相关度专题


【机器学习】4. 相似性比较(二值化数据)与相关度(correlation)
SMC Simple Matching Coefficient 评估两组二进制数组相似性的参数 SMC = (f11 + f00) / (f01+f10+f11+f00) 其中,f11表示两组都为1的组合个数,f10表示第一组为1,第二组为0的组合个数。 这样做会有一个缺点,假设是比较稀疏的数据,如今天去哪一个地区,地区有成千上万个,但是去的只有一个地区。那么就会导致f00非常的大,如此计算


Elasticsearch学习笔记-第48节:初识搜索引擎_filter与query深入对比解密:相关度,性能
课程大纲 1、filter与query示例 PUT /company/employee/2 { "address": { "country": "china", "province": "jiangsu", "city": "nanjing" }, "name": "tom", "age": 30, "join_date": "2016-01-01"

TF-IDF、向量空间模型和余弦相关度
一、TF-IDF TF-IDF是信息检索和数据挖掘中常用的一种加权技术。它是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。 TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。 TF词频(Term Frequency)指的是某一个给定的词语在该文件中出现的频

elasticsearch(12)用function_score自定义相关度分数算法
转载自CSDN本文链接地址: ElasticSearch用function_score自定义相关度分数算法 需求 在field: tile 和 content 中查找 java spark 的doc要求follower_num越多的 doc 分数越高。(看帖子的人越多,那么帖子的分数就越高) function_score函数: 我们可以做到自定义一个function_score函数自己将某
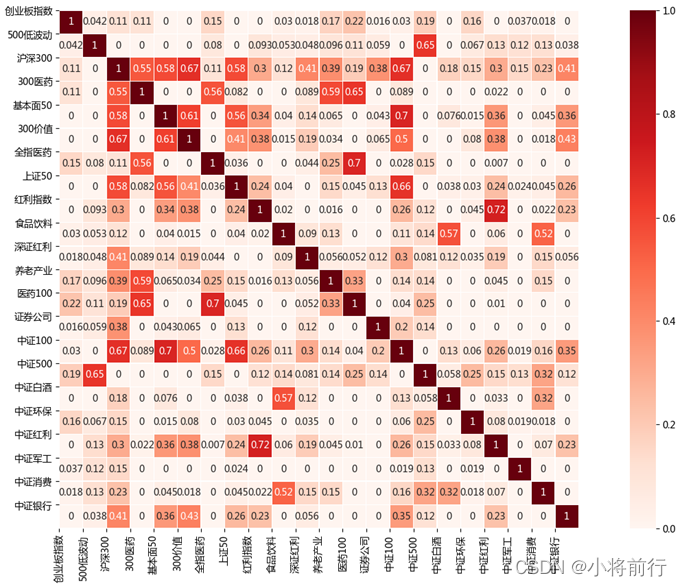
基于Python的指数基金量化投资——指数基金间相关度计算
每一种指数基金都是由一篮子股票组成的,少的有几十个成分股,多的有几百上千个成分股,而整个A股目前有四千多家上市公司,每种指数基金都从A股这个大篮子里面选取成分股,那就会有个问题,不同的指数基金选择的成分股会有重叠,重叠度是多少,这是一个很重要的指标。 从投资的角度来看,一定程度的分散覆盖度更好,同时抗非系统风险能力也会更强,但如果太分散也不好,过度分散和买下整个A股没有什么区别,投资收益也会变低

搜索引擎的检索模型-查询与文档的相关度计算
1. 检索模型概述 搜索结果排序时搜索引擎最核心的部分,很大程度度上决定了搜索引擎的质量好坏及用户满意度。实际搜索结果排序的因子有很多,但最主要的两个因素是用户查询和网页内容的相关度,以及网页链接情况。这里我们主要总结网页内容和用户查询相关的内容。 判断网页内容是否与用户査询相关,这依赖于搜索引擎所来用的检索模型。检索模型是搜索引擎的理论
Lucene教程--维护索引、查询对象和相关度排序
1 索引维护 1.1 添加索引 步骤: 1)创建存放索引的目录Directory 2)创建索引器配置管理类IndexWriterConfig 3)使用索引目录和配置管理类创建索引器 4)使用索引器将Document写到索引文件中 代码: // 定义索引存储目录Directory directory = FSDirectory.open(new File(indexFolde
[Elasticsearch] 控制相关度 (二) - Lucene中的PSF(Practical Scoring Function)与查询期间提升
Lucene中的Practical Scoring Function 对于多词条查询(Multiterm Queries),Lucene使用的是布尔模型(Boolean Model),TF/IDF以及向量空间模型(Vector Space Model)来将它们结合在一起,用来收集匹配的文档和对它们进行分值计算。 像下面这样的多词条查询: GET /my_index/doc/_s
[Elasticsearch] 控制相关度 (一) - 相关度分值计算背后的理论
控制相关度(Controlling Relevance) 对于仅处理结构化数据(比如日期,数值和字符枚举值)的数据库,它们只需要检查一份文档(在关系数据库中是一行)是否匹配查询即可。 尽管布尔类型的YES|NO匹配也是全文搜索的一个必要组成,它们本身是不够的。我们还需要知道每份文档和查询之间的相关程度。全文搜索引擎不仅要找到匹配的文档,还需要根据相关度对它们进行排序。 全文搜索

回归中的相关度和R平方值(麦子学院)
回归中的相关度和R平方值 皮尔逊相关系数 (Pearson Correlation Coefficient): 1.1 衡量两个值线性相关强度的量 1.2 取值范围 [-1, 1]: 正向相关: >0, 负向相关:<0, 无相关性:=0 1.3 计算方法举例: X Y 1 10 3 12 8 24 7 21 9 34 其他例子:

机器学习(回归问题中的相关度和决定系数)
1.皮尔狲相关系数: 1.1衡量两个值线性相关强度的量 1.2取值范围:[-1,1]: 正向相关:>0,负向相关:<0,无相关性:=0 ρ = Cor(X,Y)=Cov(X,Y)/sqrt(Var(X)*Var(Y)) 2.R平方值 2.1定义:决定系数,反应因变量的全部变异能通过回归关系被自变量解释的比例 2.2描述:如R平方为0.8,则表示回归关系可以解释因变量80%的变异,换句