自增专题

ORACLE设置表ID自增
1、创建表 create table note( id number(20) NOT NULL primary key,/*主键,自动增加*/ name varchar2(20)); 12 2、创建自动增长序列 Create Sequence addAuto_Sequence Increment by 1 -- 每次加几个 start with

vue el-tree主键id重复 添加自增id 以及原相同节点同步勾选 同步操作
树数据只提供了nodeId,且存在不同节点重复nodeId的问题,由于树组件的node-key需要唯一性,所有这个时候我们需要给数据添加自增id (延申问题:操作某个节点的时候,同步操作与他nodeId相同的节点),代码如下 <template><div><el-tree:data="treeList"show-checkboxref="tree":check-strictly="false"n

订单类业务创建自增编码
未对线程安全进行校验(因为后面发现有方法可以直接调用,没有使用自己写的) package com.tiansu.nts.cds.service.util;import cn.hutool.core.collection.CollUtil;import cn.hutool.core.util.StrUtil;import lombok.extern.slf4j.Slf4j;import jav
java使用本地缓存,每天获取新的从0开始自增流水号
要在本地缓存中管理每天自增的流水号,可以采用以下步骤实现: 1、初始化流水号: 在一天的开始时将流水号设置为0。 可以通过时间存储流水号: 2、使用本地缓存如java.util.concurrent.ConcurrentHas存储流水号: 使用本地缓存如java.util.concurrent.ConcurrentHashMap来存储流水号。
Postgresql自增
今天研究了一下postgresql数据库,在定义用户id的时候想着让其从10000自增,百度了一下,方法如下: 设置id为自增序列: CREATE TABLE test( id SERIAL primary key , )设置从10000开始自增: select setval('test_id_seq',10000,false);
两种mysql对自增id重新从1排序的方法
本文介绍了两种mysql对自增id重新从1排序的方法,简少了对于某个项目初始化数据的工作量,感兴趣的朋友可以参考下 最近老是要为现在这个项目初始化数据,搞的很头疼,而且数据库的Id自增越来越大,要让自增重新从1开始:那么就用下面的方法吧: 方法一:如果曾经的数据都不需要的话,可以直接清空所有数据,并将自增字段恢复从1开始计数 truncate table 表名 方法二:dbcccheckid
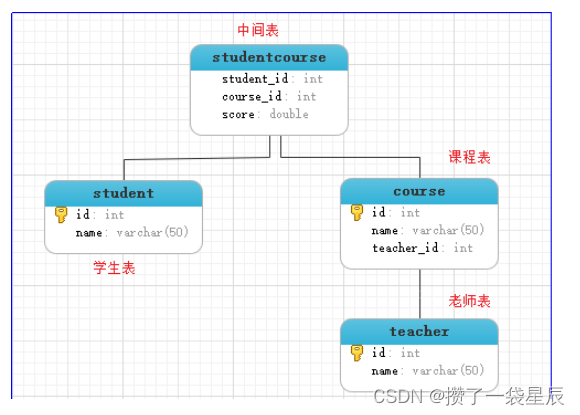
Mysql数据库约束的概述 , 逐渐约束 , 主键自增 , 表关系的概念和外键 ,多表关系约束介绍和使用
约束和表设计 1、DQL查询语句-limit语句(掌握) 目标 能够掌握limit语句的使用 讲解 作用: LIMIT是限制的意思,所以LIMIT`的作用就是限制查询记录的条数。 LIMIT语句格式: select * from 表名 limit offset, row_count;mysql中limit的用法:返回前几条或者中间某几行数据-- 1 表示分页查询的索引,对应数

oracle建表设置主键自增
首先创建一张表 create table member( memberId number primary key, memberMail varchar2(20)not null, memberName varchar2(20) not null, memberPassword varchar2(20) ); 然后,你需要一个自定义的sequenceCREATE SEQUENCE em
自定义id自增的一种方式-辅助表
对于id自增的实现,数据库提供其自增策略,首先我们需要明白为什么需要自增id,我觉得有以下几个原因: 1、id的管理变得简单,由数据库进行维护 2、id具有唯一性,满足主键的定义,通常作为主键使用 明白了自增id的好处,那么我们如何自定义id自增呢? 下面实现的方法中使用到了辅助表: id_help
关于Mysql 的on duplicate key update操作,导致主键不连续自增的问题
一 相关说明 在实际的开发中,经常会遇到这样的场景:若数据库里面不存在数据,则插入;若存在,则更新。在Mysql中,可以使用ON DUPLICATE KEY UPDATE,一步就能完成上述操作。简单说,就是数据库中存在某个记录时,执行这个语句会更新,而不存在这条记录时,就会插入。 需要说明的是该语句是基于唯一索引或主键使用,比如字段加上了unique index,如
添加一条数据后,如何获得新增加数据自增id的值
public int insertDemo(int uid){int flag=0;String sql="insert into capsule (userid) values("+uid+")";try{con=util.openConnection();Statement st=con.createStatement();//使用JDBC 3.0 getGeneratedKeys st.ex
Twitter的分布式自增ID算法snowflake - C#版
概述 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的。有些时候我们希望能使用一种简单一些的ID,并且希望ID能够按照时间有序生成。而twitter的snowflake解决了这种需求,最初Twitter把存储系统从MySQL迁移到Cassandra,因为Cassandra没有顺序I
mysql数据库删除数据后,数据自增id断点不连续
mysql数据库表"friends"中id设置主键自增,删除结尾处数据后,重新插值字段id取值不连续,解决方法: alter table friends AUTO_INCREMENT=10;(此处10改为自己的断点即可)
Sql server 中暂停与恢复主键自增
identity用法: create table [table] ( [id] int primary key IDENTITY(100,1), [name] text ) id从100开始自动序列增加,在插入数据的时候不需要填写ID的数据。如果不填写种子和自增量,默认从1开始。 重置identity种子: DBCC CHECKIDENT([table], RESEED, 999)
Mybatis在执行insert语句返回自增主键
<insert id="add" parameterType="student"> <selectKey resultType="java.lang.Short" order="AFTER" keyProperty="id"> SELECT LAST_INSERT_ID() AS id </selectKey> 或者(

mysql自增id超大问题的排查与解决
这篇文章主要给大家介绍了关于mysql自增id超大问题的排查与解决方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 引言 小A正在balabala写代码呢,DBA小B突然发来了一条消息,“快看看你的用户特定信息表T,里面的主键,也就是自增id,都到16亿了,这才多久,在这样下去过不了多久主键就要超出范围了,插入就会失败,
mysql数据库 自增id从指定数字开始
如果想要给每个用户一个七或者更多位数的uid,可以在用户表中设置id为自增,并且设置初始值 1.创建表时指定 CREATE TABLE user( -- 建表语句 )AUTO_INCTEMENT=自增值; 例如 create table user(id int unsigned primary key auto_increment comment 'ID',pho
前置和后置自增以及解引用重载函数(++、--、*)
#include<iostream> using namespace std; class INT { private: int m_i; public: INT(int i):m_i(i){} // 区分前置和后置自增重载函数的区别是是否有参数,以及参数的个数 // 如果是前置自增,比如++a,因为++符号前面

Xcode打包,仅archive时通过Run Script脚本进行build号自增
Run Script脚本 不知Xcode如何添加shell脚本?请看文章结尾^_^ 网上一般都是release模式下build号自增,这里是根据archive进行的(每次打包build号++),大同小异,看实际需要吧,直接上代码了 if [ $ACTION == install ]; thenecho "Bumping build number..."echo $ACTIONplist
Mybatis generator 添加记录时返回自增主键
在generator config文件配置table时修改: <table tableName="rc_template"><generatedKey column="ID" sqlStatement="MySql" identity="true"/></table>
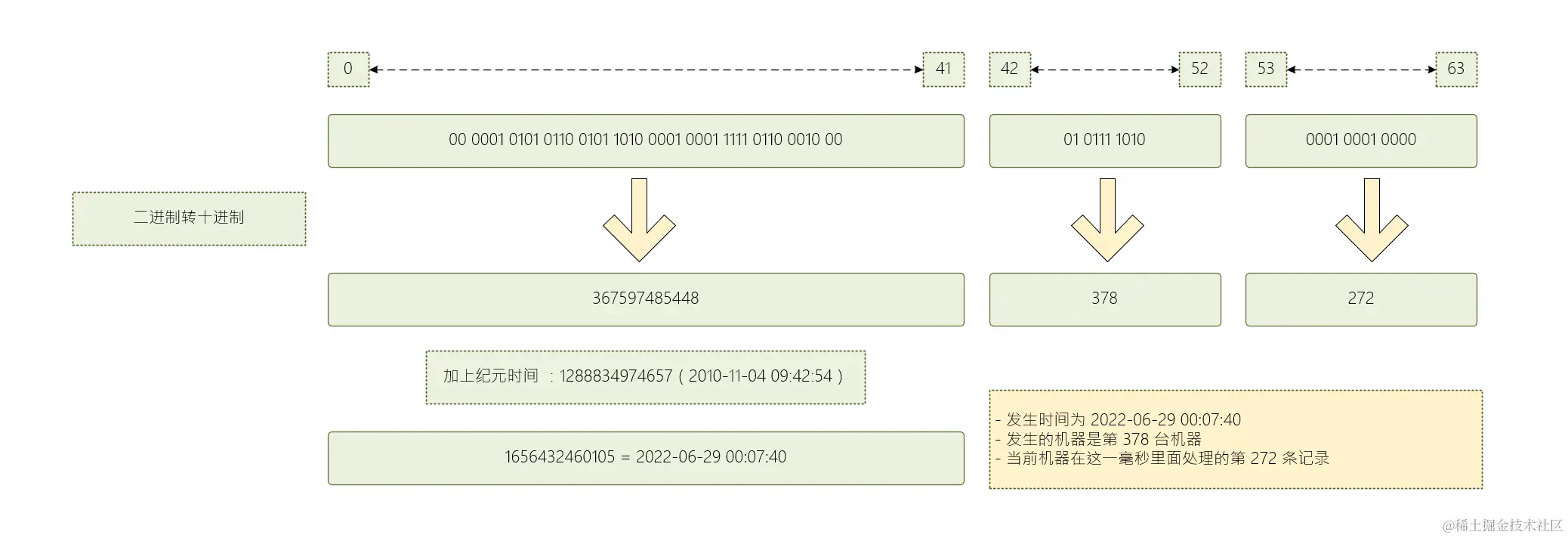
微服务+分库分表的自增主键ID该如何设计?
一. 前言 分布式ID 是分布式系统里面非常重要的一个组成部分,那么我们在设计分布式ID的时候,需要考虑什么问题呢? ❓简单结构下是怎么实现 ID 的控制的? 单实例系统 :通过时间戳,系统内自增,上锁等方式保证ID的唯一性 单数据库实例 : 通过自增字段(不谈性能)实现ID的唯一 ❓微服务 + 分库分表了 ,又该如何进行控制? 问题 : 单个系统没办法直接感知到其他系统的ID情况,
Mybatis 在 insert 之后想获取自增的主键 id
1.在mapper.xml中:useGeneratedKeys=“true” keyProperty=“id”,这两个属性的作用: 共同决定了sql执行后,会将主键封装到id属性上; 自增主键封装到了对象的id属性上了,那么想要获取,直接调用对象的getId()方法就可以了 <insert id="insert" parameterType="" useGeneratedKeys="true

十四、【源码】SelectKey返回Insert操作自增索引值
源码地址:https://github.com/mybatis/mybatis-3/ 仓库地址:https://gitcode.net/qq_42665745/mybatis/-/tree/14-selectKey 返回Insert操作自增索引值 分为两部分,解析初始化和使用 拿含有selectkey标签的insert语句解析来说 1.解析部分 解析时看有没有selectkey标签,有
MybatisPlus添加数据自增主键失效,mysql自增主键失效
1、问题概述? 情况1:mysql数据库设置了自增主键,但是添加的时候,出现了长串的负数或者正数id,如:-109096962。 情况2:mysql数据库设置了自增主键,但是添加的时候,对象中的id有值,这个是在添加的时候会生效。 2、解决办法? 解决办法总体比较简单 【注意点1:@TableId(value = "id",type = IdType.AUTO)】 AUTO(0, “数
Java的中间缓存变量机制与自增操作符
一大早起来,本想做个小题练练手,没想到居然被难住了!!先把题目贴上,各位先做做看: 求输出结果 1.public static void main(String[] args){ int j=0; for (int i = 0; i < 100; i++) { j = j++; } System.out.println(j); 2. [java] view plain cop
达梦判断哪列是自增列|查询自增信息|重构自增列|自增改为sequence
### Code Reference URL:p115 DM8系统管理员手册DESC:达梦判断哪列是自增列|查询自增信息|重构自增列|自增改为sequenceLast Update:2020-7-1 10:58 判断自增列 left JOIN (SELECT * FROM syscolumns t WHERE id = (SELECT object_id FROM dba_objects t