读后专题

为什么我只查一行的语句,也执行这么慢?读后总结
sql执行慢的常见原因:mysql压力大,CPU占用率高,IO利用率高。这不属于今天讨论的范围。 造表与造数据的语句 mysql> CREATE TABLE t ( id int(11) NOT NULL, c int(11) DEFAULT NULL, PRIMARY KEY (id) ) ENGINE=InnoDB; delimiter ;; create procedure idata(

为什么这些sql语句逻辑相同,性能却差异巨大读后总结
1.条件字段函数操作 例子有一张日志表,查询 指定年限7月的记录总数 mysql> CREATE TABLE tradelog ( id int(11) NOT NULL, tradeid varchar(32) DEFAULT NULL, operator int(11) DEFAULT NULL, t_modified datetime DEFAULT NULL, PRIMARY KEY (i
如何正确地显示随机消息?读后总结
背景:有个单词表,随机显示3个单词 建表语句与初始化语句 mysql> CREATE TABLE words ( id int(11) NOT NULL AUTO_INCREMENT, word varchar(64) DEFAULT NULL, PRIMARY KEY (id) ) ENGINE=InnoDB; delimiter ;; create procedure idata() beg

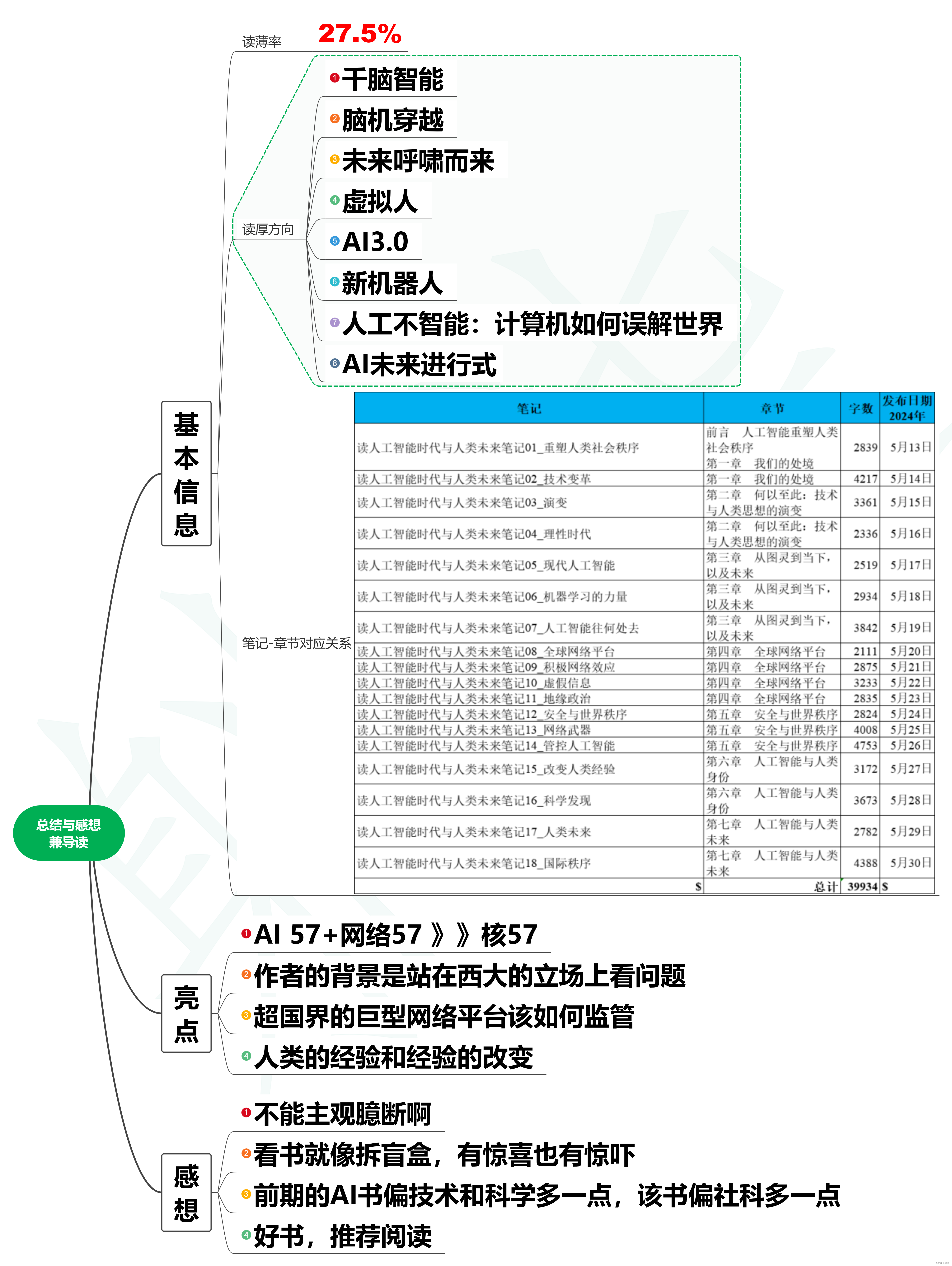
读人工智能时代与人类未来笔记19_读后总结与感想兼导读
1. 基本信息 人工智能时代与人类未来 (美)亨利·基辛格,(美)埃里克·施密特,(美)丹尼尔·胡滕洛赫尔 著 中信出版社,2023年6月出版 1.1. 读薄率 书籍总字数145千字,笔记总字数39934字。 读薄率39934÷145000≈27.5% 1.2. 读厚方向 千脑智能 脑机穿越 未来呼啸而来 虚拟人 AI3.0 新机器人 人工不智能:计算机如何误解世

人工智能的未来-读后笔记(经典语录)
读完《人工智能的未来》一书(作者:杰夫·霍金斯)后,给了我很多很多的启发,在此列举觉得非常有启发的语录如下: 1. 关注内在思想,而不是外在行为 2. 有了合适的大框架,细节才会有意义、可操控。 3. 不同的大脑皮层区域有着一个相同的、强大的通用算法,如果将这些区域按照合适的层级结构连接起来并输入信息流,它就能学会了解周围的环境 4. 大脑不需要“计算”问题的答案,它只是从记忆中取出答案。整个大
usb设备的描述符和命令--读后解
在USB设备中,主要的工作部分为主机和设备之前数据传输过程,其中包含描述符(如,设备,配置,字符串,接口,端点描述符),具体如下 在USB设备枚举过程中,主机端的协义软件需要解析从USB设备读取的所有描述符信息。在USB主向设备发送读取描述符的请求后,USB设备将所有的描述符以连续的数据流方式传输给USB主机。主机从第一个读到的字符开始,根据双方规定好的数据格式,顺序地解
《代码整洁之道》读后总结--关于方法
1.几个问题: Q1: 怎样让代码(函数中含有大量的代码行,大量的信息)易于理解? Q2: 怎样让函数表达其意图? Q3: 给函数哪些属性,以便让读者一看便明白函数术语怎样的程序? 2.简单的原则: 2.1. 短小 作者认为函数应该尽量短小。每行字符的数量要有限, 并且 每个 函数20行 封顶最佳。(建议)if语句 , else 语句, while语句中等, 代码块应该

《一句顶一万句》—— 读后总结
最开始看这本小说,以为是讲述了一句可以概括人生的哲理,其实不然! 本书以朴实无华的笔风,像讲述家常一样,透过简单的故事,映射出人生的很多哲理。最开始看的时候,略觉得墨迹无趣,但是没看完一个故事情节,便觉得在生活中有现实可套,觉得现实生活中便真的是如此啊,原来很多事情是这般缘由。 这本书可以堪称是中国人情事故的示例教材,很多人活的很累,也许自己不知道是因为什么,但是看看本书,从别人的
UNIX环境高级编程第三章文件I/O 读后笔记
昨天读了UNIX环境高级编程第三章:文件I/O,现记录一下读书笔记。 先澄清一个概念,文件描述符不是整个系统唯一的,而是对于进程来说唯一的。 该章说明的函数都是不带缓冲的I/O。它们都是属于POSIX和UNIX的组成部分,而不是ISO C的组成部分。该章介绍了open(),create(),read(),write(),来seek(), 等常用文件操作函数。需要注意的是文件
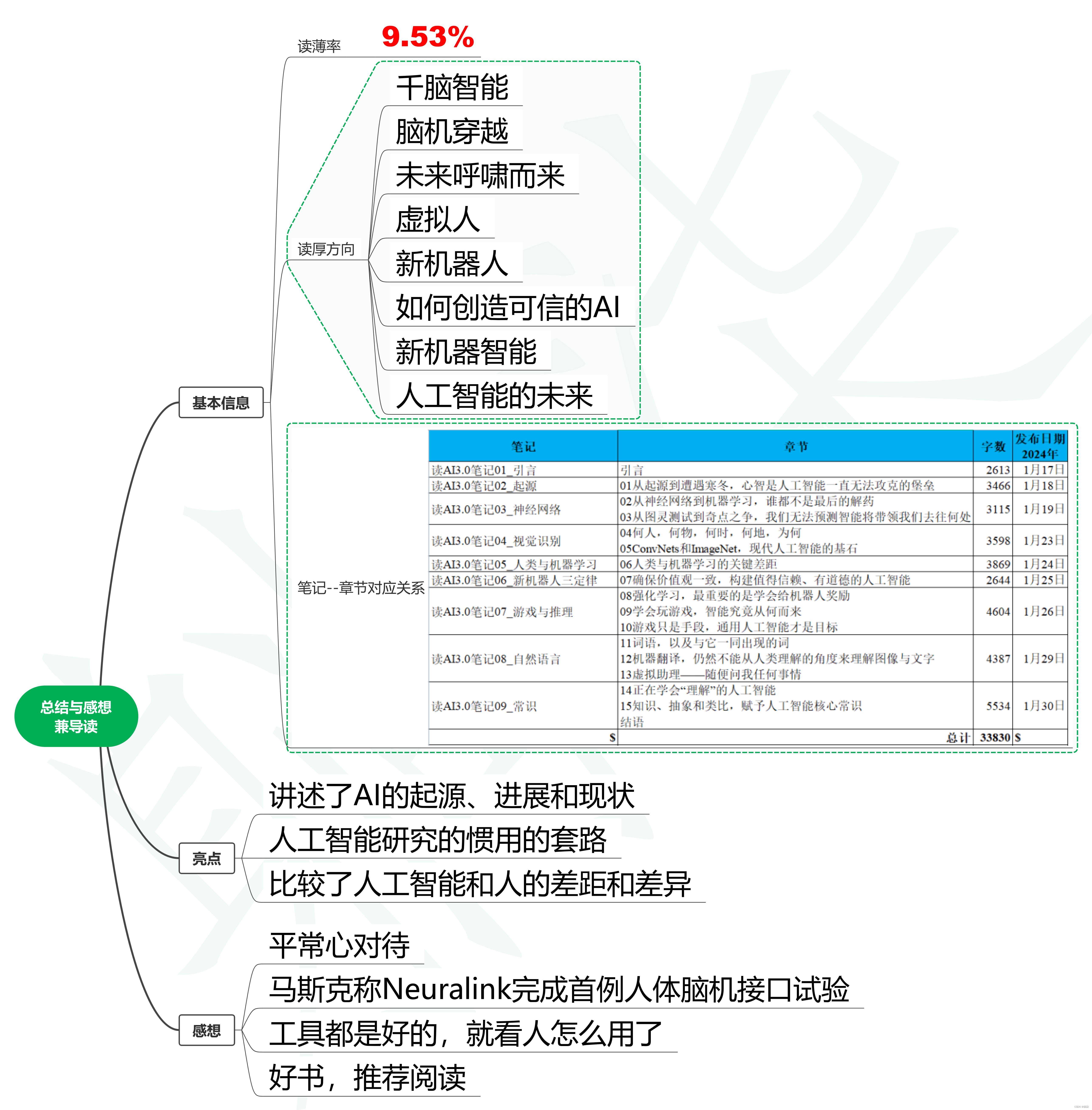
读AI3.0笔记10_读后总结与感想兼导读
1. 基本信息 AI 3.0 (美)梅拉妮·米歇尔 著 四川科学技术出版社,2021年2月出版 1.1. 读薄率 书籍总字数355千字,笔记总字数33830字。 读薄率33830÷355000≈9.53% 1.2. 读厚方向 千脑智能 脑机穿越 未来呼啸而来 虚拟人 新机器人 如何创造可信的AI 新机器智能 人工智能的未来 1.3. 笔记--章节对应关系
[Python] 先读后覆盖写文件
Python先读后覆盖写文件 只打开一次文件,先把文件内容读取出来,处理之后形成新的数据,重新写入新的数据,完成先读取后覆盖写文件。 比如有一个文件内容如下,需要将内容全转为大写然后覆盖: Now York is 3 hours ahead of California, but it does not make California slow.Someone graduated at th

Random Sample Consensus(RANSAC)的一点读后总结
RANSAC算法不同与传统的平滑过程,传统方法是利用尽可能多的数据来获得一个比较原始的解,然后尝试使用一些优化算法来消除invalid的数据点。对于RANSAC则是使用一个比较小的数据集,然后再尽可能的使用一致的数据来扩大原来初始化的数据集。 举个例子来说,如果我们要拟合一段二维点中的弧线,RANSAC会选择三个点作为一个集合(确定一个弧线需要三个点),然后计算中心和半径,也就是说这样圆的弧线就

Network in Network-读后笔记
摘要: 提出一个NIN(网络中的网络)的深度网络结构用以增强模型在感知野在局部图像块的辨别力。 提出在卷积层使用非线性代替现有的线性模型。使用一个由MLP组成的micro neural网络作为非线性模型去扫描输入以提取特征图(feature map)deep NIN就是将micro neural以栈的形式组合而成。 作者说,Deep NIN的形式相比于传统的卷积神经网络来说不易过拟合,
《产品方法论》读后的一点点感想
首先是产品层的启发 1.用户不是自然人,是需求的集合 2.情境化分析 这两点印象深刻,提供了一个独特的认识、分析需求的角度 其次是发展路径的指导 1.产品经理的关键能力是什么 2.如何培养并提升这些能力 3.前五年与五年后发展路径和侧重点 最后是一点补充 1.第一章和第五章是强相关的产品内容,是全文的核心(个人认为) 2.中间关于企业、交易、决策的部分,涉及经济学、心理学、管理学中的一
商业模式读后总结+测量项目靠谱度
商业模式的本质:企业行为就是投入和产出的过程,而企业在不同的发展阶段,在不同的经营状况下,把企业的资源已经拥有或能够拥有的资源组织起来,实现最佳的产出(或价值创造),这种组织方式就是商业模式,而商业模式设计的实质是资源优化配置的方式而已。 一个成功的商业模式不一定是在技术上的突破,而是对某一个环节的改造,或是对原有模式的重组创新,甚至是对整个游戏规则的颠覆。商业模式的核心原则是指商业模

《Effective Java》——读后总结
这本书在Java开发的行业里,颇有名气。今天总算是粗略的看完了…后面线程部分和序列化部分由于心浮气躁看的不仔细。这个月还剩下一周,慢慢总结消化。 1、静态工厂方法代替构造器 静态工厂方法有名称,能确切地描述正被返回的对象。不必每次调用都创建一个新的对象。可以返回原返回类型的任何子类对象。创建参数化类型实例时更加简洁,比如调用构造 HashMap 时,使用 Map < String,List

哥德尔命题5-命题11的两个图表 水灾 奥运——哥德尔读后之十六
哥德尔命题5-命题11的两个图表 水灾 奥运——哥德尔读后之十六 刚刚感叹一番全球天灾,完成一篇哥德尔阅读的对比图表文。休憩转换一下阅读奇怪字符的神经,听听音乐,看看美图。这几天,重又走进哥德尔之际,历史的聚焦镜头,一下子从遥远的西欧洪灾折转到了老家的邻省河南。西欧的洪水恐怕还没有退尽,在河南郑州,还有河南很大范围的城镇,却似乎是碰到了千年未遇的水难。真不知道这个世界怎么啦,可怜地铁隧道中,沉没
《社会化营销:人人参与的营销力量》—— 读后总结
2019独角兽企业重金招聘Python工程师标准>>> 现在是一个IT互联的时代,传统的营销也渐渐与互联网结合。 这本书可以让你更好的理解,现在的互联网时代中潜在的营销机会。 本书内容 本书从互联网各种应用方面入手,讲解了企业营销,结合了不少优秀的案例,很容易的体会到现代营销的魅力。 读后感悟 现在社交方面最火的,当然就是微博了,之前校内网很流行,但是也就是四五年的时间,

大型网站技术架构——读后摘要7
网站的可扩展性架构 首先了解一下扩展性、伸缩性的定义。 扩展性:指对现有系统影响最小的情况下,系统功能可持续扩展或提升的能力。表现在系统设施不需要经常更改,应用之间较少依赖的耦合,对需求变更可以敏捷响应。 伸缩性:指系统能够增加(减少)自身规模的方式增强或(减少)自己计算处理事务的能力。 降低系统耦合性的方式:分布式消息队列、分布式服务。 利用分布式消息队列降低系统的耦合性 消息

大型网站技术架构——读后摘要6
网站的伸缩性架构 网站架构的伸缩性设计 1.不同功能进行物理分离实现伸缩 每次分离都会有新的服务器加入网站来处理特定服务。 再细化: 纵向分离:将业务流程上不同部分分离部署实现系统伸缩性。横向分离:将不同的业务模块分离部署,实现伸缩性。 2.单一功能通过集群规模实现伸缩 对于用户量非常大的网站,再单一的功能一台服务器也无法满足用户量,所以以集群的方式来分担一台服务器的负

大型网站技术架构——读后摘要5
网站的高可用 网站架构分层: 应用层,服务层,数据层。 各层怎么实现高可用: 应用层:主要负责具体的业务逻辑处理,多以集群的方式解决高可用的问题。 服务层:负责提供可以复用的服务,也是以集群的方式解决高可用问题。(原因大多应用层和服务层都是部署在一起) 数据层:负责数据的存储和访问。为了保障宕机导致数据丢失,多台服务器之间进行数据同步复制,将数据写到多台服务器上,实现数据冗余备份

大型网站技术架构——读后摘要4
网站的高性能架构 网站优化第一定律:优先使用缓存。 1.性能测试 测试的方面: 响应时间(注意瞬时响应)并发数吞吐量性能计数器:指的是服务器和操作系统性能的一些数据指标。【System Load(系统负载)、对象与线程数、内存使用、CPU使用、磁盘与网络I/O等指标】 2.Web前端性能优化 浏览器访问优化: 减少Http请求使用浏览器缓存启用压缩CSS放在页面最上

大型网站技术架构——读后摘要2
网站架构模式 分层: 1.应用层:负责具体业务和视图的展示,如网站首页及收索输入和结果展示。 2.服务层:为应用层提供服务支持,如用户管理服务、购物车服务。 3.数据层:提供数据存储访问服务,如数据库、缓存、文件、收索引擎等。 分布式: 对于大型网站,分层和分割的一个主要目的是为了切分后模块便于分布式部署。 将不同模块部署在不同服务器上,通过远程调用协通工作。换句话说:

大型网站技术架构——读后摘要1
第一章:大型网站架构演化 大型互联网应用系统特点: 高并发、大流量。需要面对高并发用户,大流量访问。高可用。不会宕机、或者大bug。海量数据。需要存储、管理海量数据,需要使用大量服务器。用户分布广泛,网络情况复杂。安全环境恶劣。开放性高,用户量大导致会有黑客攻击、信息泄露等问题。需要快速变更,发布频繁。为了适应市场与客户需求。渐进式发展。由单一到复杂,一步一步来。 大型网站的演变过程:
《流程管理》第3版读后
在路上看完王玉荣的《流程管理》第3版,总体感觉写的很简单,都是基本概念的介绍,没有深入,所以没有惊喜。但是这本书有个很大的优点,就是脉络非常的清晰:第一章是流程的基本概念,里面提到了流程的六要素,非常好(在这点上我们写得更赞,因为例子);第二章是什么是端到端的流程并介绍了流程的分类(核心流程、辅助流程和管理流程);第三章是如何衡量流程,很简单,对客户实现增值即客户愿意掏钱;第四章是定义流程的原则,