用词专题

【Python 走进NLP】NLP词频统计和处理停用词,可视化
# coding=utf-8import requestsimport sysreload(sys)sys.setdefaultencoding('utf-8')from lxml import etreeimport timetime1=time.time()import bs4import nltkfrom bs4 import BeautifulSoupfrom

NLP-文本匹配-2013:DSSM【首次提出将深度学习应用到文本匹配,每个文本对象均由5层的神经网络进行向量化表示,最后通过向量间的余弦值来衡量文本对象的相似度】【釆用词袋模型,丢失单词顺序关系】
深度语义结构模型(DSSM)首次提出了将深度学习应用到文本匹配方法中,该模型通过建模用户查询和文档的匹配度,同传统文本匹配模型相比获得了显著的提升。在深度语义结构模型中,每个文本对象均由5层的神经网络进行向量化表示,最后通过向量间的余弦值来衡量文本对象的相似度 DSSM模型由宁完全采用全连接神经网络构建,以至于参数较多,不利于模型参数的学习与优化,并且DSSM模型在获取词(片段)嵌入时釆用了词袋

用ChatGPT提升论文质量:改进语法、用词和行文的有效方法
学境思源,一键生成论文初稿: AcademicIdeas - 学境思源AI论文写作 在学术写作中,语法、用词和行文的质量直接影响论文的可读性和学术价值。今天我们将介绍如何利用ChatGPT优化论文的语法结构、改进用词精准度以及提升行文流畅性。帮助写作者在撰写过程中克服常见语言障碍,从而提高学术成果的表达效果和专业水平。通过具体实例分享如何充分发挥ChatGPT的优势,提升论文的整体质量。

12、自定义Analyzer实现扩展停用词
自定义Analyzer实现扩展停用词 继承自Analyzer并覆写createComponents(String)方法维护自己的停用词词典重写TokenStreamComponents,选择合适的过滤策略 import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.CharArraySet;

Spark MLlib 特征工程系列—特征转换Tokenizer和移除停用词
Spark MLlib 特征工程系列—特征转换Tokenizer和移除停用词 Tokenizer和RegexTokenizer 在Spark中,Tokenizer 和 RegexTokenizer 都是用于文本处理的工具,主要用于将字符串分割成单词(tokens),但它们的工作方式和使用场景有所不同。 1. Tokenizer 功能: Tokenizer 是最简单的分词器,它基于空格(wh

Python 机器学习 基础 之 处理文本数据 【停用词/用tf-idf缩放数据/模型系数/多个单词的词袋/高级分词/主题建模/文档聚类】的简单说明
Python 机器学习 基础 之 处理文本数据 【停用词/用tf-idf缩放数据/模型系数/多个单词的词袋/高级分词/主题建模/文档聚类】的简单说明 目录 Python 机器学习 基础 之 处理文本数据 【停用词/用tf-idf缩放数据/模型系数/多个单词的词袋/高级分词/主题建模/文档聚类】的简单说明 一、简单介绍 二、停用词 三、用tf-idf缩放数据 四、研究模型系数 五、

【AI系列】Python NLTK 库和停用词处理的应用
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学习,不断总结,共同进步,活到老学到老导航 檀越剑指大厂系列:全面总结 java 核心技术点,如集合,jvm,并发编程 redis,kafka,Spring,微服务,Netty 等常用开发工具系列:罗列

苹果商城怎么调成中文_ESVSOMG|Essay写作怎么用词用的准?_什么
原标题:Essay写作怎么用词用的准? 很多同学都说自己英文Essay写的不好,但中文Essay写的得心应手,这是什么原因呢,其实大家都知道,这是因为我们的用词不准确,要么就是口语当做书面语在用,要么就是选词让人觉得词不达意,显得文不对题。要想提高自己的写作水平,必须要改正这个问题,用词不准确,Essay的分数永远不会高。不仅打击自信,还影响毕业。今天小编特意总结了一些小知识,告诉大家怎样才

使用jieba库进行中文分词和去除停用词
jieba.lcut jieba.lcut()和jieba.lcut_for_search()是jieba库中的两个分词函数,它们的功能和参数略有不同。 jieba.lcut()方法接受三个参数:需要分词的字符串,是否使用全模式(默认为False)以及是否使用HMM模型(默认为True)。它返回一个列表,其中包含分词后的词语。该方法适合用于普通的文本分词任务。 而jieba.lcut_fo
wordcloud词云图和jieba分词,过滤不要的词句(停用词)
"""生成中文词云步骤1、读取文件内容2、借助jieba分词库对中文进行分词,让后将结果合并,以空格隔开3、打开图片文件,得到对应数组(可以设置图片的形状;图片中的白色部分不显示)4、创建WordCloud对象,设置基本属性 (创建词云对象,将文本生成词云generate,再用画出词云图,并显示)5、生成词云图,并保存或显示图片中文中需要设置停用词的话可以有三种方法:(过滤不需要的)

NLP分词中的2750个停用词和9995个同义词
停用词: 在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。 这些停用词都是人工输入、非自动化生成的,生成后的停用词会形成一个停用词表。但是,并没有一个明确的停用词表能够适用于所有的工具,甚至有一些工具是明确地避免使用停用词来支持短语搜索的。 对于一个给定的目的,任何一类的词语都可以被选
Python 中文分词并去除停用词
import jieba# 创建停用词listdef stopwordslist(filepath):stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]return stopwords# 对句子进行分词def seg_sentence(sentence):sent
如何用词向量做文本分类(embedding+cnn)
1、数据简介 本文使用的数据集是著名的”20 Newsgroup dataset”。该数据集共有20种新闻文本数据,我们将实现对该数据集的文本分类任务。数据集的说明和下载请参考(http://www.cs.cmu.edu/afs/cs.cmu.edu/project/theo-20/www/data/news20.html)。本文使用GloVe词向量。GloVe 是 “Global Vector
r语言小白求助正在学习用R语言做词云 加入停用词后一直报错
正在学习用R语言词云,不加入停用词做出来的不准确,但加入停用词后一直报错,请问是哪里出了问题?` > library(readxl) library(jiebaR,jiebaRD) 载入需要的程辑包:jiebaRD library(jiebaR,jiebaRD) library(wordcloud2) new<-read_excel(“D:\fgo.xlsx”) > text<-new$评论内
ElasticSearch 集群 7.9.0 linux (CentOS 7部署)包含Mysql动态加载同义词、基础词、停用词,Hanlp分词器,ik分词器,x-pack)
linux服务器配置要求: /etc/sysctl.conf文件最后添加一行 vm.max_map_count=262144 /sbin/sysctl -p 验证是否生效 修改文件/etc/security/limits.conf,最后添加以下内容。 * soft nofile 65536* hard nofile 65536* soft nproc 32000* hard npr

ElasticSearch(七)【扩展词、停用词配置】
七、扩展词、停用词配置 上一篇文章《ElasticSearch - 分词器》 IK支持自定义扩展词典和停用词典 扩展词典就是有些词并不是关键词,但是也希望被ES用来作为检索的关键词,可以将这些词加入扩展词典停用词典就是有些词是关键词,但是出于业务场景不想使用这些关键词被检索到,可以将这些词放入停用词典 定义扩展词典和停用词典可以修改IK分词器中config目录中IKAnalyzer.c

python获取登录按钮_Python爬虫:使用Python动态爬取冯大辉老师微博,再用词云分析...
冯大辉老师在程序员圈子中还是比较出名的,大部分都知道他这个人,性格很鲜明。他现在正在创业,公司叫无码科技,他有一个公众号叫小道消息,新榜给的活跃粉丝是30多万数据,他的微博有180万粉,这说明冯老师在科技界还是很有影响力的。 事情是这样的,上周的一天公众号又照例收到了大辉老师的文章,我就在他的文章底下留言了,说要爬爬他的文章。 这是我用冯老师最近5000多条微博内容做的词云,大家可以围观一下
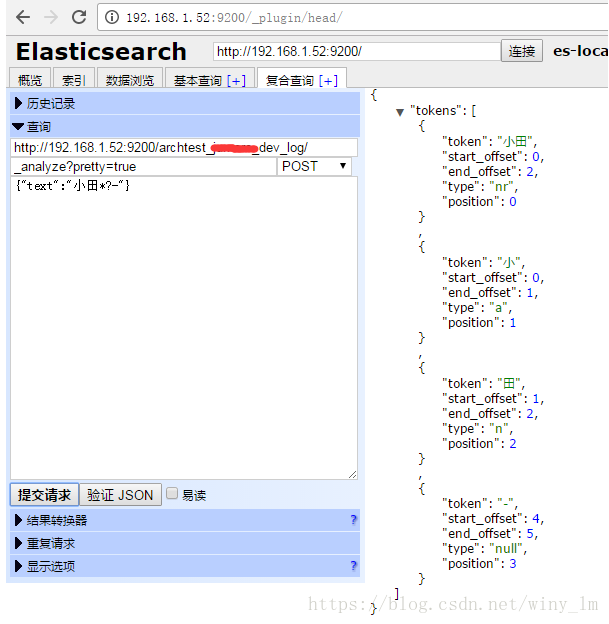
Elasticsearch ansj的停用词设置
1. 配置方法 1.1 修改elasticsearch.yml配置文件: - 打开启用停用词开关 enabled_stop_filter: true ##是否基于词典过滤 - 配置停用词文件路径: 注意这里必须是相对于 elasticsearch.yml配置文件 位置的 相对路径。 stop_path: "../dic_stop/stop.dic" ##停止过滤词典 1.2 放置

NLP情感分析和可视化|python实现评论内容的文本清洗、语料库分词、去除停用词、建立TF-IDF矩阵、获取主题词和主题词团
1 文本数据准备 首先文本数据准备,爬取李佳琦下的评论,如下: 2 提出文本数据、获得评论内容 #内容读取import xlrdimport pandas as pdwb=xlrd.open_workbook("评论数据.xlsx")sh=wb.sheet_by_index(0)col=sh.ncolsrow=sh.nrowsText=[]for i in range(r
IK分词源码分析连载(四)--停用词+未切分词处理
转载请注明出处: http://blog.chinaunix.net/uid-20761674-id-3425302.html 前面三篇文章介绍了IK分词的两个核心模块:子分词器和歧义处理,这篇文章收尾,介绍停用词以及未切分词的处理方法: process已经介绍过了,接下来关注processUnknownCJKChar()和getNextLexeme() //对