本文主要是介绍微服务+分库分表的自增主键ID该如何设计?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一. 前言
分布式ID 是分布式系统里面非常重要的一个组成部分,那么我们在设计分布式ID的时候,需要考虑什么问题呢?
-
❓简单结构下是怎么实现 ID 的控制的?
-
单实例系统 :通过时间戳,系统内自增,上锁等方式保证ID的唯一性
-
单数据库实例 : 通过自增字段(不谈性能)实现ID的唯一
-
❓微服务 + 分库分表了 ,又该如何进行控制?
-
问题 : 单个系统没办法
直接感知到其他系统的ID情况,哪怕通信也要付出极大的代价
二. 来理解分布式ID的原则
2.1 分布式 ID 的本质是什么 ?
-
全局唯一 : 要保证的是在任何场景下,任何系统,任何库,同一业务场景中生成的ID一定是唯一的
-
递增 : 有的文章里面会谈到单调递增和趋势递增,这讲到的是2个维度:
-
一个要求ID是有序增长的(
趋势递增 ,用于排序) -
一个是要求ID是正向增长的(
单调递增 ,下一个一定比上一个大) -
无规则 : 无规则是指不能按照MySQL主键自增这种方式进行 + 1 自增,简单的自增方式会带来安全层面的风险
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。这是大佬写的,7701页的BAT大佬写的刷题笔记,让我offer拿到手软
2.2 有哪些相同性质的问题?
对于分布式 ID 的实现 ,在某些思路上和很多业务是通用的 ,例如 :
- 订单编号的生成逻辑 :有序 + 反映时间
- 券码的生成逻辑 : 有序 + 不可推测
- 动态码 : 付款码,会员动态码等等
这些码的生产一般都会包含上述的2项原则,一定会要求全局唯一 ,同时根据情况来进行有序或者无序的控制。
其实无序一般也是看起来无序,在底层逻辑的生成上不可能完全无序,否则总会出现冲突的场景。
2.3 分布式 ID 的根本实现方式是什么 ?
ID的生成本质上只需要关注两个核心 :
- 区域的划分 :我们需要保证每台机器是一个固定的区域 ,一般称之为机器ID
- 锁的控制 : 不止是不同服务之间的分布式锁,还包括同一个服务的线程锁
来简单解读下 ,服务之间的通信很消耗资源 ,所以能不通信实现分布式ID的生成效率是最高的 , 那么一般会在服务启动的时候就计算出对应的工作区间。
同时要理解的是 ,锁往往和性能是对立关系,锁越多 ,则性能会相对越差,所以如何控制锁的粒度,则是分布式ID生成的一大核心。
三. 来探讨一下实现的思路
3.1 常规的分布式ID 算法
可用但是有限制的方案
// 简易版 - 基于时间戳的ID算法 :
- 方案 : 使用时间戳作为ID的前缀,然后通过机器的IP地址或MAC地址进行哈希计算得到剩余部分
- 问题 : 过于简单 , 只能实现单机毫秒级的并发
// 低效版 - 数据库自增
- 方案 : 没有方案 ,交给数据库来
- 问题 : 性能低 , 不支持分库分表
// 升级版 - 基于UUID
- 方案 :- 基于时间的UUID:主要依赖当前的时间戳及机器mac地址,因此可以保证全球唯一性- 分布式安全的UUID:将版本1的时间戳前四位换为POSIX的UID或GID- 基于随机数的UUID:基于随机数或伪随机数生成- 基于名字空间的UUID(MD5版):基于指定的名字空间/名字生成MD5散列值得到
- 问题 : 长度过长 ,无序 ,不可读常规的方案 :
- ❓ 基于雪花算法的ID算法:
雪花算法是由Twitter开发的一种分布式ID算法,它由几部分组成:时间戳、数据中心ID和机器ID以及序列ID。该算法可以保证ID的唯一性和稳定性,但需要较为复杂的计算和管理。
- ❓ 基于LeaseSet的ID算法
LeaseSet是一种分布式ID系统,它通过将ID划分为多个片段,然后将这些片段分配给不同的机器来生成ID。该算法可以实现高可用和可扩展性,但需要较为复杂的实现和管理。
- ❓ 总结一下 :
雪花ID一般是常见的分布式ID的方案 ,很多厂商都有这种算法的变种,操作灵活性能也比较理想。我生成主键ID时就是这种方案。
而通过分段的方案性能会很高,会在分布式锁的基础上 一次拿多个ID序列 ,然后在本地消耗这些ID序列。
比如生成订单码的时候 ,会一次性取出100个码,然后本地(单机上)逐步使用这些码。
雪花ID比较通用 。分段方式性能会更好,有序性会更强,毕竟都是连着的。
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。这是大佬写的,7701页的BAT大佬写的刷题笔记,让我offer拿到手软
四. 分布式 ID 的简化方案
不同的业务场景对于分布式ID的要求不同 ,所以这里不说业务相关的,只谈实现流程,也没有什么代码
4.1 为你的 ID 定义格式
-
起始位 : 起始位一般都是 1 ,在日常使用中一般不会变动,除非系统发生了整体的重做又需要保留之前数据时 ,才可以考虑通过这个来进行扩展
-
总长度 : 位数一般基于具体的业务场景 , 和关联的内容以及数据总量息息相关。
-
案例一 : 内含时间戳 ,一般 ID 里面会包含一个毫秒精度的时间戳,具体看业务
-
案例二 : 插入随机数 ,在并发比较高的情况下 ,则需要通过随机数减少ID冲突的概率
-
总结 : 一般情况下都是 64 位的纯数字 ,短了信息少,并发低。 长了浪费空间,浪费性能,库不支持。
-
机器ID : 用来描述对应的服务器 , 一般支持1024位(也就是 1024台服务器,大多数情况下够用了)
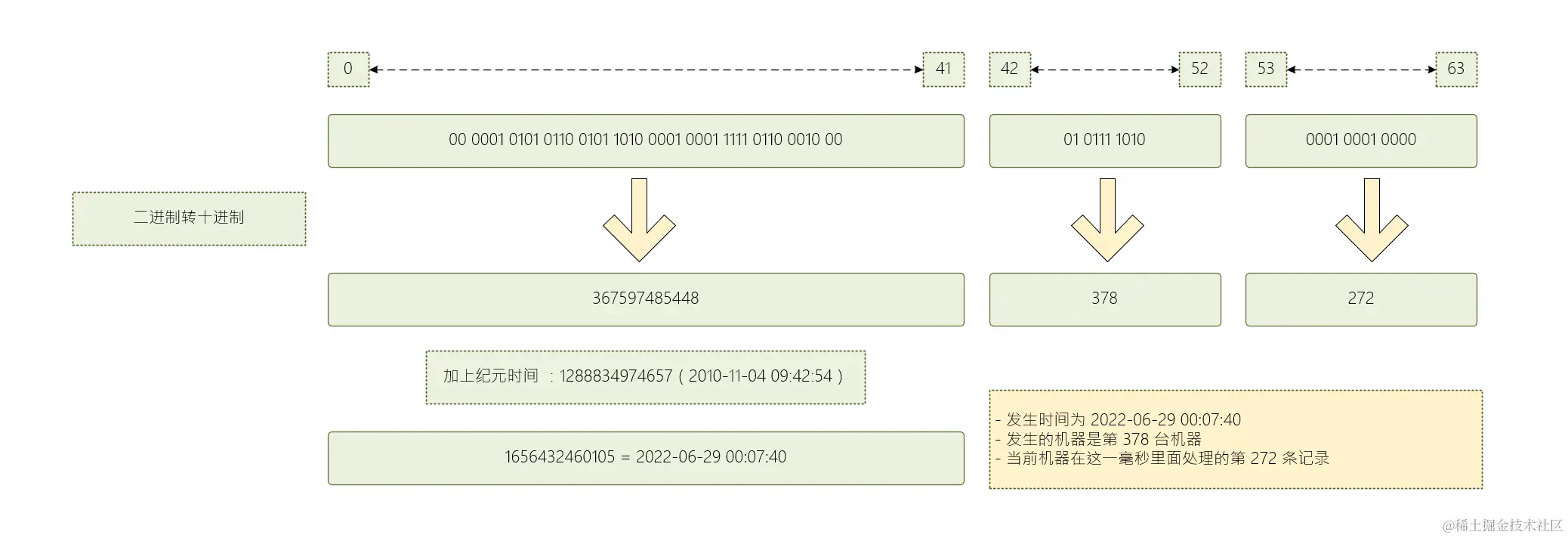
👉 来看一下最常见的雪花算法的格式 :
0 41 51 64
+---------------------------------------+------+-----------+
| 时间戳(以毫秒为单位) |机器ID| 递增数 |
+---------------------------------------+------+-----------+
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。这是大佬写的,7701页的BAT大佬写的刷题笔记,让我offer拿到手软
👉 来解析下里面的一些具体的细节 :
❓问题一 : 关于时间戳从什么时候开始
一般我们看到的雪花算法都会以当前时间减去过去一个纪元时间 (参考时间点), 有的可能是 1970 年 1 月 1 日 00:00:00 , 有的可能是上线时间或者一个特殊的时间点。
通过这种方式既可以减少整体的长度,让数据变得紧凑 。又可以混淆 ID 的含义,让ID 没有那么容易被解析。
比如上面那个案例 , 可以看到最开始还空了4位数 ,所以时间戳的总空间是一定够的
❓问题二 : 关于机器ID
机器ID 的目的主要是为了区别不同的机器,从而避免在不同机器上面生成的数据冲突,一般都是通过分布式锁的方式来启动时获取 :
- Redis 原子获取 : 适用于服务器Pod数不高的场景,启动不频繁,流程比较规范的情况下,用 Redis 完全是足够的
- 数据库自增 : 一般这些ID的获取都是在系统启动时完成,所以数据库里面通过自增键去做也能实现我们的需求
- Zookeeper : Zookeeper持久顺序节点的特性也可以实现类似的功能
这3种方式也是传统的分布式锁的获取方式 ,通过自增这种实现保证机器ID每个都不一样。
但是需要避免下面几个问题 :
- 集群过大或者不同业务使用了同一个表生成 (机器ID一般就1024 ,超过了需要从 0 开始,一般是取模的方式)
- 避免某个节点长期不重启带来的机器ID冲突
- 避免某个机器频繁的重启导致机器ID被击穿
❓问题三 : 关于 sequence 序列ID
重点一 : sequence ID 是先要比对时间戳的 ,时间戳一样这个值才会增加
重点二 : 注意并发的影响 ,要么在生成 ID 的方法上添加 synchronized 控制并发 ,要么使用原子变量
❓问题四 : 时钟回拨 切记切记
由于上述的分布式 ID 是基于时间来实现的,这种方案最大的问题在于时钟回拨,如果服务器的时间回滚了,而机器又没重启 ,就可能会出现ID的冲突。
也有相关的解决方案 ,最常见的就是启动时校验时钟,比较其他的机器上的时间,方案就不详述了。
再一个就是换种思路 ,时间不是依赖的系统时间 ,而是一个自增的时间位。 这个是百度那边的一种算法,下一章单独讲。
最后总结: ❗❗❗❗
位数不是绝对 ,在保持64位总长度的情况下 ,机器ID 和 最后的自增数都可以随便调节。
包括整体的 64 位也不是完全绝对的 ,业务不同比 64 小几位也完全是可以的。
4.2 简单的实现方案
// S1 : 不管用什么方案 ,Redis 原子自增什么的,拿到一个 机器ID
public long getMechineId() {// 伪代码,方案自寻return redisService.incr("MECHINE_ID:" + prefixName);
}
// S2 : 构建分布式ID
private static Long lastTimestamp;// 注意并发问题 ,加锁或者原子变量
public static synchronized long buildId(){long timestamp = System.currentTimeMillis();// 如果时间一致 ,则需要增加 sequenceIDif (lastTimestamp == timestamp) {sequence = sequence + 1L & 1023L;} else {// 瞎写的 ,目的就是拿到一个 ID ,从 0 开始也可以sequence = (long)random.nextInt(128);}// 设置时间戳为最新时间戳lastTimestamp = timestamp;// tenantCode 是初始位 ,可以是0 ,也可以是 1// 如果为 0 则可能导致 ID 长度不统一 ,所以这里要根据具体的情况去设置// - 这里偏移多少位取决于后续的 sequence 想要留多少空间 ,只要时间戳偏移不要超过总数就行// - MechineId 留了 10 位 ,也就是 1024 个机器// - sequence 留了 12位 ,也就是每毫秒 4095 个return tenantCode << 60 | timestamp - 1288834974657L << 22 | getMechineId() << 12 | sequence;
}// S3 : 入库时使用
略 ,这就不用说了吧 ,写数据库的时候设置到ID里面就行了
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。这是大佬写的,7701页的BAT大佬写的刷题笔记,让我offer拿到手软
这篇关于微服务+分库分表的自增主键ID该如何设计?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








