累加器专题

spark的Accumulator累加器使用及 自定义Accumulator功能
一、spark的累加器Accumulator 使用Accumulator时,为了保证准确性,只使用一次action操作。如果多次action操作,会造成累加器值错误。 解决方案:将任务之间的血缘依赖关系切断就可以了。什么方法有这种功能呢?cache,persist,调用这个方法的时候会将之前的依赖切除,后续的累加器就不会再被之前的transfrom操作影响到了。 二、自定义Accum

详解 Spark 核心编程之累加器
累加器是分布式共享只写变量 一、累加器功能 累加器可以用来把 Executor 端的变量信息聚合到 Driver 端。在 Driver 程序中定义的变量,在 Executor 端的每个 Task 都会得到这个变量的一份新的副本,每个 task 更新这些副本的值后,传回 Driver 端进行 merge 二、累加器类型 1. 系统累加器 /**常见的系统累加器:longAc
Utreexod:支持Utreexo累加器的比特币全节点
1. 引言 前序博客: Utreexo:比特币UTXO merkle tree proof以节约节点存储空间Utreexo:优化Bitcoin UTXO集合的基于哈希的动态累加器Zerosync:构建基于STARK的Bitcoin证明系统 Utreexod为: 支持Utreexo累加器的比特币全节点 开源代码见: https://github.com/utreexo/utreexod(
Flink 累加器 实例
每个并行的任务实例下有各自的累加器,获取最终值时会把各个并行任务的累加器的值求和。(一个并行度对应一个累加器) 版本: flink1.9.2 java1.8 map并行度1: package Counter;import org.apache.flink.api.common.JobExecutionResult;import org.apache.flink.api.common.

9、Flink 用户自定义 Functions 及 累加器详解
1)用户自定义函数 1.实现接口 最基本的方法是实现提供的接口。 # 根据提供的接口创建自定义函数class MyMapFunction implements MapFunction<String, Integer> {public Integer map(String value) { return Integer.parseInt(value); }}# 调用创建的自定义函数dat
用Python编写一个简单的数字累加器 数字累加器
目录 一.总体说明 二.完整代码 三.逐行分析 一.总体说明 数字累加器是一种用于对数字进行持续累加的设备或算法。它可以在每次输入一个数字时将其与之前的累加结果相加,并更新累加结果。数字累加器通常用于计算总和、平均值或其他需要对连续数字进行累加的应用场景。 在计算机科学中,数字累加器也被称为累加寄存器。它是计算机体系结构中的一部分,在CPU或其他处理器中负责执行累加操作。累加器
JUC:原子类型的使用(原子整数、原子引用、原子数组、字段更新器、累加器)
文章目录 原子类型AtomicInteger 原子整数AtomicReferenc 原子引用AtomicStampedReference 带版本号的原子引用AtomicMarkableReference 仅记录是否修改的原子引用AtomicXXXArray 原子数组AtomicXXXFieldUpdater 字段更新器LongAdder累加器 原子类型 AtomicIntege
js reduce累加器
reduce 是es6 新增的数组操作方法 意为累加器 使用方法如下 [1,1,1,1].reduce((total,currentValue,index)=>{},initialValue) initialValue 代表的是累加器的初始值 必填 total的值在初始情况下等于initialValue 用来接收返回的结果 必填 currentValue 代表数组中的每一项 必填 inde

Spark算子:转化算子、执行算子;累加器、广播变量
目录 一、转换算子 1、map 2、fliter 3、flatMap 4、Sample 5、Group 6、ReduceBykey 7、Union 8、Join 9、mapValus 10、sortBy 11、distinct 二、操作算子 三、累加器 四、广播变量 transformations转换算子:延迟执行--针对RDD的操作 Action操作

在使用spark2自定义累加器时提示:Exception in thread main org.apache.spark.SparkException: Task not serializable
在使用spark自定义累加器时提示如下错误: Exception in thread "main" org.apache.spark.SparkException: Task not serializableat org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:298)at org.apa
累加器 - 分布式共享写变量
水善利万物而不争,处众人之所恶,故几于道💦 文章目录 概念注意:应用 概念 因为RDD是可分区的,每个分区在不同的节点上运行,如果想要对某个值进行全局累加,就需要将每个task中的值取到然后进行累加,而各个Executor之间是不能相互读取对方数据的,所以就没办法在task里面进行最终累加结果的输出,所以就需要一个全局统一的变量来处理。 用下面的代码举例:

快速入门Flink (6) —— Flink的广播变量、累加器与分布式缓存
写在前面: 博主是一名大数据的初学者,昵称来源于《爱丽丝梦游仙境》中的Alice和自己的昵称。作为一名互联网小白,写博客一方面是为了记录自己的学习历程,一方面是希望能够帮助到很多和自己一样处于起步阶段的萌新。由于水平有限,博客中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!个人小站:http://alices.ibilibili.xyz/ , 博客主页:https://alice.blog.
【并发编程】原子累加器
📝个人主页:五敷有你 🔥系列专栏:并发编程 ⛺️稳重求进,晒太阳 JDK8之后有专门做累加的类,效率比自己做快数倍以上 累加器性能比较 参数是方法 // supplier 提供者 无中生有 ()->结果// function 函数 一个参数一个结果 (参数)->结果 , BiFunction (参数1,参数2)->结果// consumer 消费者

二十五:Flink聚合函数和累加器使用
提到了 Flink 所支持的窗口和时间类型,并且在第 25 课时中详细讲解了如何设置时间戳提取器和水印发射器。 实际的业务中,我们在使用窗口的过程中一定是基于窗口进行的聚合计算。例如,计算窗口内的 UV、PV 等,那么 Flink 支持哪些基于窗口的聚合函数?累加器又该如何实现呢? Flink 支持的窗口函数 我们在定义完窗口以后,需要指定窗口上进行的计算。目前 Flink 支持的窗口函数包

Spark---累加器
1.累加器实现原理 累加器用来把 Executor 端变量信息聚合到 Driver 端。在 Driver 程序中定义的变量,在Executor 端的每个 Task 都会得到这个变量的一份新的副本,每个 task 更新这些副本的值后,传回 Driver 端进行 merge。 //建立与Spark框架的连接val wordCount = new SparkConf().setMaster(

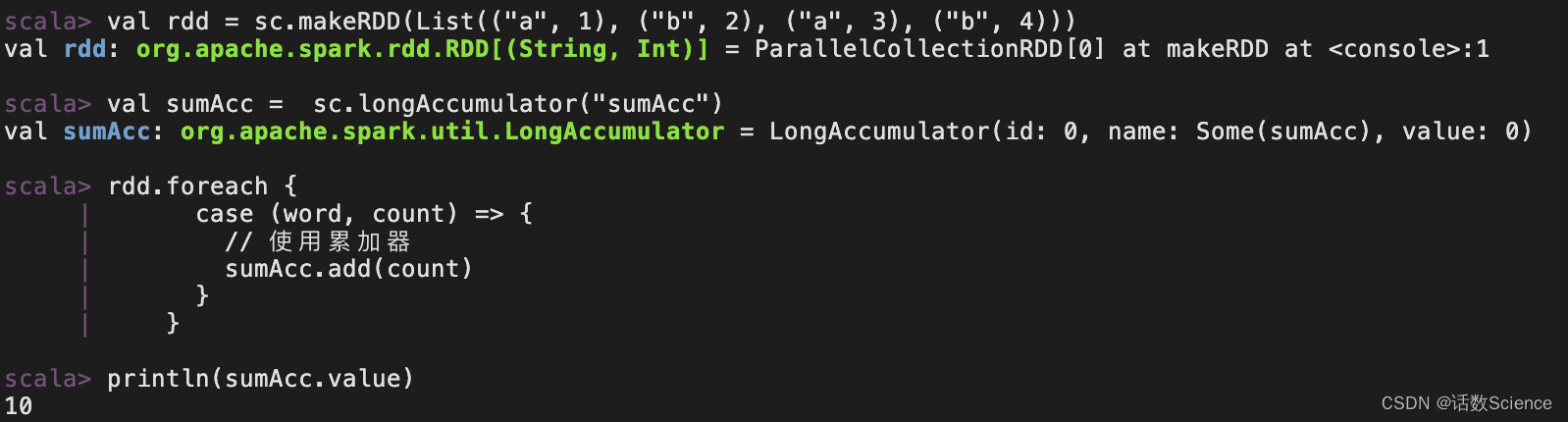
Spark学习笔记(详解,附代码实列和图解)----------累加器和广播变量
Spark三大数据结构分别是: ➢ RDD : 弹性分布式数据集 ➢ 累加器:分布式共享只写变量 ➢ 广播变量:分布式共享只读变量 一.累加器(accumulator) 问题引入: 当使用foreach来对rdd求和会发现求和数据为0 val rdd = sc.makeRDD(List(1,2,3,4))var sum = 0rdd.foreach(num => {sum += num})p
在使用foreach 与 Iterator 时不能有数据的修改以及循环内部累加器
foreach 与 Iterator java中自遍历不能有累加器 我们知道,在Java中使用foreach对集和进行遍历时,是无法对该集和进行插入、删除等操作,比如以下代码: for(Person p : personList){ if(StringUtil.isBlank(p.getName())){ personList.remove(p);
图解算法数据结构-LeetBook-回溯01_机械累加器
请设计一个机械累加器,计算从 1、2… 一直累加到目标数值 target 的总和。注意这是一个只能进行加法操作的程序,不具备乘除、if-else、switch-case、for 循环、while 循环,及条件判断语句等高级功能。 注意:不能用等差数列求和公式(用了乘法),也不能用pow()函数(用乘法实现) 公式法 class Solution {public:int mechanicalA
【大数据面试知识点】Spark中的累加器
Spark累加器 累加器用来把Executor端变量信息聚合到Driver端,在driver程序中定义的变量,在Executor端的每个task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回driver端进行merge。 累加器一般是放在行动算子中进行操作的。 Spark累加器有哪些特点? 1)累加器在全局唯一的,只增不减,记录全局集群的唯一状态 2)在Execut
reduce累加器的应用
有如下json数据,需要统计Status的值为0和1的数量 const data = {"code": "001","results": [{"Status": "0",},{"Status": "0",},{"Status": "1",}]} 方法一:用reduce方法 const countObj = data.results.reduce((acc, result) => {i
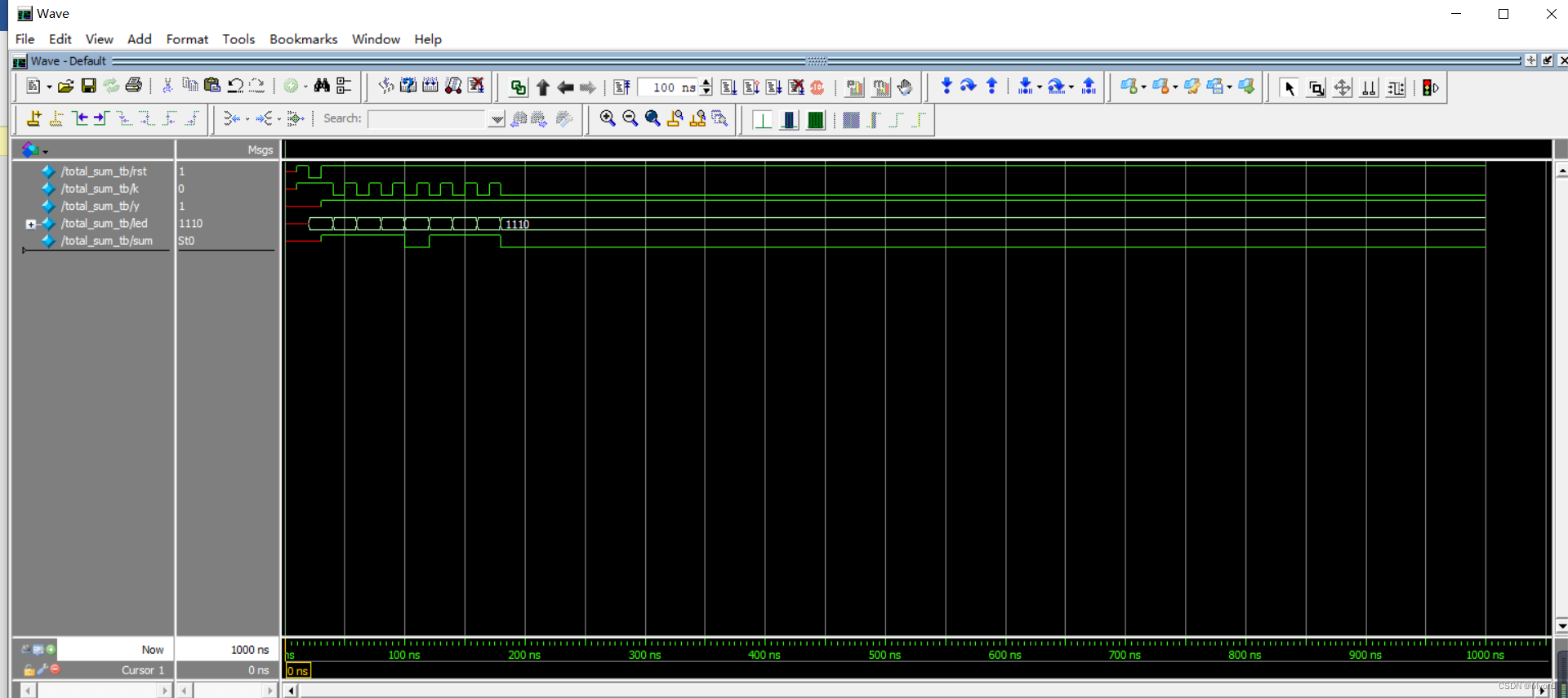
西南科技大学数字电子技术实验七(4行串行累加器设计及FPGA实现)FPGA部分
一、实验目的 1、掌握基于Verilog语言的diamond工具设计全流程。 2、熟悉、应用Verilog HDL描述数字电路。 3、掌握Verilog HDL的组合和时序逻辑电路的设计方法。 4、掌握“小脚丫”开发板的使用方法。 二、实验原理 三、程序清单(每条语句必须包括注释或在开发窗口注释后截图) 逻辑代码: module total_sum ( input wire
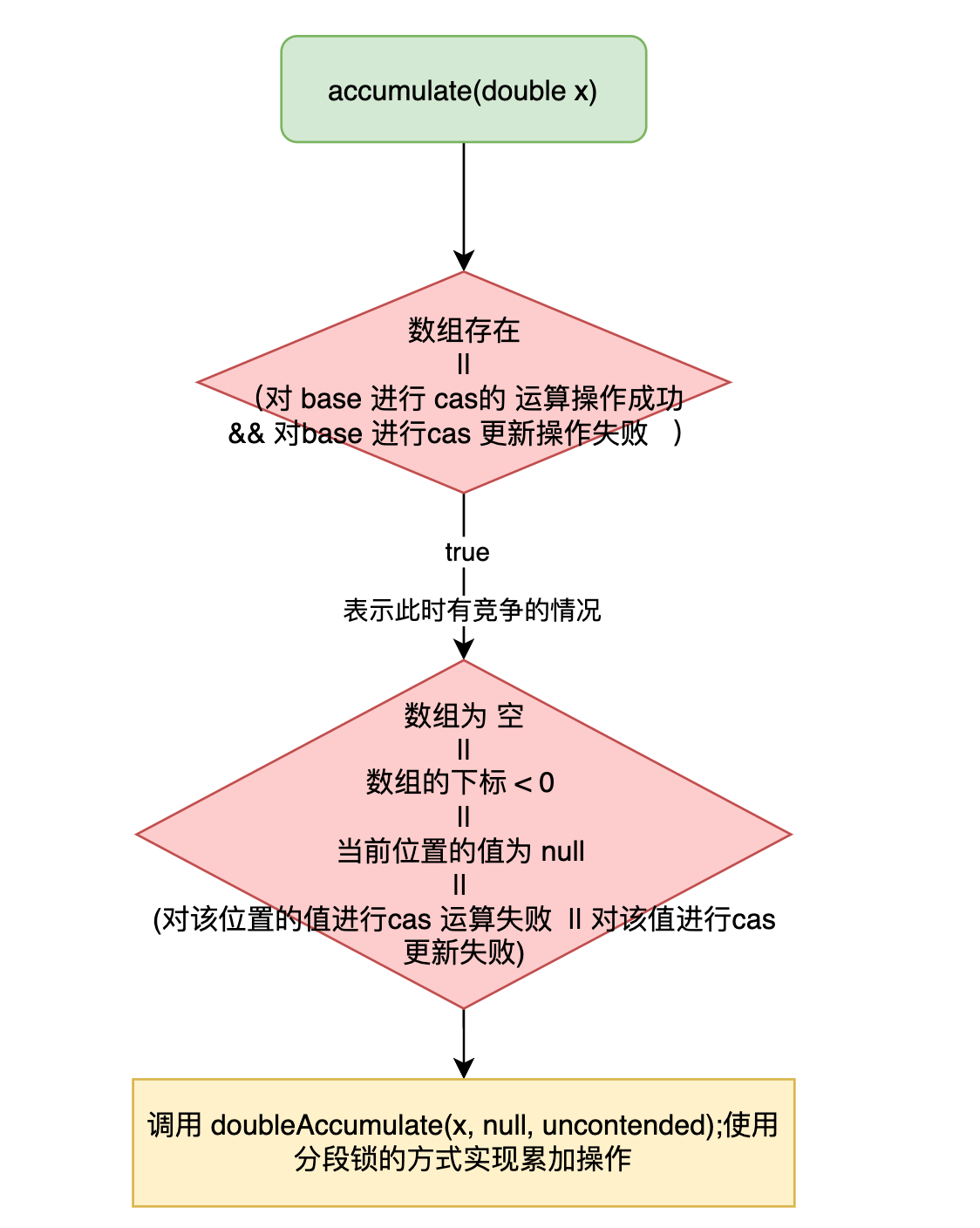
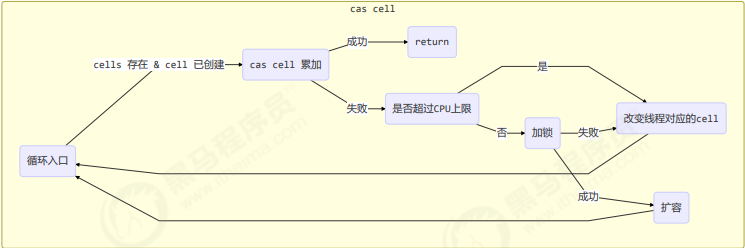
看图学源码之 Atomic 类源码浅析二(cas + 分治思想的原子累加器)
原子累加器 相较于上一节看图学源码 之 Atomic 类源码浅析一(cas + 自旋操作的 AtomicXXX原子类)说的的原子类,原子累加器的效率会更高 XXXXAdder 和 XXXAccumulator 区别就是 Adder只有add 方法,Accumulator是可以进行自定义运算方法的 始于 Striped64 abstract class Striped64 e