本文主要是介绍为什么深度学习对训练样本的数量要求较高?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
提问:最近在研究深度卷积神经网络,看到很多的深度学习训练都需要几百万的训练样本,我想请教各位为什么深度学习一定要这么多训练样本呢,假如样本只有几万或者几千,对性能会有影响吗?
回答:
作者:Sisyphus
链接:https://www.zhihu.com/question/29633459/answer/45138977
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
对于classification model,有这样一个结论:

上式中N是训练样本数量,η大于等于0小于等于1,h是classification model的VC dimension。具体见wiki:VC dimension。
其中的这项:
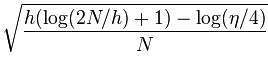
也叫model complexity penalty。
可以看到,test error小于training error加上model complexity penalty的概率是1-η。如果现在训练模型的算法能使得training error很小,而model complexity penalty又很小,就能保证test error也很小的概率是 1-η。所以要使得模型的generalization比较好,要保证training error和model complexity penalty都能比较小。
观察model complexity penalty项,可以看到,h越大,model complexity penalty就会越大。N越大,model complexity penalty则会越小。大致上讲,越复杂的模型有着越大的h(VC dimension),所以为了使得模型有着好的generalization,需要有较大的N来压低model complexity penalty。 这就是为什么深度学习的模型需要大量的数据来训练,否则模型的generalization会比较差,也就是过拟合。

左:欠拟合
中:过拟合
右:深度学习
作者:Penguin Whisper
链接:https://www.zhihu.com/question/29633459/answer/150303826
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
画个train and test error VS 训练数据量(training set size) 的learningcurve应该会更加直观了。
可以找个简单的数据集,比如说handwritten digits或者什么的,分别用神经网络和决策树或者knn做出这个learningcurve。
你会看到如果用一个决策树去解决这个问题,随着数据量增加,比如加到500,1000的样本,test error会不断降低,train error会不断增加。最后比如在数据量为2000的地方两个error就收敛了,在0.20的附近比如说。
但是如果你用神经网络去解决这个问题,你会看到当数据量很小的时候train error就是0.01了,然后数据量从0增到500或者1000,train error还是0.01,就像是一条直线一样。直到数据量增加到几万的时候,才看到train error有略微明显的增加(比如到了0.02)。 所以数据量从0到5w,train error只从0.01增加到0.02。而test error虽然在降低,但是一直都比较大,所以overfitting一直存在。
但是我们有个信念是,如同楼上其他人说的,只要数据量足够大,那么test和train会沿着收敛的方向不断前进,而当数据量足够大,两个曲线收敛的那一刻达到的时候,不仅两个曲线收敛了,同时我们的train和test error都是比较低的,远低于上面的knn或者其他简单点的模型。 如果是DL深层的神经网络,可能要几百万才能够达到收敛,那么这个时候的test error肯定也是非常低的
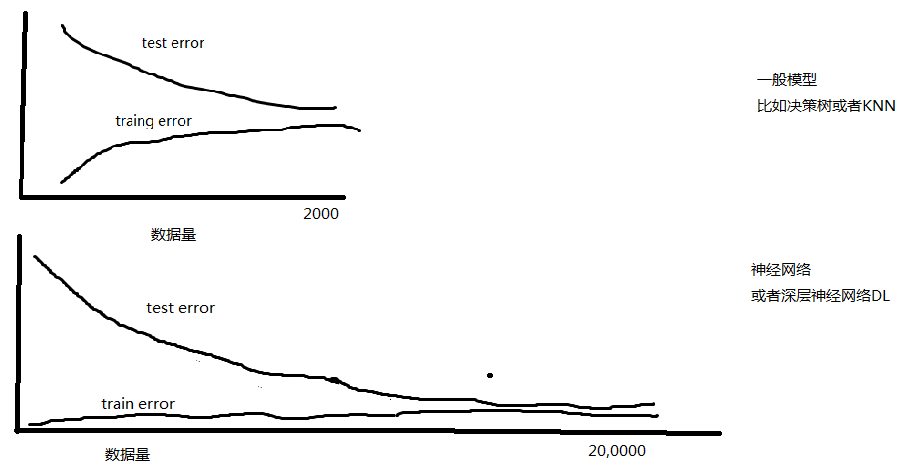
所以过拟合,欠拟合,是衡量模型拟合能力与数据量之间相对关系的东西。
如果拟合能力很强,数据量相比拟合能力太少了,就是过拟合。 (在图线上,过拟合就是两个曲线之间有gap,两个曲线没有达到收敛状态,还在向收敛的方向趋近)
如果拟合能力很弱,数据量大大超过拟合能力大大足够了,就是欠拟合。(在图线上,欠拟合就是两个曲线收敛了,但是这个收敛对应的error值太高了。 那么怎么判断这个值太高了呢?这个是人视情况来决定的。)
所以从图线的角度来说,对等划分应该有三种状态:
1) 如果两个图线未收敛状态:这就叫过拟合。。
2) 如果两图线收敛了,但是收敛处的error值过高,不符合预期,就叫欠拟合。
3) 如果两图线收敛了,而且收敛处的error值比较低,符合预期,那么就叫成功了。这正是我们想要的。
另外,其实具体情况,还是要根据问题本身的复杂程度,模型的复杂程度,数据量,这三者一起来看的。
机器学习里,模型越复杂、越具有强表达能力越容易牺牲对未来数据的解释能力,而专注于解释训练数据。这种现象会导致训练数据效果非常好,但遇到测试数据效果会大打折扣。这一现象叫过拟合(overfitting)。
深层神经网络因为其结构,所以具有相较传统模型有很强的表达能力,从而也就需要更多的数据来避免过拟合的发生,以保证训练的模型在新的数据上也能有可以接受的表现。
作者:某翔
链接:https://www.zhihu.com/question/29633459/answer/150421577
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
首先是因为curse of dimensionality。深度学习往往用于高维空间的学习,但是随着维度的增高所需要的样本数呈指数性增长。比如说对于Lipschitz连续的函数,minimax error rate是O(n^(-2/2+d)),其中d代表数据的维度。由此可见,为了达到同样的error rate,高维度比低维度函数所需要的样本数多了太多。
其次在于深度学习并没有足够的利用好函数本身的信息。之所以深度学习这么流行,是因为他对于所学习的函数的限制非常少,几乎毫无任何假设(一个hidden layer的神经网络就可以估计所有的连续函数,而两个hidden layer则可以估计所有函数)。但是这也带来了一个缺憾,当函数足够smooth足够光滑的时候深度学习可能难以利用好这个信息。相反,local polynomial之类方法可以用更高次数的多项式来估计这个函数,利用好这个条件,达到相对较低的错误率。
最后一点就在于深度学习常采用的是梯度下降。梯度下降,加上并不那么高的learning rate,导致了在样本量有限的时候各个节点的参数变化有限。何况各个节点的参数已开始往往是随机的,如果运气不好+样本量有限,那么最后有不那么理想的错误率也是可想而知的。
目前本人在做的工作是降低深度学习的样本使用数量,即主动学习(Active Learning)。
从实验效果来看,(1)并不是说样本量越多越好,主动学习方法可以大大降低样本使用数量并且达到很好的实验效果,没有overfitting;(2)主动学习结合深度学习可以衍生出深度学习在少量样本数据上的应用,如遥感图像分类(样本比普通图像要少很多);(3)样本本身是有噪声的,每个样本的价值是不同的。举个例子来说,直接用支持向量来训练一个支持向量机跟用全部数据训练一个支持向量机是差不多的。同样,深度学习的样本中也存在这样的重要的样本和不重要的样本。关键是质量。
深度学习都是几w的特征 ,用vc维来看,特征越多模型越复杂,如果ein要跟eout差不多,那么样本量是需要很巨大的,也就是我们说的overfit的问题。一般来说数据量是要十倍的vc维
这篇关于为什么深度学习对训练样本的数量要求较高?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



