本文主要是介绍基于Python的指数基金量化投资——指数基金间相关度计算,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
每一种指数基金都是由一篮子股票组成的,少的有几十个成分股,多的有几百上千个成分股,而整个A股目前有四千多家上市公司,每种指数基金都从A股这个大篮子里面选取成分股,那就会有个问题,不同的指数基金选择的成分股会有重叠,重叠度是多少,这是一个很重要的指标。
从投资的角度来看,一定程度的分散覆盖度更好,同时抗非系统风险能力也会更强,但如果太分散也不好,过度分散和买下整个A股没有什么区别,投资收益也会变低。
举个例子,如果指数A包含100个成分股,指数B也包含100个成分股,但他们有50个成分股是相同的,不考虑权重影响的情况下,他们的相似度就是50%,意味着如果你买入1份指数A的话,相当于间接买入了0.5份的指数B。
在我们的实际投资过程中,不可能只投资一只指数基金,所以肯定会存在相关度的问题,在选择投资品种的时候要通过相关度选择相关性低的指数基金形成组合来进行投资。
那怎么获得指数基金间的相关度数据呢,可以简单考虑个股的重合度来进行考量,通过下面的简单公式进行计算:
(Cnt/LenA + Cnt/LenB)/ 2
Cnt表示A指数和B指数的重叠成分股数量
LenA表示A指数成分股数量
LenB表示B指数成分股数量
通过这个计算公式可以获得下面的矩阵相关图,横坐标和纵坐标对应相应的指数基金品种,图中的数据表示横纵坐标指数对应的相关度数据。
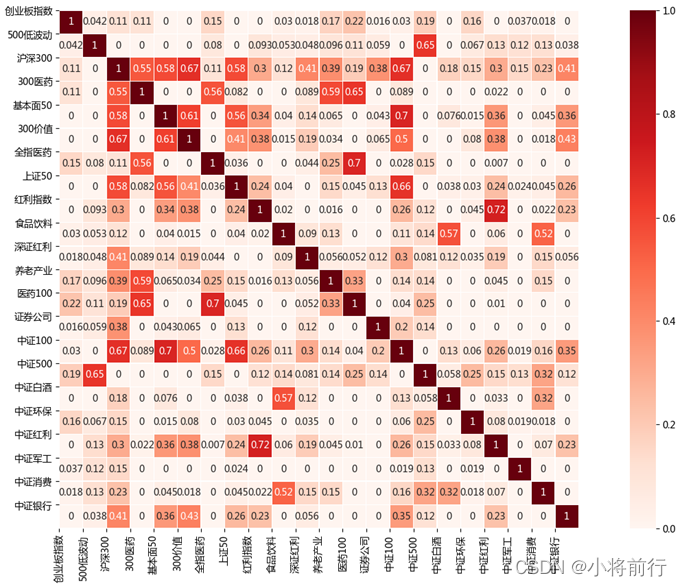
例如,沪深300和300医药的相关度为0.55,沪深300和全指医药的相关度为0.11,沪深300和医药100的相关度为0.19,沪深300和中证500的相关度为0,创业板指和医药100的相关度为0.22。
对角线由于指数基金是一致的,也就是自己和自己相关,所以对应的数据全是1。
从上面的矩阵图中能很清晰的看出各个指数基金的相关度,选择相关度低的进行投资,如果数据为0是最好的,例如沪深300加中证500进行组合,中证白酒+中证医药进行组合;避免相关度高的进行投资,例如基本面50+中证100进行组合、中证红利+红利指数进行组合。
源码
#源码中用到的indexType文件下的指数数据.csv请参看《基于Python的指数基金量化投资——指数包含的个股数据获取》
import pandas as pd
import os
import numpy as np
import matplotlib.pyplot as plt
import seaborn as snsnum_file = os.listdir('./importfile/indexSeries/indexTpye/')
name_file = list()relation_matrix = np.zeros((len(num_file), len(num_file)))
col = 0
row = 0
for index_a_name in os.listdir('./importfile/indexSeries/indexTpye/'):label_name = pd.read_csv('./importfile/indexSeries/indexTpye/' + index_a_name)name_file.append(label_name.values[1][2])for index_b_name in os.listdir('./importfile/indexSeries/indexTpye/')这篇关于基于Python的指数基金量化投资——指数基金间相关度计算的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




