训练样本专题

字符是识别---13-源数据20*20--训练样本0~Z----二值化参数影响训练结果
正确率:37 / 39 = 94.8 % 经过虎哥指导,把 二值化过程中把 255 变成 1,训练了接近3小时,结果挺好。

字符是识别---11--源数据20*20--训练样本0~Z----基于TensorFlow+CNN实现
#coding=utf-8import os#图像读取库from PIL import Image#矩阵运算库import numpy as npimport tensorflow as tf# 训练还是测试train = True #True False# 数据文件夹if train:data_dir = "data"else:data_dir = "test"# 模型

字符是识别---10--源数据20*20--训练样本0~A----基于TensorFlow+CNN实现
#coding=utf-8import os#图像读取库from PIL import Image#矩阵运算库import numpy as npimport tensorflow as tf# 训练还是测试train = False #True False# 数据文件夹if train:data_dir = "data"else:data_dir = "test"# 模型文件



字符是识别---7---直方图信息+源数据20*20--训练样本+二值化
结果:识别正确率 91.66% 去了字符9,一共有72个字符,识别错误字符6个如下: 0 ------> 54 ------->64 -------> 64 -------> 63 -------> 8B -------> 5

字符是识别---6---只利用直方图信息--训练样本+二值化
结果:识别正确率 86.11% 去了字符9,一共有72个字符,识别错误字符10个如下: 0 ------> 3B ------->3A -------> KK -------> UA -----> XA -----> LB -----> E1 -----> YW -----> QK -----> V

数字图像处理成长之路17:linux下训练样本并识别车牌实验
在网上找到了一个小样本 首先列显示这些样本文件并重定向道data1.txt: ls -1 >> data1.txt 然后修改后缀名: cat data1.txt | sed 's/\.bmp/\.bmp 1 0 0 60 17/' 在文件前面加上路径前缀: cat data2.txt | sed 's/^/\/home\/test\/桌面\/car_t

huggingface pipeline零训练样本分类Zero-Shot Classification的实现
1 : 默认的model 。 from huggingface_hub.hf_api import HfFolderHfFolder.save_token('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')from transformers import MBartForConditionalGeneration, MBart50TokenizerFastfro

遥感影像-语义分割数据集:高分卫星-云数据集详细介绍及训练样本处理流程
原始数据集详情 简介:该云数据集包括RGB三通道的高分辨率图像,包含高分一、高分二及宽幅数据集。 KeyValue卫星类型高分系列覆盖区域未知场景未知分辨率1m、2m、8m数量12000单张尺寸1024*1024原始影像位深8位标签图片位深8位原始影像通道数三通道标签图片通道数单通道 标签类别对照表 像素值类别名(英文)类别名(中文)RGB0Clear无云区域1Cloud有云区域 数据处

遥感影像-语义分割数据集:Landsat8云数据集详细介绍及训练样本处理流程
原始数据集详情 简介:该云数据集包括RGB三通道的高分辨率图像,在全球不同区域的分辨率15米。这些图像采集自Lansat8的五种主要土地覆盖类型,即水、植被、湿地、城市、冰雪和贫瘠土地。 KeyValue卫星类型landsat8覆盖区域未知场景水、植被、湿地、城市、冰雪和贫瘠土地分辨率15m数量训练集17张+测试集20张单张尺寸7600*7600原始影像位深8位标签图片位深8位原始影像通道数三

遥感影像-语义分割数据集:山体滑坡数据集详细介绍及训练样本处理流程
原始数据集详情 简介:该遥感滑坡数据集由卫星光学图像、滑坡边界的形状文件和数字高程模型组成。该数据集中的所有图像,即770张滑坡图像(红点)和2003张非滑坡图像,都是从2018年5月至8月拍摄的TripleSat卫星图像中截取的,影像分辨率0.8米。对于滑坡实例,我们提供了滑坡图像、滑坡掩码文件和相应的DEM数据。所有数据都经过了仔细的三次检查,以确保其可靠性。 KeyValue卫星类型Tr

遥感影像-语义分割数据集:2021年昇腾杯复赛数据集详细介绍及训练样本处理流程
原始数据集详情 简介:细粒度语义分割赛道依据现有的遥感地物分类要求, 结合现有的地物分类实际需求,参照地理国情监测、 “三调”等既有地物分类标准,依据遥感地物“所见即所得”原则, 设计地物要素分类体系,共涉及二级子类(47类),数据为0.8米-2米分辨率的遥感图像。 KeyValue卫星类型GaoFen-1、ZiYuan-3覆盖区域未知场景未知分辨率0.8m-2m数量35000张单张尺寸512
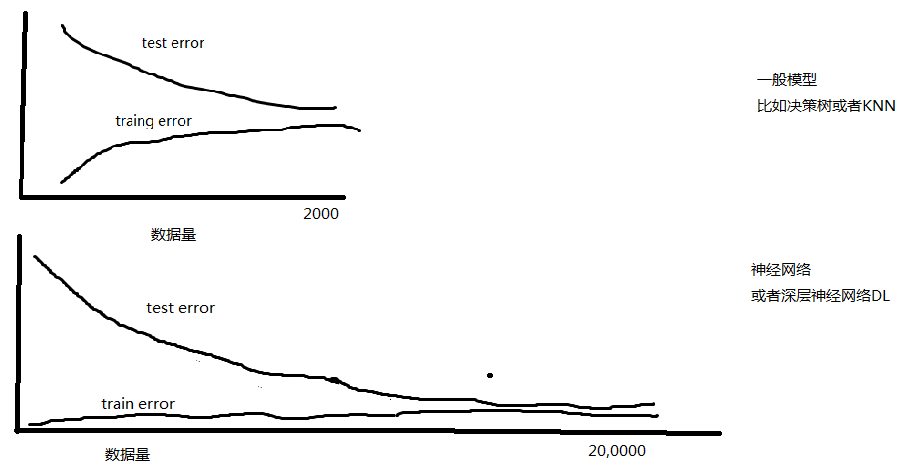
为什么深度学习对训练样本的数量要求较高?
提问:最近在研究深度卷积神经网络,看到很多的深度学习训练都需要几百万的训练样本,我想请教各位为什么深度学习一定要这么多训练样本呢,假如样本只有几万或者几千,对性能会有影响吗? 回答: 作者:Sisyphus 链接:https://www.zhihu.com/question/29633459/answer/45138977 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请

神经网络训练样本 加权,神经网络训练模型描述
神经网络测试样本集,训练样本集怎么理解,编程目的是让 测试样本输出跟踪目标输出么?谢谢指导~~~不懂~ 训练样本是用来训练学习机的,测试样本是学习机要识别的对象。 比如你想让一台电脑能识别茶杯,首先你要准备一个茶杯(训练样本),然后把茶杯给计算机看(数据输入),并告诉电脑说这样的东东是茶杯(期望输出),电脑看到茶杯后它认为是花盆,但看到你的期望是茶杯,他就不停训练自己这个是茶杯不是花盆,直到电
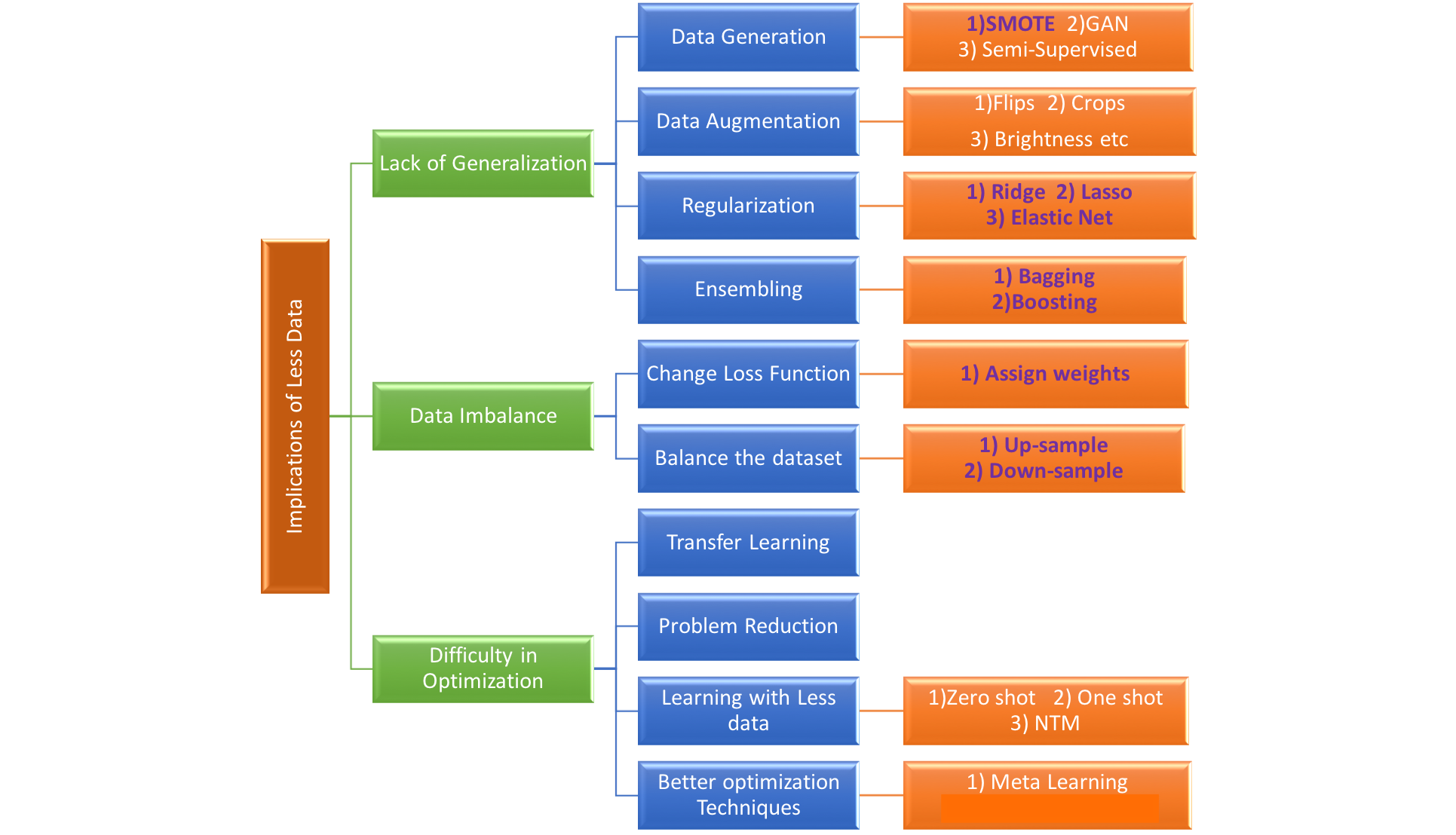
缺陷或负样本难以收集怎么办?使用生成式模型自动生成训练样本,image-to-image Stable diffusion
文章大纲 样本稀疏与对应的解决方案1.数据层面2.模型层面3.方法层面 如何解决工业缺陷检测小样本问题参考1:AIDG(Artificial Intelligent Defect Generator)参考2:灵感来源 : Image-to-Image Diffusion Models 参考文献与学习路径参考博文数据集算法缺陷检测库hugging face 样本稀疏与对应的解决

python深度学习训练样本图像增强
深度学习样本标完后图片增强标签内容不变02_train图片增强后-CSDN博客 begin部分两部分都打开则可以实现随机从A图取一部分放至B图中增强图像 功能的优化 import numpy as npimport cv2import copyimport randomimport argparseimport globdef random_gray(em):if em >=