本文主要是介绍在使用spark2自定义累加器时提示:Exception in thread main org.apache.spark.SparkException: Task not serializable,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在使用spark自定义累加器时提示如下错误:
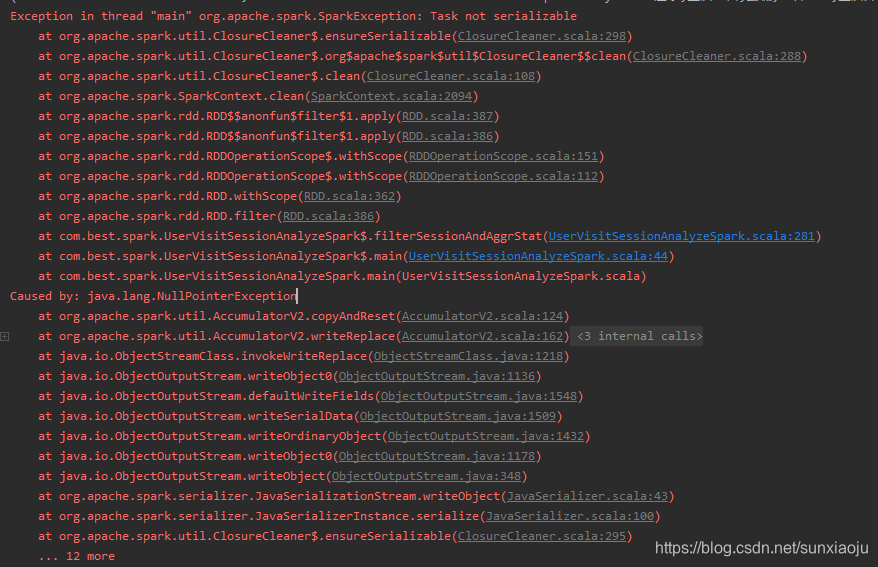
Exception in thread "main" org.apache.spark.SparkException: Task not serializableat org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:298)at org.apache.spark.util.ClosureCleaner$.org$apache$spark$util$ClosureCleaner$$clean(ClosureCleaner.scala:288)at org.apache.spark.util.ClosureCleaner$.clean(ClosureCleaner.scala:108)at org.apache.spark.SparkContext.clean(SparkContext.scala:2094)at org.apache.spark.rdd.RDD$$anonfun$filter$1.apply(RDD.scala:387)at org.apache.spark.rdd.RDD$$anonfun$filter$1.apply(RDD.scala:386)at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)at org.apache.spark.rdd.RDD.withScope(RDD.scala:362)at org.apache.spark.rdd.RDD.filter(RDD.scala:386)at com.best.spark.UserVisitSessionAnalyzeSpark$.filterSessionAndAggrStat(UserVisitSessionAnalyzeSpark.scala:281)at com.best.spark.UserVisitSessionAnalyzeSpark$.main(UserVisitSessionAnalyzeSpark.scala:44)at com.best.spark.UserVisitSessionAnalyzeSpark.main(UserVisitSessionAnalyzeSpark.scala)
Caused by: java.lang.NullPointerExceptionat org.apache.spark.util.AccumulatorV2.copyAndReset(AccumulatorV2.scala:124)at org.apache.spark.util.AccumulatorV2.writeReplace(AccumulatorV2.scala:162)at sun.reflect.GeneratedMethodAccessor4.invoke(Unknown Source)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:498)at java.io.ObjectStreamClass.invokeWriteReplace(ObjectStreamClass.java:1218)at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1136)at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1548)at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1509)at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1432)at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1178)at java.io.ObjectOutputStream.writeObject(ObjectOutputStream.java:348)at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:43)at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:100)at org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:295)... 12 more如下图所示:
自定义累加器代码如:
package com.best.spark
import com.best.constanl.Constants
import com.best.util.StringUtils
import org.apache.spark.util.AccumulatorV2
class SessionAggrStatAccumulator extends AccumulatorV2[String,String] with java.io.Serializable{private val serialVersionUID = 7292644531814797752Lvar resultInit: String = Constants.SESSION_COUNT + "=0|" + Constants.TIME_PERIOD_1s_3s + "=0|" + Constants.TIME_PERIOD_4s_6s + "=0|" + Constants.TIME_PERIOD_7s_9s + "=0|" + Constants.TIME_PERIOD_10s_30s + "=0|" + Constants.TIME_PERIOD_30s_60s + "=0|" + Constants.TIME_PERIOD_1m_3m + "=0|" + Constants.TIME_PERIOD_3m_10m + "=0|" + Constants.TIME_PERIOD_10m_30m + "=0|" + Constants.TIME_PERIOD_30m + "=0|" + Constants.STEP_PERIOD_1_3 + "=0|" + Constants.STEP_PERIOD_4_6 + "=0|" + Constants.STEP_PERIOD_7_9 + "=0|" + Constants.STEP_PERIOD_10_30 + "=0|" + Constants.STEP_PERIOD_30_60 + "=0|" + Constants.STEP_PERIOD_60 + "=0"var result: String = resultInit/*** 当AccumulatorV2中存在类似数据不存在这种问题时,是否结束程序。** @return*/override def isZero = false/*** 拷贝一个新的AccumulatorV2** @return*/override def copy: AccumulatorV2[String, String] = null/*** 重置AccumulatorV2中的数据*/override def reset(): Unit = {result = resultInit}/*** session统计计算逻辑* v就表示传过来的要累加的key** @param v*/override def add(v: String): Unit = {if (StringUtils.isNotEmpty(v) && StringUtils.isNotEmpty(result)) {val oldValue = StringUtils.getFieldFromConcatString(result, "\\|", v)if (oldValue != null) {val newValue = Integer.valueOf(oldValue) + 1result = StringUtils.setFieldInConcatString(result, "\\|", v, String.valueOf(newValue))}}}/*** 合并数据** @param other*/override def merge(other: AccumulatorV2[String, String]): Unit = {if (other.isZero) result = other.value}/*** AccumulatorV2对外访问的数据结果** @return*/override def value: String = result
}
而使用的地方在:

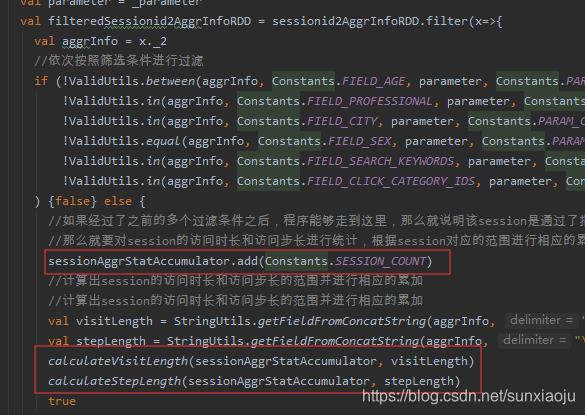
出现此问题的原因是:sessionAggrStatAccumulator它是运行在Driver端的,而filter算子是运行在Executor端的,所以报错,因此将sessionAggrStatAccumulator移除到函数外部进行new,即在类中进行new,如:

这篇关于在使用spark2自定义累加器时提示:Exception in thread main org.apache.spark.SparkException: Task not serializable的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




