本文主要是介绍mysql自增id超大问题的排查与解决,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这篇文章主要给大家介绍了关于mysql自增id超大问题的排查与解决方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
引言
小A正在balabala写代码呢,DBA小B突然发来了一条消息,“快看看你的用户特定信息表T,里面的主键,也就是自增id,都到16亿了,这才多久,在这样下去过不了多久主键就要超出范围了,插入就会失败,balabala......”
我记得没有这么多,最多1k多万,count了下,果然是1100万。原来运维是通过auto_increment那个值看的,就是说,表中有大量的删除插入操作,但是我大部分情况都是更新的,怎么会这样?
下面话不多说了,来一起看看详细的介绍吧
问题排查
这张表是一个简单的接口服务在使用,每天大数据会统计一大批信息,然后推送给小A,小A将信息更新到数据库中,如果是新数据就插入,旧数据就更新之前的数据,对外接口就只有查询了。
很快,小A就排查了一遍自己的代码,没有删除的地方,也没有主动插入、更新id的地方,怎么会这样呢?难道是小B的原因,也不太可能,DBA那边儿管理很多表,有问题的话早爆出来了,但问题在我这里哪里也没头绪。
小A又仔细观察了这1000多万已有的数据,将插入时间、id作为主要观察字段,很快,发现了个问题,每天第一条插入的数据总是比前一天多1000多万,有时候递增的多,有时候递增的少,小A又将矛头指向了DBA小B,将问题又给小B描述了一遍。
小B问了小A,“你是是不是用了REPLACE INTO ...语句”,这是怎么回事呢,原来REPLACE INTO ...会对主键有影响。
REPLACE INTO ...对主键的影响
假设有一张表t1:
| 1 2 3 4 5 6 7 |
|
如果新建这张表,执行下面的语句,最后的数据记录如何呢?
| 1 2 |
|
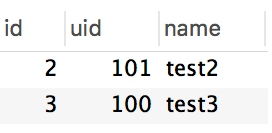
原来,REPLACE INTO ...每次插入的时候如果唯一索引对应的数据已经存在,会删除原数据,然后重新插入新的数据,这也就导致id会增大,但实际预期可能是更新那条数据。
小A说:“我知道replace是这样,所有既没有用它”,但还是又排查了一遍,确实不是自己的问题,没有使用REPLACE INTO ...,
小A又双叒叕仔细的排查了一遍,还是没发现问题,就让小B查下binlog日志,看看是不是有什么奇怪的地方,查了之后还是没发现问题,确实存在跳跃的情况,但并没有实质性的问题。
下图中@1的值对应的是自增主键id,用(@2, @3)作为唯一索引

后来过了很久,小B给小A指了个方向,小A开始怀疑自己的插入更新语句INSERT ... ON DUPLICATE KEY UPDATE ...了,查了许久,果然是这里除了问题。
INSERT ... ON DUPLICATE KEY UPDATE ...对主键的影响
这个语句跟REPLACE INTO ...类似,不过他并不会变更该条记录的主键,还是上面t1这张表,我们执行下面的语句,执行完结果是什么呢?
| 1 |
|

没错,跟小A预想的一样,主键并没有增加,而且name字段已经更新为想要的了,但是执行结果有条提示,引起了小A的注意
No errors; 2 rows affected, taking 10.7ms
明明更新了一条数据,为什么这里的影响记录条数是2呢?小A,又看了下目前表中的auto_increment
?
| 1 2 3 4 5 6 7 |
|
竟然是5`,这里本应该是4的。
也就是说,上面的语句,会跟REPLACE INTO ...类似的会将自增ID加1,但实际记录没有加,这是为什么呢?
查了资料之后,小A得知,原来,mysql主键自增有个参数innodb_autoinc_lock_mode,他有三种可能只0,1,2,mysql5.1之后加入的,默认值是1,之前的版本可以看做都是0。
可以使用下面的语句看当前是哪种模式
| 1 |
|
小A使用的数据库默认值也是1,当做简单插入(可以确定插入行数)的时候,直接将auto_increment加1,而不会去锁表,这也就提高了性能。当插入的语句类似insert into select ...这种复杂语句的时候,提前不知道插入的行数,这个时候就要要锁表(一个名为AUTO_INC的特殊表锁)了,这样auto_increment才是准确的,等待语句结束的时候才释放锁。还有一种称为Mixed-mode inserts的插入,比如INSERT INTO t1 (c1,c2) VALUES (1,'a'), (NULL,'b'), (5,'c'), (NULL,'d'),其中一部分明确指定了自增主键值,一部分未指定,还有我们这里讨论的INSERT ... ON DUPLICATE KEY UPDATE ...也属于这种,这个时候会分析语句,然后按尽可能多的情况去分配auto_incrementid,这个要怎么理解呢,我看下面这个例子:
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
上面的例子执行完之后表的下一个自增id是10,你理解对了吗,因为最后一条执行的是一个Mixed-mode inserts语句,innoDB会分析语句,然后分配三个id,此时下一个id就是10了,但分配的三个id并不一定都使用。此处 @总是迟到 多谢指出,看官方文档理解错了
模式0的话就是不管什么情况都是加上表锁,等语句执行完成的时候在释放,如果真的添加了记录,将auto_increment加1。
至于模式2,什么情况都不加AUTO_INC锁,存在安全问题,当binlog格式设置为Statement模式的时候,从库同步的时候,执行结果可能跟主库不一致,问题很大。因为可能有一个复杂插入,还在执行呢,另外一个插入就来了,恢复的时候是一条条来执行的,就不能重现这种并发问题,导致记录id可能对不上。
至此,id跳跃的问题算是分析完了,由于innodb_autoinc_lock_mode值是1,INSERT ... ON DUPLICATE KEY UPDATE ...是简单的语句,预先就可以计算出影响的行数,所以不管是否更新,这里都将auto_increment加1(多行的话大于1)。
如果将innodb_autoinc_lock_mode值改为0,再次执行INSERT ... ON DUPLICATE KEY UPDATE ...的话,你会发现auto_increment并没有增加,因为这种模式直接加了AUTO_INC锁,执行完语句的时候释放,发现没有增加行数的话,不会增加自增id的。
INSERT ... ON DUPLICATE KEY UPDATE ...影响的行数是1为什么返回2?
为什么会这样呢,按理说影响行数就是1啊,看看官方文档的说明
With ON DUPLICATE KEY UPDATE, the affected-rows value per row is 1 if the row is inserted as a new row, 2 if an existing row is updated, and 0 if an existing row is set to its current values
官方明确说明了,插入影响1行,更新影响2行,0的话就是存在且更新前后值一样。是不是很不好理解?
其实,你要这样想就好了,这是为了区分到底是插入了还是更新了,返回1表示插入成功,2表示更新成功。
解决方案
将innodb_autoinc_lock_mode设置为0肯定可以解决问题,但这样的话,插入的并发性可能会受很大影响,因此小A自己想着DBA也不会同意。经过考虑,目前准备了两种较为可能的解决方案:
修改业务逻辑
修改业务逻辑,将INSERT ... ON DUPLICATE KEY UPDATE ...语句拆开,先去查询,然后去更新,这样就可以保证主键不会不受控制的增大,但增加了复杂性,原来的一次请求可能变为两次,先查询有没有,然后去更新。
删除表的自增主键
删除自增主键,让唯一索引来做主键,这样子基本不用做什么变动,只要确定目前的自增主键没有实际的用处即可,这样的话,插入删除的时候可能会影响效率,但对于查询多的情况来说,小A比较两种之后更愿意选择后者。
结语
其实INSERT ... ON DUPLICATE KEY UPDATE ...这个影响行数是2的,小A很早就发现了,只是没有保持好奇心,不以为然罢了,没有深究其中的问题,这深究就起来会带出来一大串新知识,挺好,看来小A还是要对外界保持好奇心,保持敏感,这样才会有进步。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流
这篇关于mysql自增id超大问题的排查与解决的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





