本文主要是介绍【大数据面试知识点】Spark中的累加器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Spark累加器
累加器用来把Executor端变量信息聚合到Driver端,在driver程序中定义的变量,在Executor端的每个task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回driver端进行merge。
累加器一般是放在行动算子中进行操作的。
Spark累加器有哪些特点?
1)累加器在全局唯一的,只增不减,记录全局集群的唯一状态
2)在Executor中修改它,在Driver读取
3)executor级别共享的,广播变量是task级别的共享两个application不可以共享累加器,但是同一个app不同的job可以共享
应用举例
不经过Shuffle实现词频统计
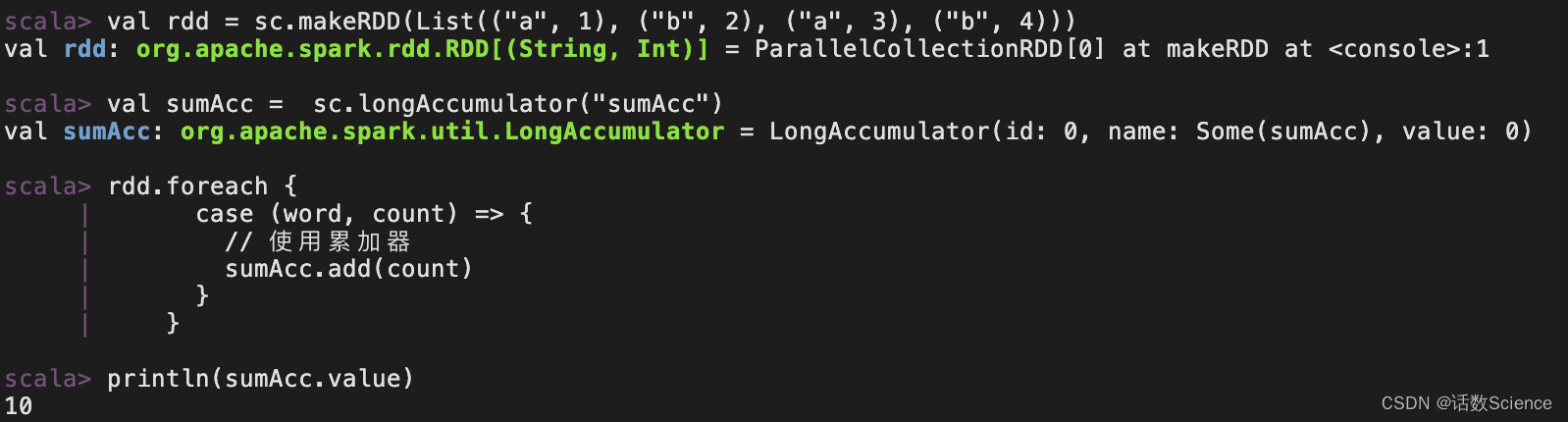
object Spark06_Accumulator {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName(this.getClass.getName).setMaster("local[*]")val sc = new SparkContext(conf)val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2), ("a", 3), ("b", 4)))// 声明累加器val sumAcc: LongAccumulator = sc.longAccumulator("sumAcc")rdd.foreach {case (word, count) => {// 使用累加器sumAcc.add(count)}}// 累加器的toString方法//println(sumAcc)//取出累加器中的值println(sumAcc.value)sc.stop()}
}
不经过shuffle,计算以H开头的单词出现的次数。
object Spark07_MyAccumulator {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName(this.getClass.getName).setMaster("local[*]")val sc = new SparkContext(conf)val rdd: RDD[String] = sc.makeRDD(List("Hello", "HaHa", "spark", "scala", "Hi", "Hello", "Hi"))// 创建累加器val myAcc = new MyAccumulator//注册累加器sc.register(myAcc, "MyAcc")rdd.foreach{datas => {// 使用累加器myAcc.add(datas)}}// 获取累加器的结果println(myAcc.value)sc.stop()}
}// 自定义累加器
// 泛型分别为输入类型和输出类型
class MyAccumulator extends AccumulatorV2[String, mutable.Map[String, Int]] {// 定义输出数据变量var map: mutable.Map[String, Int] = mutable.Map[String, Int]()// 累加器是否为初始状态override def isZero: Boolean = map.isEmpty// 复制累加器override def copy(): AccumulatorV2[String, mutable.Map[String, Int]] = {val MyAcc = new MyAccumulator// 将此累加器中的数据赋值给新创建的累加器MyAcc.map = this.mapMyAcc}// 重置累加器override def reset(): Unit = {map.clear()}// 累加器添加元素override def add(v: String): Unit = {if (v.startsWith("H")) {// 判断map集合中是否已经存在此元素map(v) = map.getOrElse(v, 0) + 1}}// 合并累加器中的元素override def merge(other: AccumulatorV2[String, mutable.Map[String, Int]]): Unit = {val map1: mutable.Map[String, Int] = this.mapval map2: mutable.Map[String, Int] = other.value// 合并两个mapmap = map1.foldLeft(map2) {(m, kv) => {m(kv._1) = m.getOrElse(kv._1, 0) + kv._2m}}}// 获取累加器中的值override def value: mutable.Map[String, Int] = {map}
}
参考:Spark累加器的作用和使用-CSDN博客
这篇关于【大数据面试知识点】Spark中的累加器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





