采坑专题

运行Dubbo-demo示例采坑集合
运行Dubbo-demo示例采坑集合 部分参考: https://www.cnblogs.com/juncaoit/p/7606170.html 前置条件:jdk,zookeeper,tomcat,maven环境配置正确 1、工程目录结构  2、先cd到Dubbo-demo下面执行命令mvn clean install编译整个工程   3、本地运行时zookeeper注册地址修改 pr

docker安装mysql和mysql的主从复制的搭建(采坑记录)可用
为了在docker搭建mysql的主从复制,踩了很多坑,特此记录一下。 一、安装环境: 1.1.mac:MacBook Pro 1.2.docker安装的是Docker Desktop,附链接:https://www.docker.com/products/docker-desktop 1.3已经安装好了docker 二、安装mysql 1.docker安装mysql docker

android sdk配置采坑
环境变量中配置ANDROID_HOME时,路径不能带空格,配完path之后,cmd直接运行adb能跑就疏忽了,没想到还有这回事,说起来,之前nodejs的cache等路径好像也是不能带空格来着,以后这点在弄很多东西之前都要提前预防了
Gitlab集成CI gitlab-run采坑记录
准备在内网搭建基于gitlab,gitbook的环境。然而坑不少。 软件版本: gitlab :8.13.5 PostgreSQL:9.2.18 在网上找了清华的gitlab镜像站,分别下载gitlab-runner gitlab-ci-multi-runner. 安装完之后,准备配置CI,系统报错405 [root@tianji09 yum.repos.d]# gitlab-

Graphql采坑之-全家桶版本兼容性
引言 在配置日常的react 项目中发现要搭配好react,apollo-client,graphql的版本还是不容易的,尤其是在众多package单独拆解功能的情况下。经过几天的摸索勉强找到了npm package的版本清单。 package.json dependencies": {"apollo-cache-inmemory": "^1.6.0","apollo-client":
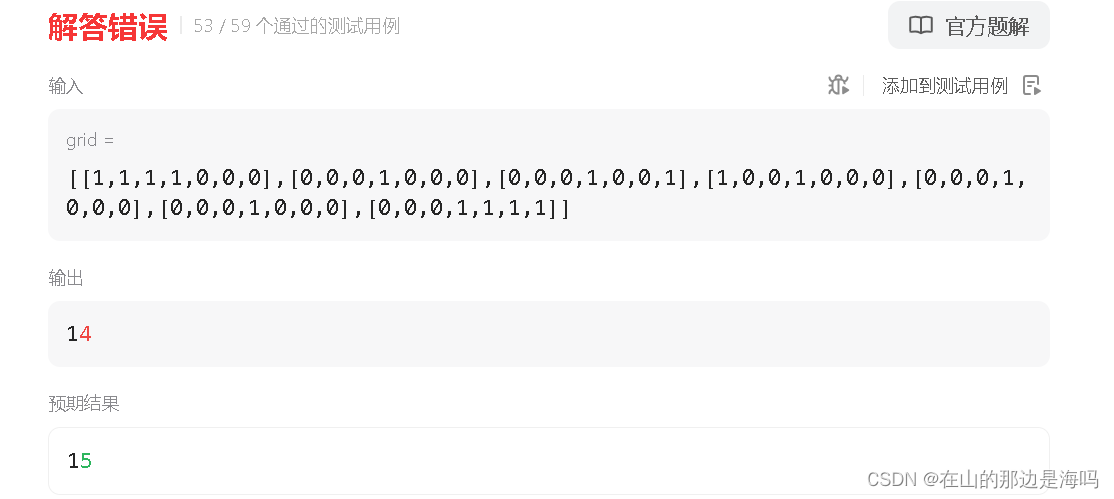
记一次动态规划的采坑之旅, 741摘樱桃 https://leetcode.cn/problems/cherry-pickup/description/
首次看题目时,发现是困难。立马想到了,动态规划。 再看题目, 摘樱桃,还要返回摘两次,求摘最多的樱桃。 大脑第一反应就是: 先使用动态规划,找到 0 0 到 n-1 n-1处走过的最大樱桃, 并记录路径path。 然后根据路径path,将摘过的樱桃置为0,表示已经被摘过了。 然后再次摘樱桃。 两次摘过的樱桃之和就是目标的结果。 嗯,应该是,那就开写。 func cherr
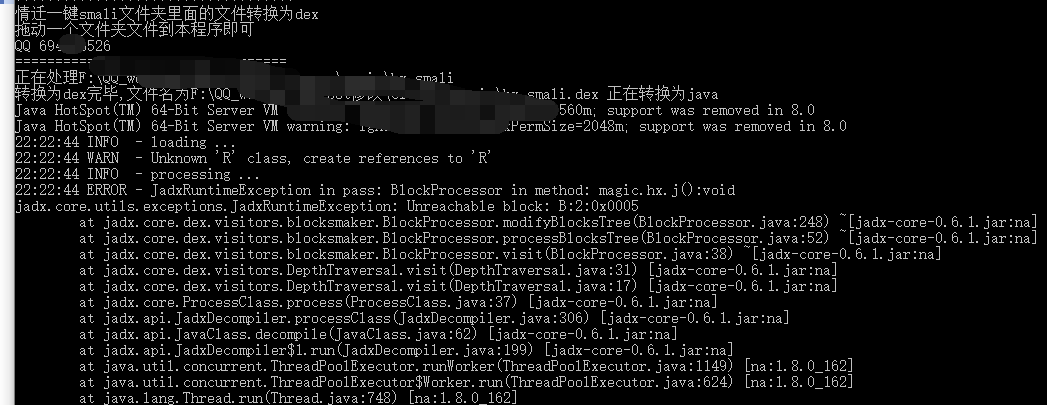
smali指令设置空的静态方法采坑与解决
如果直接删除会导致如下错误.method public static a()V方法直接删除会导致如下错误a non-abstract method must have at least 1 instruction 修改为 .locals 2.prologue.line 902const/4 v0,0x1return-void 如果只保留void,则提示A register .locals d
ubuntu 安装vmware tools采坑
安装这个会出现很多坑,主要原因还是vmware-tools版本太老了,于是我从官网下载了一个最新的就解决了问题,网上的问题解决办法都并不能根本解决, VMwareTools-9.9.2-2496486.tar.gz 解压后的文件夹如下,vmware-install.pl是用来安装的./vmware-install.pl 如果提示Please correct the failure and re
arm-linux开发采坑之链接脚本文件
arm-linux开发采坑之链接脚本文件 开始写的错误的链接脚本文件: SECTIONS{. = 0x80870000;.text :{start.omain.o*(.text)}.rodata ALIGN(4) : {*(.rodata*)}.data ALIGN(4) : {*(.data)}__bss_start = .;.bss ALIGN(4) : {*(.bss) *(COMMON

Android 发布bintray采坑记
Android 发布bintray采坑记 笔记,不喜勿喷 方式一 参考:亲测:最简单的Android studio发布Library到Jcenter 准备工作 1、新建Android 工程和需要发布的依赖项目,并编译成功。 2、提交GitHub仓库(可省) 3、新建bintray 账号、仓库(含package和version) 第一步 在工程下新建"bintray.gradle
Oracle安装采坑记录
Oracle安装记录 数据库课程要安装oracle,记录一下 遇到的问题 先跟着指导书走,注意路径 CentOS 6设置中文 su - rootvi /etc/sysconfig/i18n 更改为 #LANG="en_US.UTF-8"LANG="zh_CN.UTF-8" 保存重启 检查并安装依赖包 用yum直接安装省的解压光驱的package rpm -qa | gr
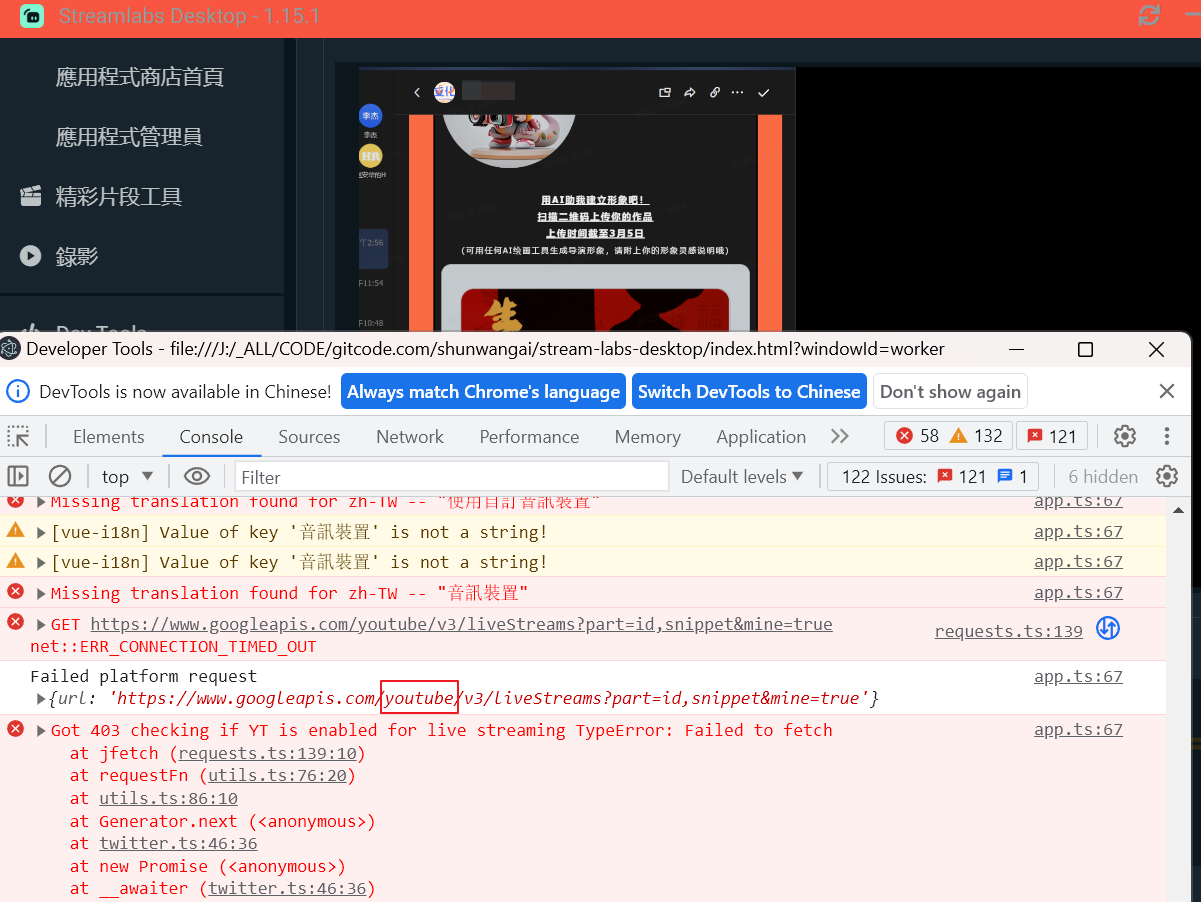
【OBS】stream-labs-desktop 编译运行采坑全攻略
▒ 目录 ▒ 🛫 导读需求开发环境 1️⃣ 安装yarn安装 2️⃣ 安装依赖库:yarn installcertificate has expiredelectron@npm:25.9.3 couldn't be built successfully 3️⃣ 启动desktop项目编译调试模式启动启动缓慢问题 4️⃣ 打包🛬 文章小结📖 参考资料 🛫 导读 需求
Git submodule 采坑
Git submodule 采坑 使用git submodule update --init 时遇到错误:error: Server does not allow request for unadvertised object 错误日志: error: Server does not allow request for unadvertised object 77ad8cf1deb654a63
小程序采坑一:倒计时在ios不识别,安卓可以
说明: 在小程序中ios识别的日期格式为:2018/06/30,因此有时后写倒计时等涉及时间的方法时,会出现安卓可以,ios不可以的问题 解决方法: 日期格式全部设置为xxxx/xx/xx 格式 具体方法: xx.replace(/-/g, "/")

pomelo使用采坑记(学习使用部署相关)
pomelo学习、使用和部署 pomelo推送方式频道推送直接推送 bearcat集成remote和handler集成非pomelo框架的service、util等的集成bearcat优势 默认路由规则采坑未进行用户Id绑定的多服务器远程调用路由配置 log按照时间日期服务器分割按服务器和天分割按服务端和小时分割按天分割 IDEA调式服务器配置IDEA配置步骤 分布式部署ssh方式非ssh方
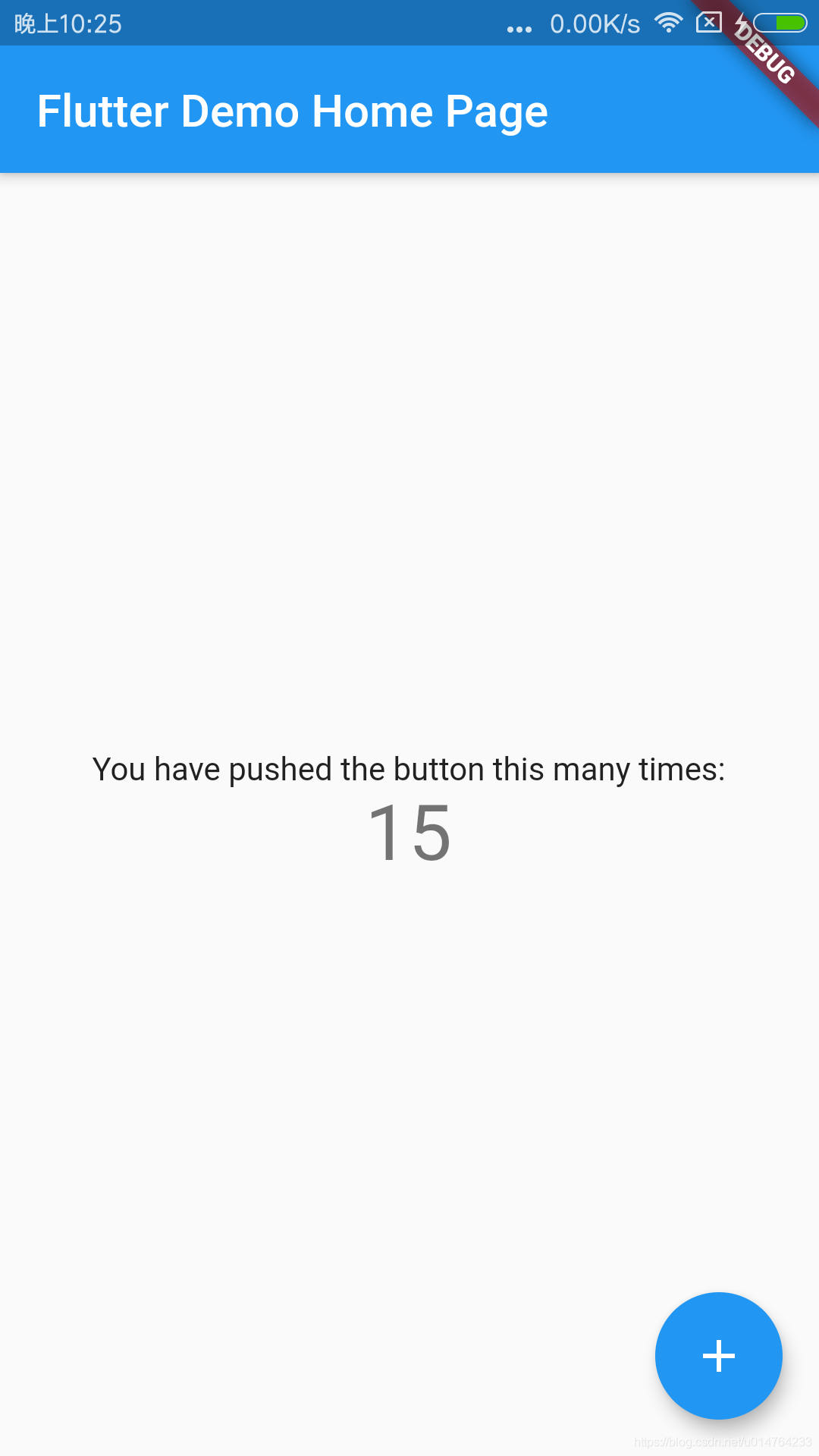
Flutter环境搭建采坑大全,报错The Flutter directory is not a clone of the GitHub project和Error running Gradle及解决
1.安装Flutter,推荐 Flutter中文网 这个网站的介绍还是比较全,国内需要配置临时镜像,配在用户变量就行,我是直接配在系统变量里,如下图 在github上下载完Flutter后并解压,记得在Path里配flutter的环境 重启让环境变量生效,在基本操作都做完后打开cmd无比激动的敲下了flutter doct Error: The Flutter directory
Mysql的采坑记录1-慢查询拖垮服务
问题: 服务日志中出现CannotGetJdbcConnectionException,如下所示,该怎么排查? org.springframework.jdbc.CannotGetJdbcConnectionException: Failed to obtain JDBC Connection; nested exception is java.sql.SQLTransientConnect

window 和linux 在Python中安装Talib包,python,talib 亲测采坑 2020/10
python 安装talib包 python 安装talib包 windows下 python 安装talib 包ubuntu 下 python 安装talib 包 编译安装talib 库复制文件安装 python3-dev安装ta-lib python 安装talib包 talib 是Python金融量化的高级库,涵盖了150多种股票、期货交易软件中常用的技术分析指标,如MAC
SpringCloud采坑之Feign服务间调用默认返回xml
日前在使用SpringCloud的时候,需要用到服务间的调用,采用Feign进行调用,但是默认返回了xml格式的数据,比较坑爹,不过在网上查了相关资料之后大概了解怎么回事: 主要是引入了jackson-dataformat-xml这个依赖,它是提供了jackson将实体类转化为xml相关的作用。而本身jackson是可以将实体类转化为json的,所以这样Jackson是可以将实体类转化为两种类型

tensorflow 1.13.1 安装采坑
环境: win10 x64位,cuda10.1,cudnn 7.5,vs2013,vs2015 distributed ,GTX1060 按照网上的教程安装,如下面博客 https://blog.csdn.net/huanyingzhizai/article/details/89298964 我最后的安装位置:anaconda2下面的虚拟环境py3下面新建虚拟环境:tensorflow-g

win10+vs2013+opencv 3.1编译darknet YOLOv3 采坑记录
网上教程很多,推荐https://blog.csdn.net/maweifei/article/details/81150489这篇博客讲的很详细,基本按照这个流程没有问题。 但是每个人的电脑环境都不同,我的环境: win10 x64位,vs2013,opencv contrib 3.10版本,显卡GTX1060,cuda版本10.1,cudnn版本7.5 我在此记录下遇到的一些问题: 1

微信小程序采坑记录:http:XXX 不在以下request合法域名列表中的解决方法
场景复原 后端给的服务器域名有时候是没有 HTTPS 的,有时小程序就会报错,报错如图: 报错原因 请求时系统会对服务器域名使用的 HTTPS 证书进行校验,如果校验失败,则请求不能成功发起。 解决方案 只要取消校验即可。 击微信开发者工具右上角的详情,在弹出的弹框之中选择项目设置,勾选 不校验合法域名、web-view(业务域名)、TLS 版本以及 HTTPS 证书。 此时请求就
Pytorch采坑记录:DDP 损失和精度比 DP 差,多卡GPU比单卡GPU效果差
结论:调大学习率或者调小多卡GPU的batch_size 转换DDP模型后模型的整体学习率和batch_size都要变。 当前配置::1GPU:学习率=0.1,batch_size=64 如果8GPU还按之前1GPU配置:8GPU:学习率=0.1,batch_size=64 那么此时对于8GPU而言,效果几乎等于::1GPU:学习率=0.1,batch_size=64 * 8=512 这种
Vue 中的图片加载(采坑)
1、import import remarkIcon from './redflag.png'; L.icon 中使用 iconUrl 用 import 的图片 let icon = L.icon({iconUrl: remarkIcon,iconSize: [16, 16]}); 2、require <img :src="require('./redflag.png')" alt=
Pytorch采坑记录:DDP 损失和精度比 DP 差,多卡GPU比单卡GPU效果差
结论:调大学习率或者调小多卡GPU的batch_size 转换DDP模型后模型的整体学习率和batch_size都要变。 当前配置::1GPU:学习率=0.1,batch_size=64 如果8GPU还按之前1GPU配置:8GPU:学习率=0.1,batch_size=64 那么此时对于8GPU而言,效果几乎等于::1GPU:学习率=0.1,batch_size=64 * 8=512 这种