.*;public class pyramid {public static void main(String[] args) {System.out.print("请输入单个大写字母,以创建金字塔图形:");char c = ' '; try {c = (char )System.in.read();} catch (I

即插即用篇 | YOLOv8引入PSAModule | 高效金字塔压缩注意力模块
本改进已集成到 YOLOv8-Magic 框架。 最近研究表明,通过在深度卷积神经网络中嵌入注意力模块可以有效地提高网络性能。在这项工作中,提出了一种新的轻量级且有效的注意力方法,名为金字塔挤压注意力(PSA)模块。通过在ResNet的瓶颈块中用PSA模块替换3x3卷积,得到了一种新的表征块,称为高效金字塔挤压注意力(EPSA)块。EPSA块可以轻松地作为即插即用的组件添加到一个成熟

基于OpenCv的图像金字塔
⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计3077字,阅读大概需要3分钟 🌈更多学习内容, 欢迎👏关注👀【文末】我的个人微信公众号:不懂开发的程序猿 个人网站:https://jerry-jy.co/ ❗❗❗知识付费,🈲止白嫖,有需要请后台私信或【文末】个人微信公众号联系我 基于OpenCv的图像金字塔 基于OpenCv的图像金字塔任务需求任
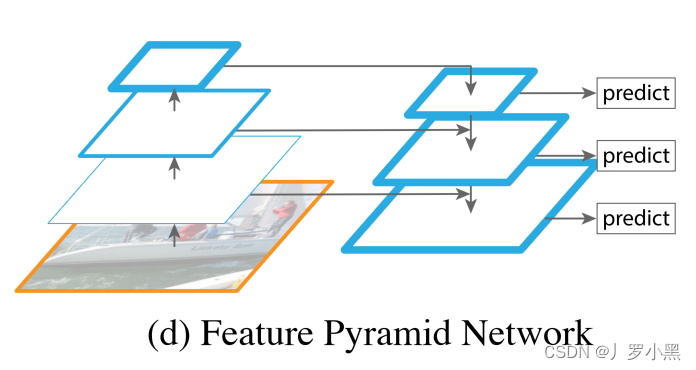
场景文本检测识别学习 day08(无监督的Loss Function、代理任务、特征金字塔)
无监督的Loss Function(无监督的目标函数) 根据有无标签,可以将模型的学习方法分为:无监督、有监督两种。而自监督是无监督的一种无监督的目标函数可以分为以下几种: 生成式网络的做法,衡量模型的输出和固定的目标之间的差距,主要考虑输入数据是怎么分布的,即 “给定Y,如何生成X”。如auto-encoder:输入一张干扰过的图,通过编码器-解码器,然后得出一张还原后的图,通过对比原图和生成

分层图像金字塔变压器
文章来源:hierarchical-image-pyramid-transformers 2024 年 2 月 5 日 本文介绍了分层图像金字塔变换器 (HIPT),这是一种新颖的视觉变换器 (ViT) 架构,设计用于分析计算病理学中的十亿像素全幻灯片图像 (WSI)。 HIPT 利用 WSI 固有的层次结构通过自我监督学习来学习高分辨率图像表示。 HIPT 在涵盖 33 种癌症类型的大型数据