超大专题

mysql source命令超大文件导入方法总结
下面收集了两种解决办法,一种是把数据库分文件导出然后再导入,另一种是修改my.ini配置文件。 导入1G的数据,但是在怎么都导入不了,用命令行就可以轻松搞定了。用mysql source命令可以导入比较大的文件。 代码如下 复制代码 mysql>use dbtest; mysql>set names utf8; mysql>source D:/www/sql/back.sql;

Qt超大文本文件读取
Qt读取,显示几百M甚至几个G的超大文本文件时,调用QFile::open()读取,容易出现加载卡死。 对此,可以调用QFile::map()反射内存。 uchar *QFileDevice::map(qint64 offset, qint64 size, QFileDevice::MemoryMapFlags flags = NoOptions) Maps size bytes of th

判断ip是否在一个超大ip集中(识别国内ip)
原文地址: https://www.ikaze.cn/article/65 新需求需要通过ip展示不同语言,由于ip很多,因此字典并不适用,下面给出几个方法。 1. 通过ip位置数据库 比较有名的服务商有:ipip(付费), maxmind (付费),纯真 (免费)。 但在这个应用场景下,我们并不需要具体的位置信息,类似的方案会浪费不必要的内存因此放弃。 2. 利用ip的连续性 后面两
js超过Number最大值该如何处理(超大数 运算失去精度)
在JavaScript中,Number 类型使用的是双精度64位浮点数(IEEE 754标准),其最大安全整数值为 2^53 - 1,即 9007199254740991,可以通过 Number.MAX_SAFE_INTEGER 来获取。如果超过这个值,可能会导致计算误差或不准确的结果。 当需要处理超过 Number.MAX_SAFE_INTEGER 的大整数时,通常有以下几种方法: 1. 使

CVPR最佳学生论文!1千万张图像、跨越45万+物种的超大数据集,多模态模型BioCLIP实现零样本学习
不同于传统学术领域对期刊发表的重视,计算机界,尤其是机器学习、计算机视觉、人工智能等领域,顶级会议才是王道,无数「热门研究方向」、「创新方法」都将从这里流出。 作为计算机视觉乃至人工智能领域最具学术影响力的三大顶会之一,今年的国际计算机视觉与模式识别会议 (CVPR) 从会议规模到接受论文数量,都刷新了此前记录。 活动现场,图源:Dan Goldman 根据 CVPR 官方的最新公告,C
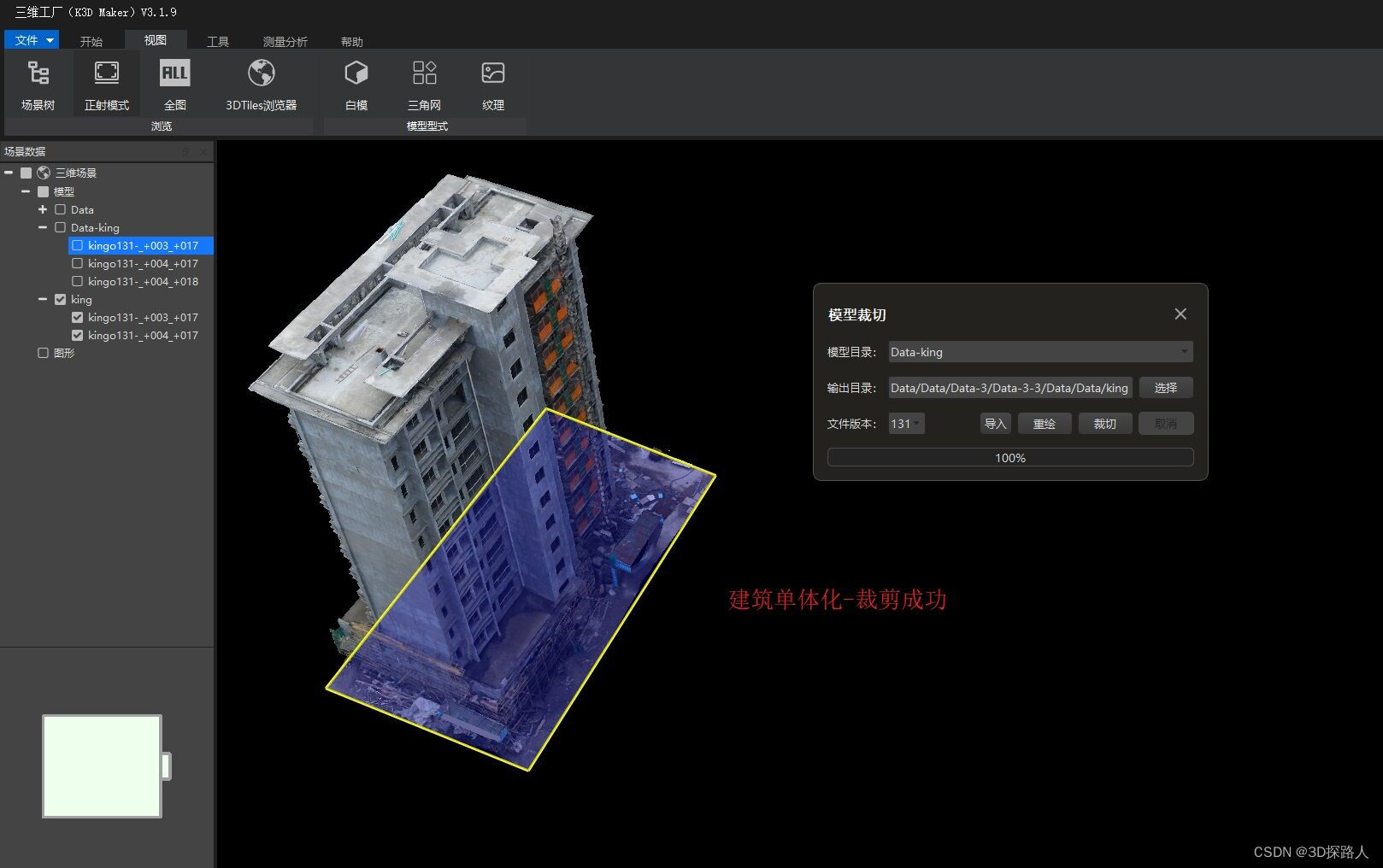
超大场景的三维模型(3D)轻量化的主要技术方法
超大场景的三维模型(3D)轻量化的主要技术方法 超大场景的三维模型在虚拟现实、游戏开发和可视化应用等领域具有重要的价值和应用前景。然而,由于其庞大的数据量和复杂的几何结构,给数据存储、传输和渲染带来了挑战。为了提高超大场景三维模型的性能和运行效率,轻量化成为关键的技术需求。本文将介绍超大场景三维模型轻量化的主要技术方法,以提高模型的性能和可视化效果。 首先,基于LOD(Level of

1亿的图片+视频,雅虎发布超大Flickr数据集
http://www.csdn.net/article/2014-07-07/2820559 雅虎已经发布了一个巨大的数据集为研究人员进行实验。这个数据集由1亿图片和70万视频的URL组成,同时也包含了它们的元数据。在不久的将来,一个更大的包含音频和视频的由超级计算机处理的数据集将能被使用。 Yahoo Flickr Creative Commons当下已有1亿内容,其中

mysql自增id超大问题的排查与解决
这篇文章主要给大家介绍了关于mysql自增id超大问题的排查与解决方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 引言 小A正在balabala写代码呢,DBA小B突然发来了一条消息,“快看看你的用户特定信息表T,里面的主键,也就是自增id,都到16亿了,这才多久,在这样下去过不了多久主键就要超出范围了,插入就会失败,
在pytorch中load超大训练数据
在pytorch中load超大训练数据 by joeyqzhou 相关代码地址: https://github.com/joeyqzhou/blog/tree/master/pytorch%E4%B8%ADload%E8%B6%85%E5%A4%A7%E8%AE%AD%E7%BB%83%E6%95%B0%E6%8D%AE 最简单方式: 1 单线程获取数据到内存中 2 train的过
Docker安装MySQL中导入超大的SQL文件
一、准备工作 1、安装MySQL https://blog.csdn.net/u011374856/article/details/103344949 2、超大SQL文件目录 注意:本教程针对Docker安装MySQL,找到容器挂载宿主机的一个目录即可,例如:-v /home/docker/mysql/data:/var/lib/mysql 把超大SQL文件拷贝到/home/docker
通过SqlCmd执行超大SQL文件
##通过sqlcmd执行sql文件 由于sql文件过大,超过了100M,再数据库的窗口执行,结果超出内存了,对于特别大的sql文件可以使用sqlcmd进行执行 ###1.打开cmd窗口 运行–cmd–进入到sql文件所在的文件夹。 如果是win7可按Shift+右键 在此窗口打开文件夹 运行–cmd–使用下面地址(注意是自己的sqlserver数据库的安装路径) ###2.运行sqlc
c#快速获取超大文件夹文件名
c#快速获取超大文件夹文件名 枚举集合速度快:(10万个文件) //by txwtech IEnumerable<string> files2 = Directory.EnumerateFiles("d:\aa", "*.xml", SearchOption.TopDirectoryOnly);//过滤指定查询xml文件 慢: var filename2= Directory.GetF
安卓Framework修改字体默认超大
1、在alps/frameworks/base/core/java/android/content/res/Configuration.java文件中如下 public void setToDefaults() 这个方法中进行修改, 如:把默认字体要改为超大,把fontScale值改为1.15f,然后重新build framework.jar这个模块即可; public void se
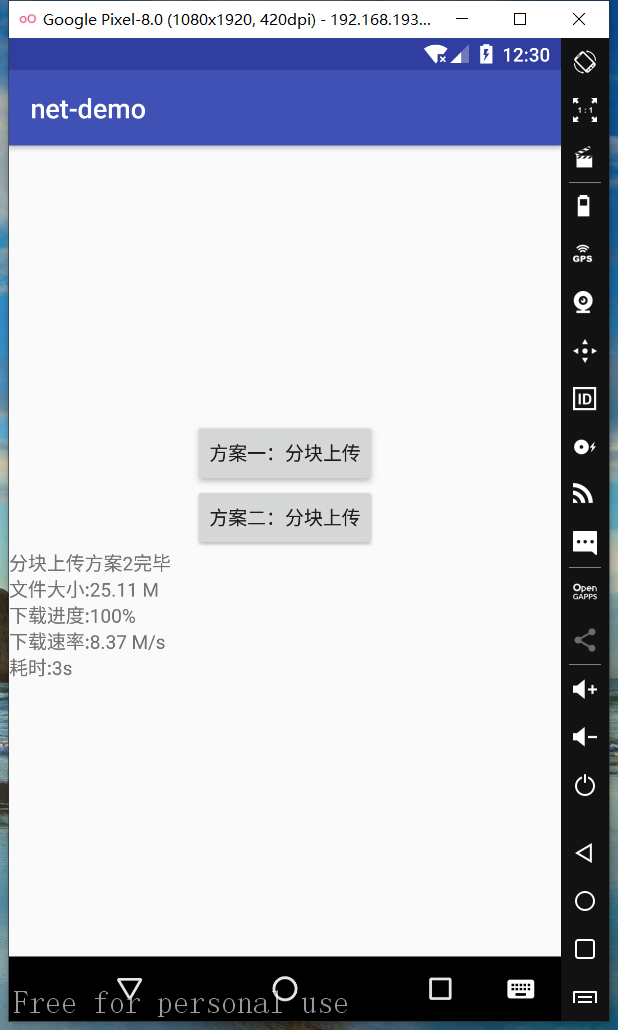
基于RxJava2.0+Retrofit2.0超大文件分块(分片)上传(带进度)
当上传文件过大时,直接上传会增加服务器负载,负载过高会导致机器无法处理其他请求及操作,甚至导致宕机,这时分块上传是最佳选择。本次简单介绍两种分块上传文件方案(暂不考虑文件安全相关问题,如签名): 方案一: 客户端把单个文件切割成若干块,依次上传,最后由服务端合并 方案二: 客户端读取文件 offset 到 offset+chunk的文件块上传,每次上传完返回新的offset(或者每次上传后,本地

数据库存储效率优化实战:从50PB到32PB(超大容量优化策略)
http://www.infoq.com/cn/news/2017/01/Efficient-Storage-50-32-PB?utm_source=tuicool&utm_medium=referral 对电子邮件服务的用户来说,邮箱容量早已不是值得关心的问题,几乎所有主流邮件服务商都提供了容量大到很少有人能用完的服务。然而对服务商来说,尽可能降低成本,提升系统,尤其是存储系统的使用效率

超大模型分布式训练DeepSpeed教程
DeepSpeed教程 项目链接 简介 deep speed是微软的新大规模模型分布式训练的工具。专门为训练超大模型而生。号称可以训练10B参数的模型。比目前最好的模型大10倍,训练速度块10倍。兼容pytorch的模型,可以改动最少代码。下图是展示训练bert需要的时间,基本同gpu的数量成线性相关。 安装 下载code(0.3.0) git clone https://githu
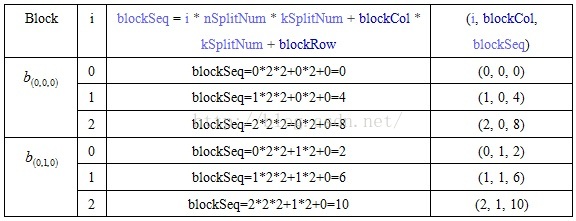
基于Spark实现的超大矩阵运算
由于标题强调了是在Spark平台实现的矩阵运算,所以本文会非常有针对性的介绍,甚至细节到Spark RDD的算子。 1.算法描述 思想其实很简单,就是矩阵分块计算,而分块矩阵就成了小矩阵,然后就借助于Breeze实现。而对于Spark平台而言,其处理流程如下图: 2.矩阵分块依据 这里仅仅提供一种思路,所以仅供参考。假设有两个矩阵A和B,其中A是m*k的矩阵,B是k*n的矩阵,CPU
python-对超大遥感图像进行裁剪
代码如下: from PIL import Image# 解决文件过大问题from PIL import ImageFileImageFile.LOAD_TRUNCATED_IMAGES = TrueImage.MAX_IMAGE_PIXELS = Noneimport sys#先将 input image 填充为正方形def fill_image(image):width, hei

企业邮箱超大附件怎么发送?给你一个妙招
随着文件体量越来越大,越来越多的企业需要发送邮箱超大附件,那么,企业邮箱超大附件怎么发送,才能又快又安全呢?今天就为大家解答一下。 首先,我们看看传统的邮箱发送附件会存在哪些问题: 1、附件大小限制:大多数邮件系统对附件大小有限制,超出限制的文件无法通过邮件直接发送。 2、服务器压力:大附件会占用大量服务器空间和带宽,影响邮件服务器的性能,导致服务器变慢。 3、上传失败:在网络不稳定的

Excel文件解析--超大Excel文件读写
使用POI写入 当我们想在Excel文件中写入100w条数据时,我们用普通的XSSFWorkbook对象写入时会发现,只有在将100w条数据全部加载入内存后才会用write()方法统一写入,这样效率很低,所以我们引入了SXSSFWorkbook进行超大Excel文件的读写。 SXSSFWorkbook可以通过构造参数来控制:当数据写入内存量达到参数值时,就把这些
syncronized+wait/notify Java实现的语言级别的超大管程+Java 多线程机制的发展
最先是:syncronized+wait/notify 不知道Java的syncronized的设计者是怎么思考的,将OOP的对象当做是条件变量,将syncronized 临界区 作为管程资源,真的是一个大手笔:想象整个Jvm就是一个大管程,每个Object都是一个condition 从每一个对象头的markword 都有轻量锁和重量锁的 标志位 也能看的出来 后来是Condition,Loc

视频监控平台的超大任务文件导入功能,如何通过日志判断导入是否成功
目录 一、概述 (一)编写目的 (二)适用情况 (三)导入相关参数说明 二、文件导入说明 (一) 日志文件路径 (二)不同情况下的说明和提示 1、 所有数据正确情况 2、 有部分数据错误的情况 3、 所有数据错误的情况 三、结论 一、概述 (一)编写目的 客户任务室要增加监控设备,想要将试验任务管理平台和视频监控平台结合起来,方便管理。试
Python3:读取和处理超大文件
在日常工作中,文件对象是我们常接触到的可迭代类型之一。一般用 for 循环遍历一个文件对象,可以逐行读取它的内容。但这种方式在碰到大文件时,可能会出现一些奇怪的效率问题。 需求: 小明是一位 Python 初学者,在学习了如何用 Python 读取文件后,他想要做一个小练习:计算某个文件中数字字符(0~9)的数量。 场景1:小文件处理 假设现在有一个测试用的小文件 small_fi
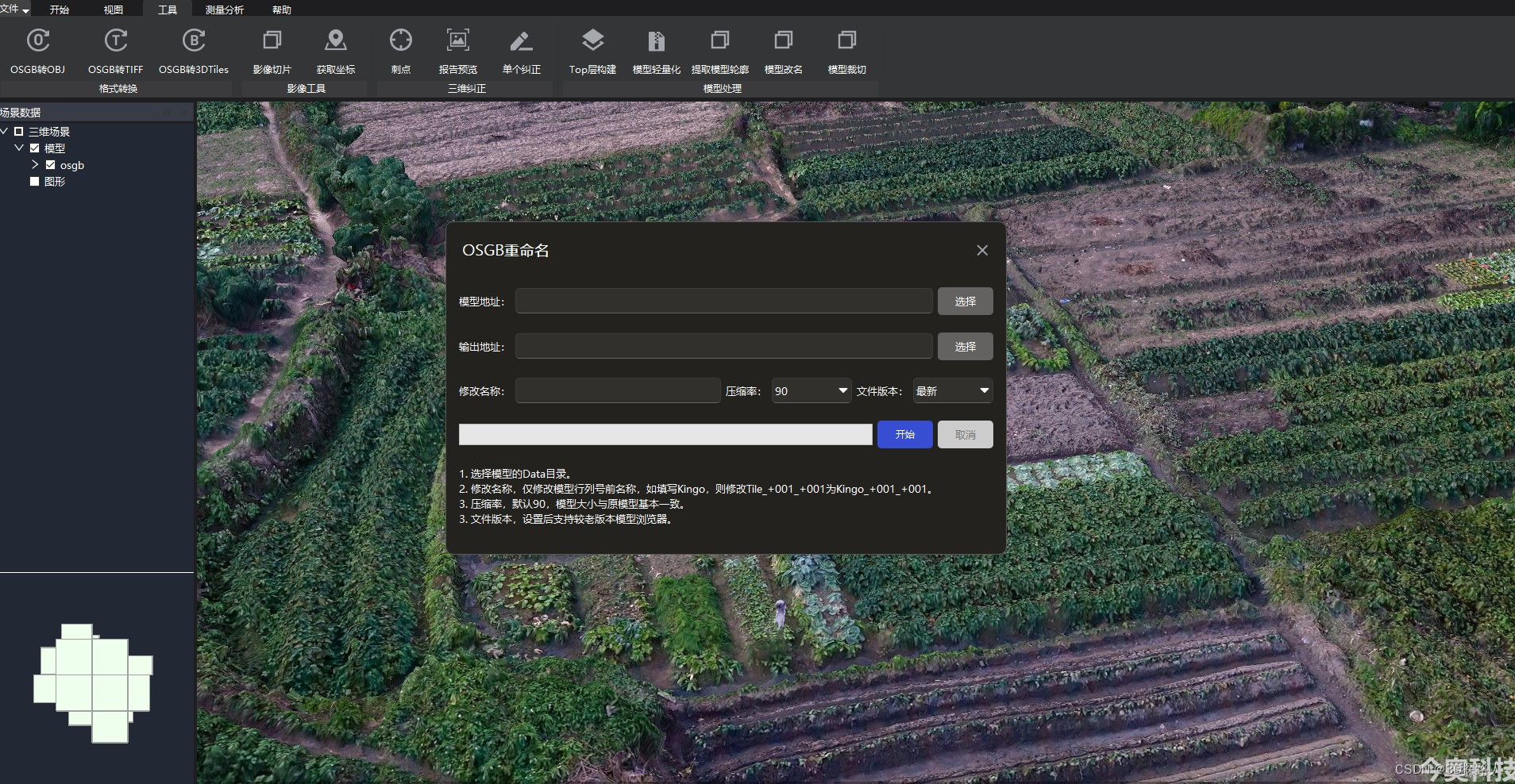
如何实现超大场景三维模型数据立体裁剪
如何实现超大场景三维模型数据立体裁剪 实现超大场景三维模型数据的立体裁剪可以采用如下方法: 数据预处理:将超大场景三维模型数据进行划分和分割,将其拆分成多个小块或网格。这样可以方便进行后续的裁剪操作。 裁剪算法选择:根据具体需求选择合适的裁剪算法。一种常用的方法是基于边界框(Bounding Box)的裁剪。即通过设定裁剪区域的边界框,只保留位于边界框内部的模型数据,去除边界框外
自动分割文本编辑器打不开的超大文本文档
以下代码中把$inputFile和$outputFilePrefix 分别换成你的文件和需要分割后放到的文件夹; # 定义要分割的文件路径和分割后文件的前缀 $inputFile = "D:\logheiping\Logs\CNGarage.log" $outputFilePrefix = "D:\logheiping\Logs\splitlog" $chunkSizeMB = 10

openCV编程基础14--超大图像二值化
功能: 对超大图进行二值化 import cv2 as cvimport numpy as np#超大图像二值化,采用分割加局部阈值的方法#由于图像比较大cv.imshow显示不全,我们把图保存,用图像查看器来看def big_image_binary(image):print(image.shape)cw = 256ch = 256h, w = image.shape[:2]gray