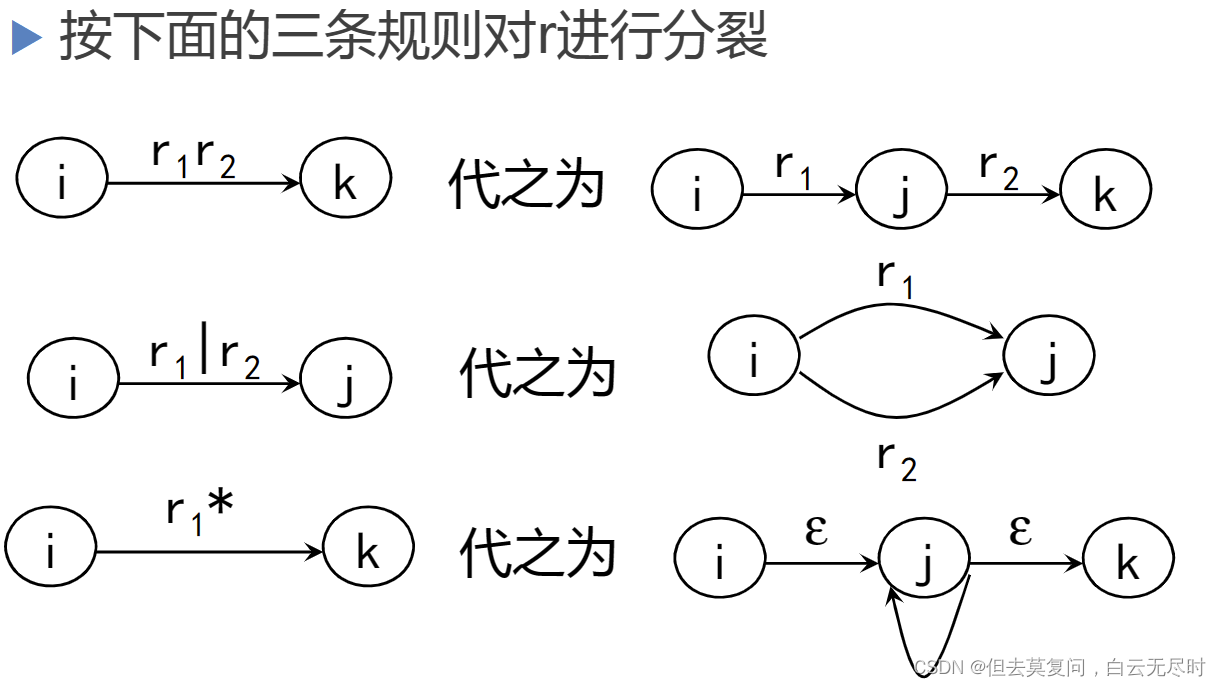
语法分析专题

Java | Leetcode Java题解之第385题迷你语法分析器
题目: 题解: class Solution {public NestedInteger deserialize(String s) {if (s.charAt(0) != '[') {return new NestedInteger(Integer.parseInt(s));}Deque<NestedInteger> stack = new ArrayDeque<NestedIntege

Golang | Leetcode Golang题解之第385题迷你语法分析器
题目: 题解: func deserialize(s string) *NestedInteger {index := 0var dfs func() *NestedIntegerdfs = func() *NestedInteger {ni := &NestedInteger{}if s[index] == '[' {index++for s[index] != ']' {ni.Add(

Python | Leetcode Python题解之第385题迷你语法分析器
题目: 题解: class Solution:def deserialize(self, s: str) -> NestedInteger:index = 0def dfs() -> NestedInteger:nonlocal indexif s[index] == '[':index += 1ni = NestedInteger()while s[index] != ']':ni.ad

梧桐数据库(WuTongDB):语法分析工具 PLY 详解
PLY (Python Lex-Yacc) 详解 PLY 是一个纯 Python 实现的词法分析器和语法分析器生成器,灵感来自经典的 Lex 和 Yacc 工具。它特别适合 Python 开发者,用于构建解析器、编译器、解释器和其他语言处理工具。 主要功能与特点 纯 Python 实现 PLY 是完全用 Python 编写的,这意味着它没有依赖于外部库,且非常适合 Python 环境下的项

梧桐数据库(WuTongDB):语法分析工具 ANTLR 详解
ANTLR (ANother Tool for Language Recognition) 详解 ANTLR 是一个广泛使用的语法分析工具,主要用于创建编译器、解释器、数据转换器和其他与语言相关的应用程序。它最初由 Terence Parr 开发,现在被广泛应用于各种编程语言和 DSL(领域特定语言)的开发中。ANTLR 通过生成解析器来处理语言的语法结构,支持自定义语言语法并自动生成相应的解析

【PL理论深化】(2) 语法分析 (Syntax) | 编程语言的语法结构:文法 | 语义结构 (Sematics)
💬 写在前面:编程语言是由归纳法生成的程序的集合。定义属于该语言的程序的形式的规则,即编写程序的规则,称为编程语言的 语法分析 (syntax) 而定义属于该语言的程序的意义的规则称为 语义结构(semantics)。这两者都是归纳定义的。 目录 0x00 语法分析(syntax analysis) 0x01 编程语言的语法结构:文法(grammar) 0x02 语义结构(Seman
预测分析法进行语法分析(编译原理)
预测分析法是一种表驱动的方法,它由下推栈,预测分析表和控制程序组成。实际上是一种下推自动机的实现模型。预测分析法的关键为预测分析表的构建,即文法中各非终结符first集和follow集的求得。预测分析法从开始符号开始,根据当前句型的最左边的非终结符和分析串中的当前符号,查预测分析表确定下一步推导所要选择的产生式,最终得到输入串的最左推导,完成输入串的语法检查。 其中主要建立first集,foll
开源软件:buttonrpc (C++语法分析)
开源软件:buttonrpc (C++语法分析) 本文采用知识共享署名 4.0 国际许可协议进行许可,转载时请注明原文链接,图片在使用时请保留全部内容,可适当缩放并在引用处附上图片所在的文章链接。 C++ 语法分析 templatetypenamestd::bindstd::is_same<R, void>::valuestd::enable_ifstd::decaystd::rev
自下而上语法分析、自上而下语法分析和递归下降法、预测分析法、LL(1)和LR是什么关系
自下而上语法分析、自上而下语法分析、递归下降法、预测分析法、LL(1)和LR都是与语法分析(语法解析)相关的概念和技术。它们在编译原理中扮演着重要的角色,用于将源代码的字符流转换为语法树(或抽象语法树,AST),以便进一步的编译和优化。以下是这些概念之间的关系和各自的特点: 自上而下语法分析(Top-Down Parsing) 自上而下语法分析从开始符号开始,根据文法规则推导输入字符串。主要方


编译原理-语法分析(实验 C语言)
语法分析 1. 实验目的 编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析 2. 实验要求 利用C语言编制递归下降分析程序,并对简单语言进行语法分析 2.1 待分析的简单语言的语法 用扩充的BNF表示如下: <程序> ::= begin<语句串> end<语句串> ::= <语句> {;<语句>}<语句> ::= <赋值语句><赋值表达式> ::= I
Java实现简单词法、语法分析器
1、词法分析器实现 词法分析器是编译器中的一个关键组件,用于将源代码解析成词法单元。 词法分析器的结构与组件: 通常,词法分析器由两个主要组件构成:扫描器(Scanner)和记号流(Token Stream)。扫描器负责从源代码中读取字符流,并按照预定义的词法规则将字符流解析为词法单元。扫描器通常由一个有限自动机实现,用于根据词法规则进行状态转换,识别出不同的词法单元。 有限自动机的代码实

编译原理|第四章 自顶向下语法分析方法——知识点总结
1.什么是FIRST、FOLLOW、SELECT集 合? FIRST:A可以推出的所有式子的“第一个”非终结符! FOLLOW:3个求解规则 1.主程序Beginadvance;E;end2.E过程Procedure EBeginT;E';end3.E'过程Procedure EBeginif sym = '+' thenbeginadvance;E;ende

tinypy 语法分析过程
tinypy的文档真的很难找(也许是我搜索技术太烂了。。。),官方说它是一个python的子集,支持的功能如下: 1.类和单继承 2.可变参数和关键字参数的函数 3.字符串,列表,字典,数字 4.模块,列表解析 5.异常的回溯 6.一些内建函数 实现语法分析的源文件是parse.py tinypy采用了自顶向下算符优先分析法(Top Down Operator Pre
自顶向下语法分析方法:消除左递归
直接左递归 形如A->Aβ,A∈非终结符,β∈终结符∪非终结符。 消除直接左递归 一般形式:A->Aα1|Aα2|...|Aαm|β1|β2|...|βn其中,αi(1≤i≤m)不等于ε,βj(1≤j≤n)不以A开头,消除直接左递归改写为:A->β1A'|β2A'|...|βnA'A'->α1A'|α2A'|...|αmA'|ε 例如: 文法:S->SaS->b消除直接左
自顶向下语法分析方法:提取左公共因子
若文法中含有形如A->αβ|αγ的产生式,就会使FIRST集相交,就满足不了LL(1)文法的充分必要条件。 可以做下面的等价变换: A->αβ|αγA->α(β|γ) A->αA' 引入新的终结符A'A'->β|γ 一般形式: A->αβ1|αβ2|...|αβnA->α(β1|β2|...|βn)A->A'A'->β1|β2|...|βn 例子: 文法的产生式为:S

自顶向下语法分析方法:LL(1)文法的判别
例子:文法G[S]为 S->AB|bC A->ε|b B->ε|aD C->AD|b D->aS|c 第一步,求出能推出ε的非终结符 首先建立一个以文法的非终结符为上界的一维数组,其数组元素为非终结符,对应每一非终结符有一个标志位,用以记录能否推出ε。如下表 非终结符SABCD初值未定未定未定未定未定第1次扫描是是否第2次扫描是否 能否推出ε步骤如下: 第二步,计算FIR

软考:区分词法分析、语法分析、语义分析
考各位一个题:判断程序语句的形式是否正确属于()阶段的工作? A、词法分析 B、语法分析 C、语义分析 D、代码生成 各位填什么? 正确答案:B 词法分析(Lexical Analysis) 词法分析是编译器工作的第一个阶段,也被称为扫描(Scanning)或分词(Tokenization)。在这个阶段,编译器会读取源代码的字符流,并将其分解为一个个有意义的符号或
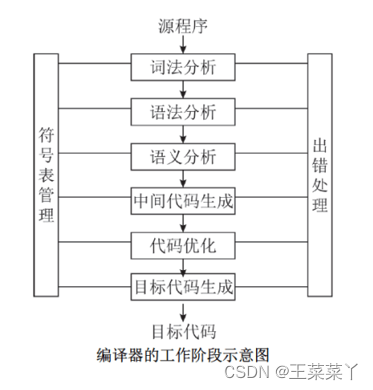
编译器如何将高级语言转换为机器码,包括词法分析、语法分析、中间代码生成和优化、代码生成等步骤。
编译器是将高级编程语言(如C++、Java等)转换成机器码(即计算机可以直接执行的指令)的软件。编译过程通常包括几个关键阶段:词法分析、语法分析、中间代码生成与优化、以及代码生成。下面详细介绍这些阶段: 词法分析(Lexical Analysis) 词法分析是编译的第一阶段,负责将源代码文本分解成一系列的记号(tokens)。这一过程涉及扫描代码并识别出构成语言基本元素的模式,如标识符、关键字
编译器的构建:词法分析、语法分析、语义分析、中间代码生成、最终的代码优化、目标代码生成
编译器的构建是一个复杂的过程,主要包括词法分析、语法分析、语义分析、中间代码生成以及最终的代码优化和目标代码生成等步骤。每个步骤承担着编译过程中的特定任务,确保源代码能够被正确地转换为目标机器能执行的代码。 1. 词法分析(Lexical Analysis) 目的:将输入的字符流(源代码)转换成一系列的记号(tokens)。这些记号是构成语言的最小单位,例如关键字、标识符、常数、运算符等。
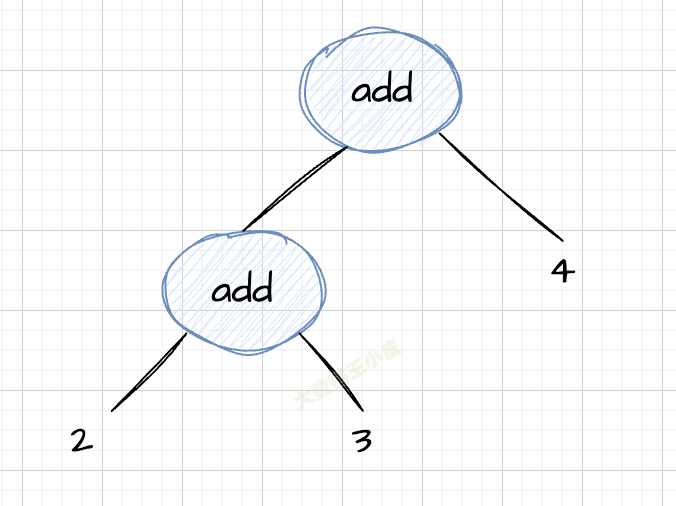
【编译原理】手工打造语法分析器
重点: 语法分析的原理递归下降算法(Recursive Descent Parsing)上下文无关文法(Context-free Grammar,CFG) 关键点: 左递归问题深度遍历求值 - 后续遍历 上一篇「词法分析器」将字符串拆分为了一个一个的 token。 本篇我们将 token 变成语法树。 一、递归下降算法 还是这个例子 int age = 45 我们给出这个语法的规则:
语法分析-自顶向上分析
语法分析-自顶向上分析 在自底向上语法分析器中,处理符号时采用的是:() A 先进先出 B 先进后出 C 后进先出 D 后进后出 正确答案:B自底向上语法分析器的输出是:() A 语法树 B 词法单元 C 符号表 D 语法规则 正确答案:ALR语法分析器中,状态机的状态是由什么组成的?() A 文法规则 B 项目 C 终结符号 D 非终结符号 正确答案:B在LR语法分析器中,什么是“可规约状态”
ANTLR中自定义语法分析过程
自定义语法分析过程 语法中嵌入动作 除了使用监听器和访问器,我们还可以手动实现对语法分析树的访问 例如要对如下三列文本进行识别,打印指定的列,例如第一列为parrt tombu bke,列之间以Tab分割 parrt Terence Parr 101 tombu Tom Burns 020 bke Kevin Edgar 008 在语法文件Rows.g4中添加一些自定义的动作,通过
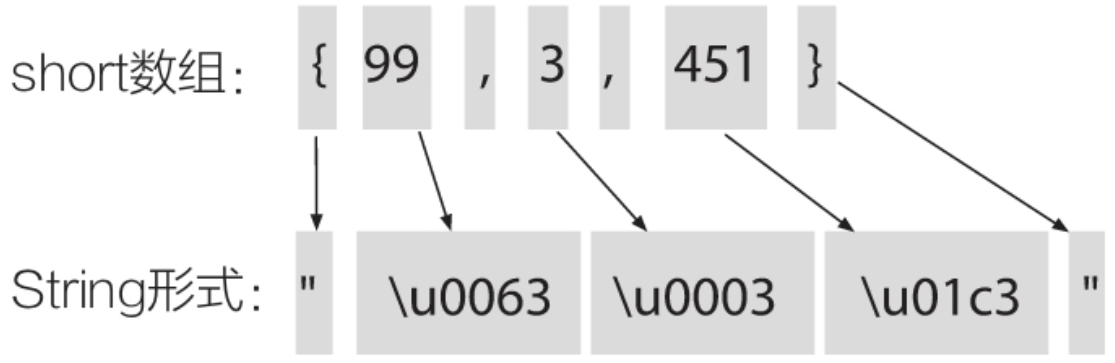
ANTLR使用监听器遍历语法分析树
在ANTLR生成语法分析树之后我们可以对其节点进行遍历,在过程中完成相应的逻辑操作。ANTLR提供了两种遍历分析树的方法–监听器和访问器,默认会生成监听器的接口和代码。利用监听器实现一个语法分析器将Java中的short数组转化为字符串,例如 short[] dataArr={1, 2, 3};String dataStr="\u0001\u0002\u0003"; //将short值看作Un
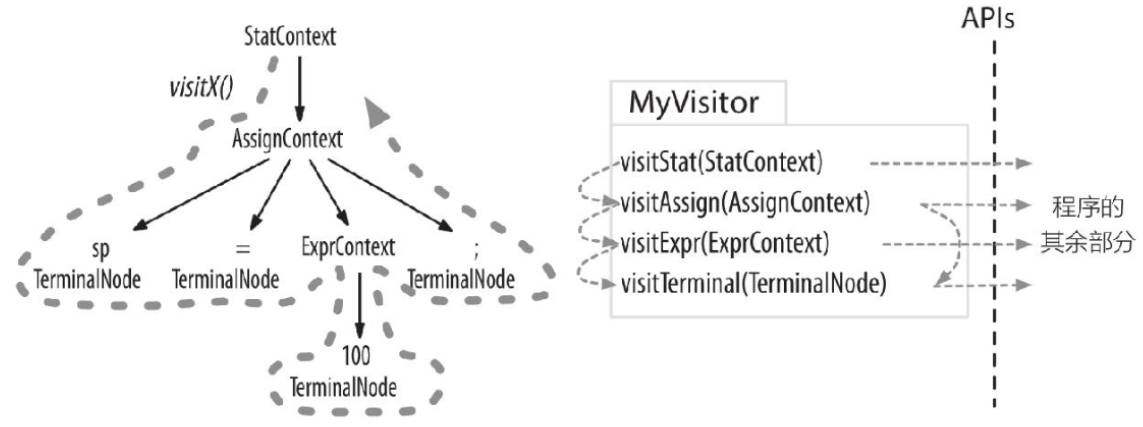
使用ANTLR进行语法分析
ANTLR(ANother Tool for Language Recognition)是一款强大的语法分析器生成工具,可用于读取、处理、执行和翻译结构化的文本或二进制文件 传统行业人员通过DSL(Domain Specific Language)将其业务知识和经验转化为计算机语言,从而借助计算机解决问题,而实现DSL的难点就在于编译器的前端。借助ANTLR可以高效准确地自动生成编译器前端,它能