spark2专题

Spark2.x 入门: KMeans 聚类算法
一 KMeans简介 KMeans 是一个迭代求解的聚类算法,其属于 划分(Partitioning) 型的聚类方法,即首先创建K个划分,然后迭代地将样本从一个划分转移到另一个划分来改善最终聚类的质量。 ML包下的KMeans方法位于org.apache.spark.ml.clustering包下,其过程大致如下: 1.根据给定的k值,选取k个样本点作为初始划分中心;2.计算所有样本点到每

Spark2.x 入门:决策树分类器
一、方法简介 决策树(decision tree)是一种基本的分类与回归方法,这里主要介绍用于分类的决策树。决策树模式呈树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。学习时利用训练数据,根据损失函数最小化的原则建立决策树模型;预测时,对新的数据,利用决策树模型进行分类。 决策树学习通常包括3个步骤:特征选择、决策树的生成和决策树的剪枝。

spark2调用TensorFlow2模型
问题一: com.google.protobuf.Parser.parseFrom方法找不到。因cdh默认的spark依赖jar中protobuf-java-[version].jar版本太低,需要手动升级替换; 问题二: 序列化org.tensorflow.SavedModelBundle后广播各种空指针,建议直接改道addFile(modelPath,true)于executor加载模型;
Spark2.x 入门:RDD队列流(DStream)
在调试Spark Streaming应用程序的时候,我们可以使用streamingContext.queueStream(queueOfRDD)创建基于RDD队列的DStream。 下面是参考Spark官网的QueueStream程序设计的程序,每隔1秒创建一个RDD,Streaming每隔2秒就对数据进行处理。 新建一个TestRDDQueueStream.scala文件,在该文件中输入以下
CDH 安装spark2
一.安装准备 csd包:http://archive.cloudera.com/spark2/csd/ parcel包:http://archive.cloudera.com/spark2/parcels/2.3.0.cloudera2/ 二.开始安装 1.安装前可以停掉集群和Cloudera Management Service 2.下面的操作,只需要在安装spark2的机器上面进行,我只选择C

在使用spark2自定义累加器时提示:Exception in thread main org.apache.spark.SparkException: Task not serializable
在使用spark自定义累加器时提示如下错误: Exception in thread "main" org.apache.spark.SparkException: Task not serializableat org.apache.spark.util.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:298)at org.apa

spark零基础学习线路指导【包括spark2】
问题导读1.你认为spark该如何入门?2.你认为spark入门编程需要哪些步骤?3.本文介绍了spark哪些编程知识? 转载注明链接: http://www.aboutyun.com/forum.php?mod=viewthread&tid=21959 spark学习一般都具有hadoop基础,所以学习起来更容易多了。如果没有基础,可以参考零基础学习hadoop到上手工作线路指导(初级篇)
Hadoop学习笔记(HDP)-Part.17 安装Spark2
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part
Hdoop学习笔记(HDP)-Part.17 安装Spark2
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part
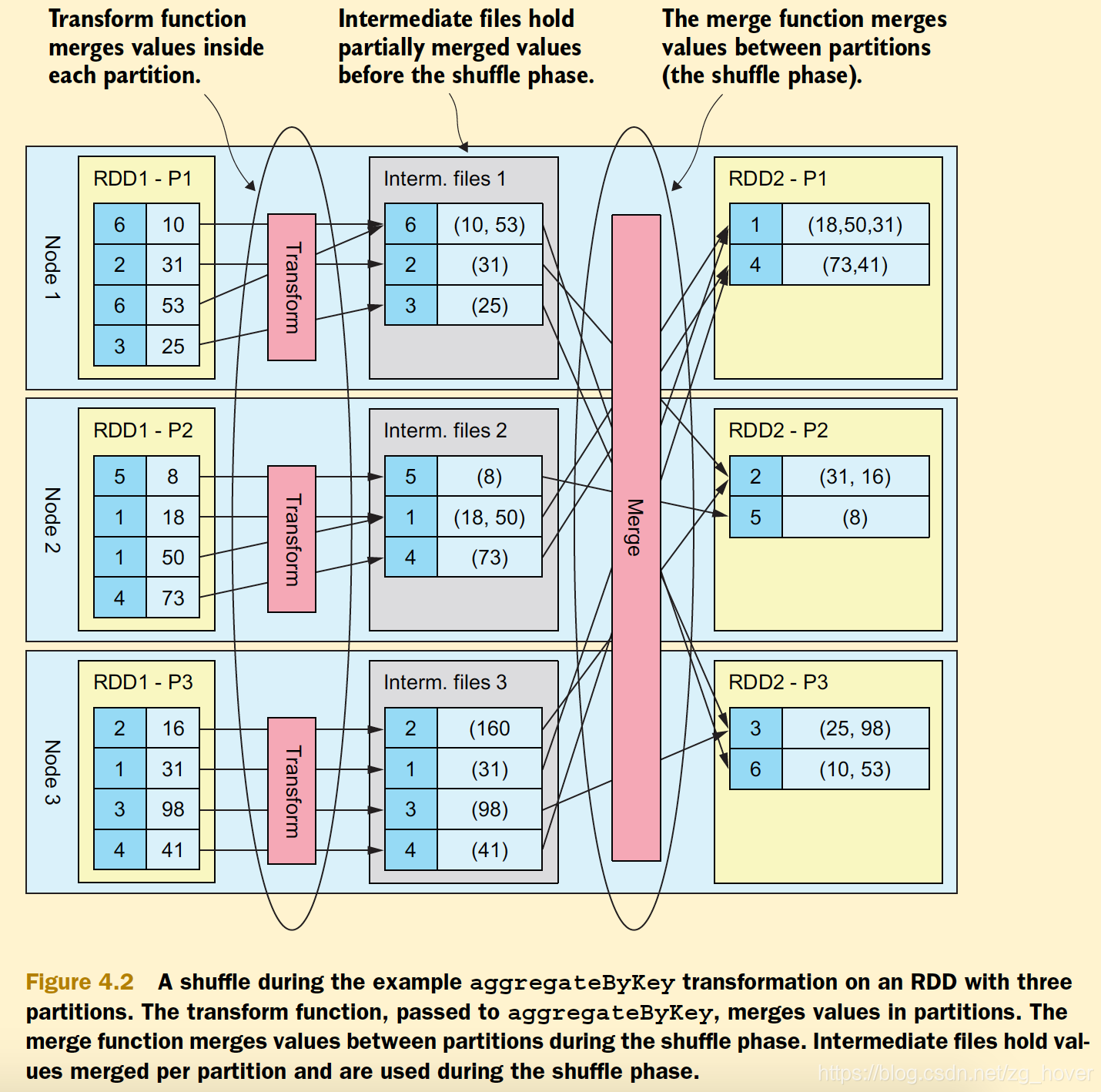
spark2原理分析-RDD的shuffle简介
概述 本文介绍RDD的Shuffle原理,并分析shuffle过程的实现。 RDD Shuffle简介 spark的某些操作会触发被称为shuffle的事件。shuffle是Spark重新分配数据的机制,它可以对数据进行分组,该操作可以跨不同分区。该操作通常会在不同的执行器(executor)和主机之间复制数据,这使shuffle成为复杂且非常消耗资源的操作。 Shuffle背景 为了理