统计分析专题

R语言统计分析——重复测量方差分析
参考资料:R语言实战【第2版】 所谓重复测量方差分析,即受试者被测量不止一次。本例使用数据集市co2数据集:因变量是二氧化碳吸收量(uptake),自变量是植物类型(Type)和七种水平的二氧化碳浓度(conc)。Type是组间因子,conc是组内因子。Type已经被存储为一个因子变量,还需要将conc转换为因子变量。分析过程如下: # 将conc变量转化为因子变量CO2$c

GraphPad Prism 10 for Mac/Win:高效统计分析与精美绘图的科学利器
GraphPad Prism 10 是一款专为科研工作者设计的强大统计分析与绘图软件,无论是Mac还是Windows用户,都能享受到其带来的便捷与高效。该软件广泛应用于生物医学研究、实验设计和数据分析领域,以其直观的操作界面、丰富的统计方法和多样化的图表样式,成为科学研究的得力助手。 数据处理与整理 GraphPad Prism 10 支持从多种数据源导入数据,如Excel、CSV文件及数据库

python scrapy爬虫框架 抓取BOSS直聘平台 数据可视化统计分析
使用python scrapy实现BOSS直聘数据抓取分析 前言 随着金秋九月的悄然而至,我们迎来了业界俗称的“金九银十”跳槽黄金季,周围的朋友圈中弥漫着探索新机遇的热烈氛围。然而,作为深耕技术领域的程序员群体,我们往往沉浸在代码的浩瀚宇宙中,享受着解决技术难题的乐趣,却也不经意间与职场外部的风云变幻保持了一定的距离,对行业动态或许仅有一鳞半爪的了解,甚至偶有盲区。 但正是这份对技术

大数据-案例-离线数仓-在线教育:MySQL(业务数据)-ETL(Sqoop)->Hive数仓【ODS层-数据清洗->DW层(DWD-统计分析->DWS)】-导出(Sqoop)->MySQL->可视化
一、商业BI系统概述 商业智能系统,通常简称为商业智能系统,是商业智能软件的简称,是为提高企业经营绩效而采用的一系列方法、技术和软件的总和。通常被理解为将企业中的现有数据转换为知识并帮助企业做出明智的业务决策的工具。 BI系统中的数据来自企业的其他业务系统。例如,一个面向业务的企业,其业务智能系统数据包括业务系统订单、库存、交易账户、客户和供应商信息,以及企业所属行业和竞争对手的数据,以及其他

跨模态检索研究进展综述【跨模态检索的核心工作在于:①不同模态数据的特征提取、②不同模态数据之间内容的相关性度量】【主流研究方法:基于传统统计分析的技术、基于深度学习的技术】【哈希编码提高检索速度】
随着互联网上多媒体数据的爆炸式增长,单一模态的检索已经无法满足用户需求,跨模态检索应运而生. 跨模态检索旨在以一种模态的数据去检索另一种模态的相关数据。 跨模态检索的核心任务是:数据特征提取 和 不同模态数据之间内容的相关性度量。 文中梳理了跨模态检索领域近期的研究进展,从以下角度归纳论述了跨模态检索领域的研究成果.: 传统方法;深度学习方法;手工特征的哈希编码方法;深度学习的哈希编码方法

TLS握手性能测试工具:快速重置、多线程与高级统计分析(C/C++代码实现)
随着网络安全的日益重要,传输层安全性(TLS)协议在保护数据传输中扮演着关键角色。TLS握手作为该协议的核心部分,确保了客户端和服务器之间的安全通信。鉴于其重要性,对TLS握手的性能进行精确评估变得至关重要。该工具专注于TLS握手的性能测试,而不涉及数据传输或重协商。 快速重置TCP连接 理解快速重置TCP连接对于优化TLS握手性能具有重要意义。 在数据传输过程中,TCP连接的建立和关闭是必

如何打造卷烟营销统计分析系统?Java SpringBoot+Vue助力,2025届必看新文出炉!
✍✍计算机编程指导师 ⭐⭐个人介绍:自己非常喜欢研究技术问题!专业做Java、Python、微信小程序、安卓、大数据、爬虫、Golang、大屏等实战项目。 ⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流! ⚡⚡ Java实战 | SpringBoot/SSM Python实战项目 | Django 微信小程序/安卓实战项目 大数据实战项目 ⚡⚡文末获取源码 文章目录

数据分类(数据视角)——主数据、交易数据、参考数据、统计分析数据、元数据...
数据分类(数据视角)——主数据、交易数据、参考数据、统计分析数据、元数据 1.主数据(Master Data): 主数据是关于业务实体的数据,描述组织内的“物”,如:人,地点,客户,产品等。 2.交易数据(事务数据,Transactional Data):交易数据(事务数据、业务数据)描述组织业务运营过程中的内部或外部事件或交易记录。如:销售订单,通话记录等。 3.参考数据(Refer

R语言统计分析——回归模型深层次分析
参考资料:R语言实战【第2版】 本文主要讨论回归模型的泛化能力和变量相对重要性的方法。 1、交叉验证 从定义上看,回归方法就是从一堆数据中获取最优模型参数。对于OLS(普通最小二乘)回归,通过使得预测误差(残差)平方和最小和对响应变量的解释度(R平方)最大,可获得模型参数。由于等式只是最优化已给出的数据,所以在新数据集上表现并不一定好。 通过

基于R语言的统计分析基础:数据结构
R语言是一种用于统计分析和图形表示的编程语言和软件环境,它提供了多种数据结构以存储和操作数据。这些数据结构包括向量、矩阵、数组、数据框、列表、因子、Tibble、环境、公式、调用以及表达式。 向量(Vector) 向量是R中最基本的数据结构,是用于存储相同类型数据元素的一维数组。向量可以使可以是数值型、字符型或逻辑型等,但是同一向量无法混杂不同类型或模式的数据 # 数值型向量a <- c(

新加坡门店客流计数器,AI智能识别算法加持,精准完成统计分析
在数字化转型的大潮下,零售业正经历着前所未有的变革。为了更好地理解顾客行为并优化店铺运营,新加坡的零售门店开始采用搭载AI智能识别算法的客流计数器系统。这套系统不仅能够精准统计顾客流量,还能提供深入的分析报告,帮助商家做出更加明智的决策。 一、客流计数器功能 1.高精度统计:通过AI智能识别算法,客流计数器能够准确地统计进出零售门店的顾客数量,误差率极低。

R语言统计分析——回归分析的改进措施
参考资料:R语言实战【第2版】 如果在回归诊断中发现了问题,我们该如何做?有四种方法可以处理违背回归假设的问题: ①删除观测点; ②变量变换; ③添加或删除变量; ④使用其他回归方法。 1、删除观测点 删除离群点通常可以提高数据集对正态假设的拟合度,而强影响点会干扰结果,通常也会被删除。删除最大的离群点或强影响点后,模型需要重新你和。若离群点或强影响点

R语言统计分析——回归中的异常观测值
参考资料:R语言实战【第2版】 一个全面的回归分析要覆盖对异常值的分析,包括离群点、高杠杆点和强影响点。这些数据点需要更深入的研究,因为它们在一定程度上与其他观点不同,可能对结果产生较大的负面影响。 1、离群点 离群点是指那些模型预测效果不佳的观测点。它们通常有很大的、或正或负的残差(残差:实际值-预测值)。正的残差说明低估了响应值,负的残差则说明高估了响应值

多元统计分析——基于R的笔记本电脑价格与参数可视化
注:能力有限,存在不足之处。 现如今,笔记本电脑现在已经成为了我们日常生活中所必备的一种工具,使用笔记本既可以为我们在学习上带来便利也可以在为我们在工作上带来便利,但是笔记本的价格与许多参数有关,因此,关于笔记本的价格与参数,展开研究。 一、提出问题(要解决或分析的问题) 1、根据笔记本电脑参数预测价格 2、笔记本电脑的参数为什么区别大

R语言统计分析——线性模型假设的综合验证与多重共线性
参考资料:R语言实战【第2版】 1、线性模型假设的综合验证 gvlma包中的gvlma()函数,能对线性模型进行综合验真,同时还能做偏斜度、峰度和异方差性的评价。也就是说,它给模型提供了一个单独的综合验证(通过/不通过)。 # 加载gvlma包library(gvlma)# 获取数据states<-as.data.frame(state.x77[,c("Murder",

【python数据分析11】——Pandas统计分析(分组聚合进行组内计算)
分组聚合进行组内计算 前言1、groupby方法拆分数据2、agg方法聚合数据3、apply方法聚合数据4、transform方法聚合数据5 小案例5.1 按照时间对菜品订单详情表进行拆分5.2 使用agg方法计算5.3 使用apply方法统计单日菜品销售数目 前言 依据某个或者几个字段对数据集进行分组,并对各组应用一个函数,无论是聚合还是转换,都是数据分析的常用操作。pand
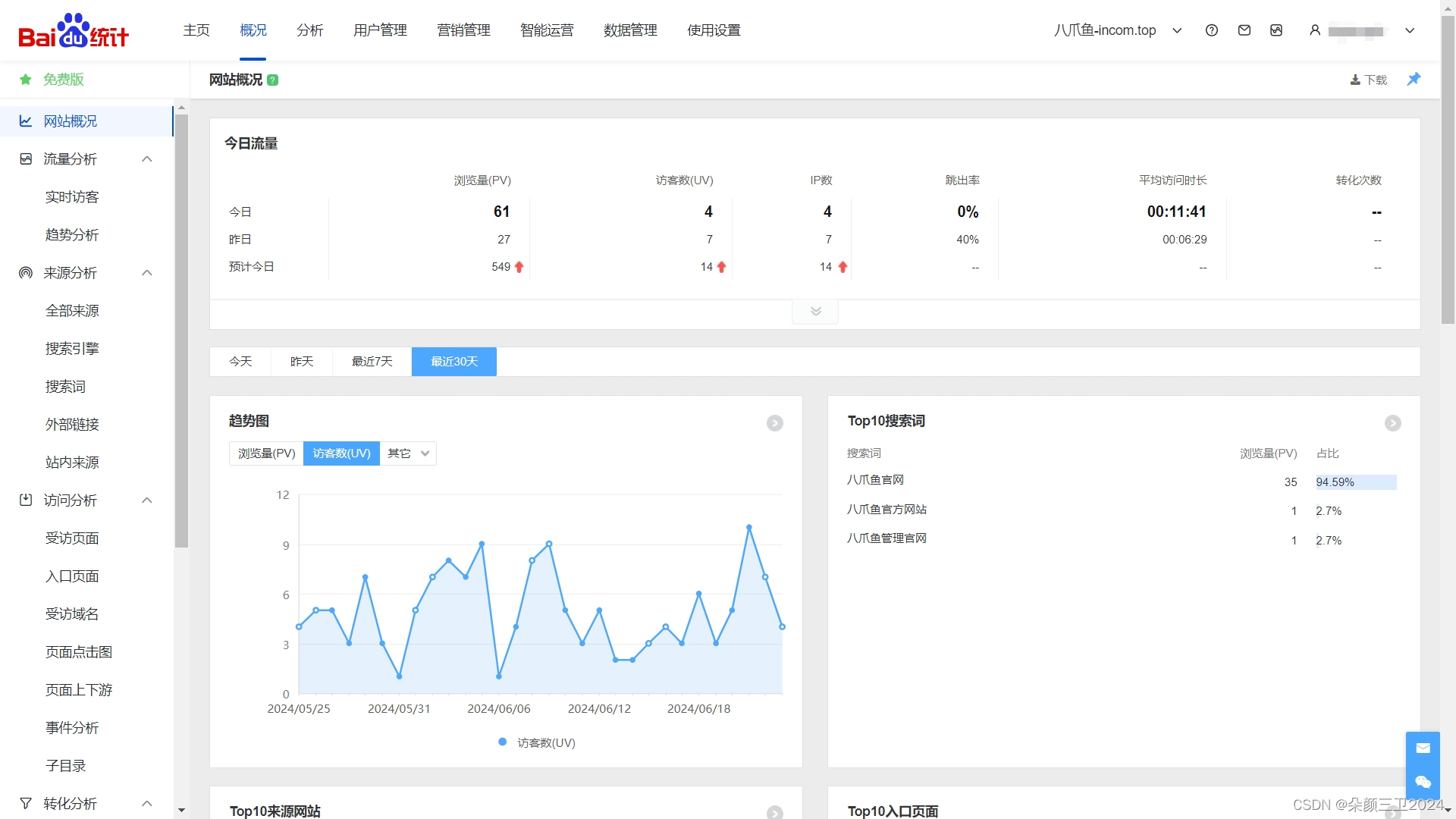
八爪鱼现金流-028,个人网站访问数据统计分析,解决方案
个人网站访问数据统计分析,解决方案 调研 结论:使用百度统计 步骤 1.注册百度统计 2.获取安装代码 3.在项目中,页面代码添加如下片段 <script>var _hmt = _hmt || [];(function() {var hm = document.createElement("script");hm.src = "https://hm.baidu.com/hm.js?x
【Rust日报】2020-06-28 - 动态链接库统计分析
压缩工具compress-tools 0.6.0发布 compress-tools 0.6.0 released https://crates.io/crates/compress-tools 压缩工具compress-tools 0.6.0发布。compress-tools是基于libarchive的开发的,并提供部分原库的压缩功能。这个工具现在可以解压: compressed files
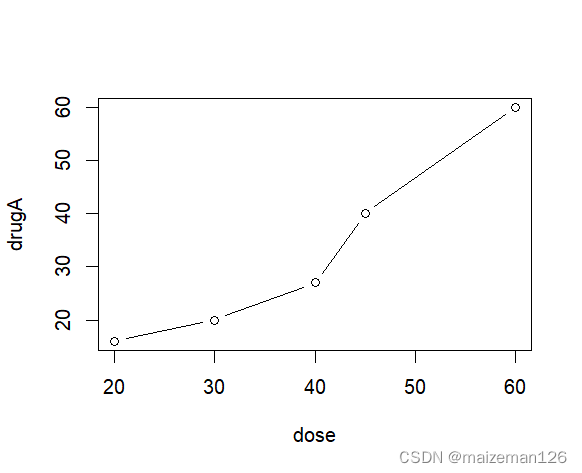
R语言统计分析——图形的简单示例
参考资料:R语言实战【第2版】 1、示例一 # 绑定数据框mtcarsattach(mtcars)# 打开一个图形窗口并生成一个散点图plot(wt,mpg)# 添加一条最优拟合曲线abline(lm(mpg~wt))# 添加标题title("Regression of MPG on weight")# 解除数据框绑定detach(mtcars) 要通过代码保存图形
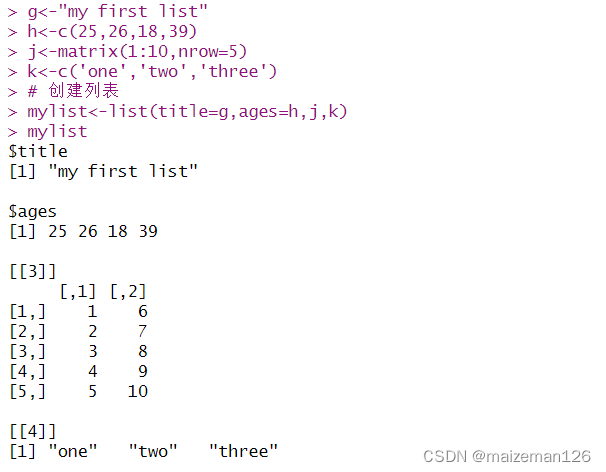
R语言统计分析——数据集概念和数据结构
参考资料:R语言实战.第2版 1、数据集的概念 数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量。 不同行业对于数据集的行和列叫法不同。统计学称为观测(observation)和变量(variable),数据库中称为记录(record)和字段(field),数据挖掘和机器学习成为示例(example)和属性(attribute)。

学生成绩统计分析系统介绍
学生成绩统计分析系统是一种用于收集、管理和分析学生学业成绩的软件系统。该系统旨在帮助学校和教育机构更好地了解学生的学习情况,进行成绩评估和分析,以支持教学决策和学生发展。学生成绩分析系统 系统专门针对学校/班级成绩管理使用,支持多维度、多角度的成绩分析和查询 还支持多种视图呈现分析成绩数据。 常见的有薪火数据、智慧校园、七彩云教育、学而思等个人可以根据实际情况进行选择使用。 学生成绩统计分析系

探索Python中的随机数生成与统计分析
新书上架~👇全国包邮奥~ python实用小工具开发教程http://pythontoolsteach.com/3 欢迎关注我👆,收藏下次不迷路┗|`O′|┛ 嗷~~ 目录 一、随机数的魅力与实用性 1. 随机数生成基础 2. 批量生成随机数 二、随机数的高级应用:统计分析 1. 正态分布随机数 2. 均匀分布随机数 三、随机数在抽样分析中的应用
Python基本统计分析
常见的统计分析方法 import numpy as np import scipy.stats as spss import pandas as pd 鸢尾花数据集 https://github.com/mwaskom/seaborn-data df = pd.read_csv("iris.csv",index_col="species") v1 = df.l

【R语言与统计】SEM结构方程、生物群落、多元统计分析、回归及混合效应模型、贝叶斯、极值统计学、meta分析、copula、分位数回归、文献计量学
统计模型的七大类:一:多元回归 在研究变量之间的相互影响关系模型时候,用到这类方法,具体地说:其可以定量地描述某一现象和某些因素之间的函数关系,将各变量的已知值带入回归方程可以求出因变量的估计值,从而可以进行预测等相关研究。 二、聚类分析 聚类分析指将物理或抽象对象的集合分组为由类似的对象组成的多个类的分析过程。 三、分类 分类是一种典型的有监督的机器学习方法,其目的是从一
《R语言与农业数据统计分析及建模》学习——logistic回归和poisson回归
普通线性回归通常用来描述变量y与x之间的线性关系: 普通线性模型的假设是:响应变量y是连续型变量而且,服从正态分布分布。但在很多现实情况y并不是正态分布,如:二值问题/多分类问题,计次问题等,这些问题都是广义线性回归的范畴。广义线性回归用于解决因变量不是正态分布的问题。不同的广义线性回归类型,使用不同的连接函数,如下: 一、Logistic回归

探索数据之美:简述多元统计分析中的聚类分析
在现代科学研究和商业决策中,我们常常面对着海量的数据。如何从这些数据中提取有用的信息?这就是统计学的任务之一。而聚类分析作为多元统计分析中的一种技术,能够帮助我们在数据中发现隐藏的模式和结构。本文将带您一起探索聚类分析的奥秘,了解它是如何工作的以及在实际生活中的应用。 什么是聚类分析? 聚类分析是一种无监督学习的方法,其主要目的是将一组数据点划分为具有相似特征的若干个组(或者称为簇)。换句话说