本文主要是介绍使用ANTLR进行语法分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ANTLR(ANother Tool for Language Recognition)是一款强大的语法分析器生成工具,可用于读取、处理、执行和翻译结构化的文本或二进制文件
传统行业人员通过DSL(Domain Specific Language)将其业务知识和经验转化为计算机语言,从而借助计算机解决问题,而实现DSL的难点就在于编译器的前端。借助ANTLR可以高效准确地自动生成编译器前端,它能根据用户定义的语法文件自动生成词法分析器和语法分析器,并将输入文本转化为语法分析树,提高了语言识别程序的开发效率。
ANTLR 4和之前相比降低了语法中内嵌动作(代码)的重要性,取而代之的是监听器和访问器。新机制将语法和应用的逻辑代码解耦,使得应用程序本身被封装起来
1 使用ANTLR
1.1 安装
在安装antlr之前需要先安装Java并配置环境变量。
ANTLR包含两个部分:一个将语法转换为其他目标语言的解析器/词法分析器的工具,以及生成的解析器/词法分析器等运行所需的依赖库。首先对语法文件使用ANTLR工具进行编译,然后将生成的代码和运行库放在一起运行
首先从antlr官网下载antlr工具的jar包,例如antlr-4.5.3-complete.jar,其中包含了antlr的编译、运行工具和执行antlr识别程序的运行库。jar包还包含了一个树形结构生成库和生成结构化文本的模板引擎StringTemplate
将下载的jar包放在一个目录下D:\Software\lib\antlr,在该目录下创建antlr工具的批处理文件antlr4.bat,内容为:java org.antlr.v4.Tool %*;创建测试工具TestBig的批处理文件grun.bat,内容为java org.antlr.v4.gui.TestRig %*
在系统环境变量CLASSPATH中增加路径D:\Software\lib\antlr\antlr-4.5.3-complete.jar

在环境变量PATH中增加路径D:\Software\lib\antlr
在命令行输入antlr4,显示如下代表配置成功

1.2 运行并测试
首先创建一个语法解析文件Hello.g4如下
grammar Hello ; //定义一个名为Hello的语法
r : 'hello' ID ; //匹配字符串“hello”和其后的一个标识符
ID : [a-z]+ ; //匹配小写字母组成的标识符
WS : [ \t\r\n]+ -> skip; //忽略Tab、换行、空格
在该文件目录下对该语法文件运行antlr命令antlr4 Hello.g4,生成语法分析器和词法分析器相关文件如下所示
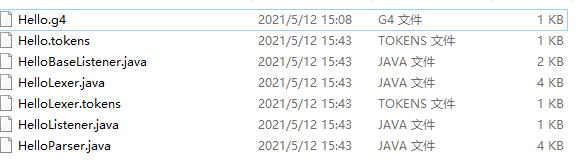
编译生成的java文件 javac *.java,生成对应的.class文件
 接下来可以使用TestBig工具对语法进行测试并查看语法匹配过程中的信息,之前我们定义了TestBig快捷启动命令
接下来可以使用TestBig工具对语法进行测试并查看语法匹配过程中的信息,之前我们定义了TestBig快捷启动命令grun,它接收一个语法文件名和其中的一个规则作为参数。此外还可以用-指定可选参数,例如
- -tokens输出词法符号流
- -tree以LISP风格打印语法分析树
- -gui可视化输出语法分析树
- -ps file.ps生成PostScript格式的语法分析树并存储到file.ps文件
- -trace 打印规则的名字与词法符号
例如通过TestBig输出词法符号流,命令行需要手动输入结束符Ctrl+z,否则会一直等待字符输入
D:\Code\antlr\demo\hello>grun Hello r -tokens # 启动TestBig,运行Hello语法中的r规则,输出词法符号流
hello tory # 输入待识别的语句
^Z # 手动输入文件结束符
[@0,0:4='hello',<1>,1:0] # @0表示为第一个词法符号,由输入文本的第0~4个字符组成,内容为‘hello’
[@1,6:9='tory',<2>,1:6]
[@2,12:11='<EOF>',<-1>,2:0]
以可视化的形式查看语法树
D:\Code\antlr\demo\hello>grun Hello r -gui
hello tory
^Z

2 ANTLR语法
2.1 构成
一门语言由一系列语句组成,语句由词汇符号组成。
解释器(Interpreter)是指可以分析计算执行语句的程序。
翻译器(Translator)可以将一门语言转换成另一门语言。
从字符流中提取单词符号的过程为词法分析(lexical analysis),词法分析器(lexer)将输入文本转化为词法符号,词法符号包含其数据类型和对应的文本。
识别语言的程序称为语法分析器(parser),句法是指各组成部分之间的约束规则。Antlr生成的语法分析器可以构造语法分析树来对语句进行分析(parse tree),语法分析树内部节点是词组名,通过分析树在程序之间传递词组构成信息,在语言翻译中,一个阶段依赖于前一个阶段的计算结果,因此需要进行多次树的遍历。
语法分析树采用“自上而下”的解析过程,从根节点开始递归下降的分析方式直到叶子节点
如下所示为antlr匹配assign方法的实现匹配“sp=100;"的过程:
// assign : ID '=' expr ';' ;
void assign() { //根据assign规则生成的方法一match(ID); //将当前的输入符号和ID相比较,然后将具消费掉match('='); expr(); //通过调用方法expr()来匹配一个表达式match(';');
对一个语句的匹配可能不止有一种情况,所以其实现类似于分支语句的试探匹配,语法分析器通过前瞻词法符号,将输入字符和每个备选分支的起始符号进行比较,从而判断哪个语义规则是正确的。按照语法规则在分支进行判断并一路走下去,直到最后一个字符,那么这个语法匹配就是正确的。
/**从当前愉入位置开始,匹配多种语句*/
stat: assign //第一个备选分支| ifstat //第二个备选分支| whilestat ...
2.2 歧义
如果最后有多个正确匹配的结果,那么就需要处理歧义。我们必须提供没有歧义的语法,使antlr生成的语法分析器能够以唯一方式匹配输入词组。在语法分析器和词法分析器中都会出现歧义,它将选择第一个备选分支。常见的歧义例如
- 对运算符的解释,例如C语言中i*j,可以解释为乘法或者指针
- 运算顺序的不同,例如1+2*3是从左到右还是按优先级
2.3 语法分析树
通过操纵语法分析器自动生成的语法分析树,我们可以很便捷地构建语言类应用程序,如下所示为antlr构建语法分析树中使用的数据结构,对应常用的类有CharStream、Lexer、Token、Parser、ParserTree,通过TokenStream连接词法分析器和语法分析器

为了节约内存,可以看到语法树的叶子节点TerminalNode词法符号仅记录了自己在字符序列中的开始和结束位置,而非保存字符串的拷贝
语法树的非叶节点RuleNode代表不同的语法规则,ANTLR为每个规则都生成一个子类,如下所示有StatContext、AssignContext和ExprContext等节点,它们被称为上下文对象,它们具有识别访问词组的全部信息

2.4 监听器
ANTLR还提供了对语法树进行遍历的机制,方便我们对树进行遍历计算和更新数据等操作
第一种遍历方式为监听器,antlr通过ParseTreeWalker类来对语法分析树进行遍历,然后为每个可能触发的事件分配语法分析树监听器接口(ParseTreeListener Interface),我们可以在接口中定义所需要执行的逻辑代码,当事件到达时触发监听器并执行回调函数。这一切都是自动进行的,不需要我们手动编写遍历和访问子节点的代码。
ANTLR为每个语法文件生成ParseTreeListener子类,每条语法规则都对应有enter和exit方法。如下所示,遍历器对语法树进行深度优先遍历,当遍历到Assign规则对应的节点时就会触发enterAssign()方法,并将上下文对象AssignContext作为参数传递给它。当遍历完所有子节点并返回时,就会调用exitAssign()方法

2.5 访问器
如果希望手动控制遍历语法树的过程,可以在命令行增加-visitor选项让ANTLR为语法生成访问器接口(visitor interface),为每条规则都创建一个visit方法
如下所示为对语法树进行深度优先遍历的过程,右边为visit()方法的调用顺序。ANTLR会在根节点调用visitStat()方法并在其中调用visit()方法,并将所有子节点作为参数传递进去
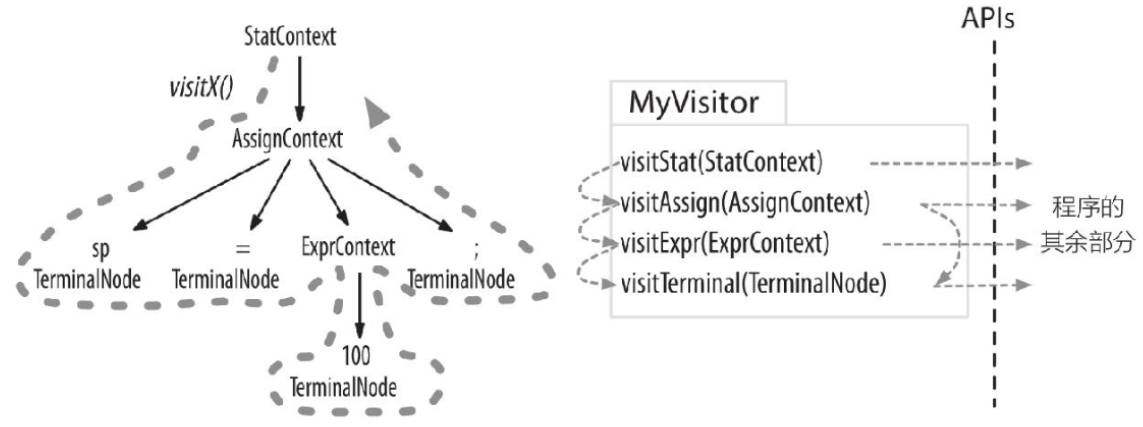
这篇关于使用ANTLR进行语法分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





