标量专题

NumPy(四):数学运算【数组与标量的运算:加减乘除】【数组与数组的运算(广播机制)】
一、ndarray数组与标量的运算:加减乘除 import numpy as npar = np.arange(6).reshape(2, 3)print('ar = ', ar)# 数组与标量的简单运算print('ar + 10 = ', ar + 10) # 加法print('ar * 2 = ', ar * 2) # 乘法print('1 / (ar + 1) = ', 1

利用字符截取函数substring,charindex replace 等函数定义标量函数
ALTER function [dbo].[Zfun_bage](@UDF02 char(40)) returns int as --把包装方法自动计算成件数 BEGIN declare @A CHAR(20) declare @num int select top 1 @A=UDF02 from COPTH WHERE UDF02=@UDF02 if (CHARINDEX

Greenplum标量查询及常用示例
标量查询是指仅返回单个值的查询,而不是返回多行或多列的结果集。在Greenplum数据库中,标量查询通常用于获取单个值,以供其他查询、计算或条件判断使用。 以下是几个标量查询的示例: 1. 获取表中的最大值: SELECT MAX(column) FROM mytable; 2. 统计表中的行数: SELECT COUNT(*) FROM mytable; 3. 检查某个条件是否满
维度/标量/张量/一维/二维/三维/shape/size/索引/view理解
维度是对不类型的描述,有几个不同的类型就有几个不同的维度. 张量是用来描述维度更宽泛的概念 标量是一个数. 一维是一组数据. 二维是两个不同特征组合的数据. 三维是三个不同的特征组合的数据.[] 只是用来表示区间范围套更多的[]是为了表示不同的维度,要理解维度 含义而不是只看[]. 生活例子 假设我们有一个书架,书架有很多层,每层放着书: 索引 (Index):就像书架上书的位置,比

【论文阅读】-- 时态合并树状图:时态标量数据的基于拓扑的静态可视化
时态合并树状图:时态标量数据的基于拓扑的静态可视化 摘要1 引言2 相关工作及背景介绍2.1 增广合并树2.2 (增强)合并树的可视化与跟踪2.3 特征跟踪2.4 数据线性化 3 时间合并树状图3.1 映射单个时间步长: R d → R R^d \rightarrow R Rd→R3.2 映射所有时间步: R d + 1 → R 2 R^{d + 1} \rightarrow R^2 Rd

JAVA逃逸分析、栈上分配、标量替换、同步消除
一、逃逸分析 逃逸分析是编译语言中的一种优化分析,而不是一种优化的手段。通过对象的作用范围的分析,为其他优化手段提供分析数据从而进行优化。 逃逸分析包括: 全局变量赋值逃逸方法返回值逃逸实例引用发生逃逸线程逃逸:赋值给类变量或可以在其他线程中访问的实例变量. public class EscapeAnalysis {public static Object object;public voi

莫名其妙的SqlServer更新错误:OleDbException 必须声明标量变量
以前一直使用OleDbDataAdapter的方式更新数据库,今天我试了一下用OleDbCommand的方式更新数据库出现了莫名其妙的错误。 环境:Sql Server 2005 使用如下代码: string strSql = " UPDATE M_Employee set EMPLOYEENAME = @EMPLOYEENAME where EMP
逃逸分析、标量替换、锁消除是什么
1、逃逸分析(Escape Analysis): 逃逸分析是一种分析技术,用于分析对象的动态作用域。它分析一个对象是否只会在方法内部被引用,还是可能会被外部方法或线程所引用。逃逸分析的主要目的是判断对象是否“逃逸”出了方法或线程的作用域。根据逃逸分析的结果,JVM可以决定是否对该对象进行优化,如栈上分配、标量替换或同步消除。 1、方法逃逸:当一个对象在方法中被定义后,它可能被外部方法所引用,例如
【PyTorch】标量、向量、张量的直观理解
标量 标量就是一个数字。标量也称为0维数组。 比如5套房子中的“5”就是标量; 向量 向量是一组标量组成的列表。向量也称为1维数组。 比如房子的价格是受多种因素(是否为学区房、附近有无地铁、房子面积、房间数量、楼层等)来影响,那么我们将这多种因素来表示为房子的特征,这一组特征值就可以用向量表示。 矩阵 矩阵是由一组向量组成的集合。矩阵也称为2维数组。 在刚才的例子中,一套房子的特征
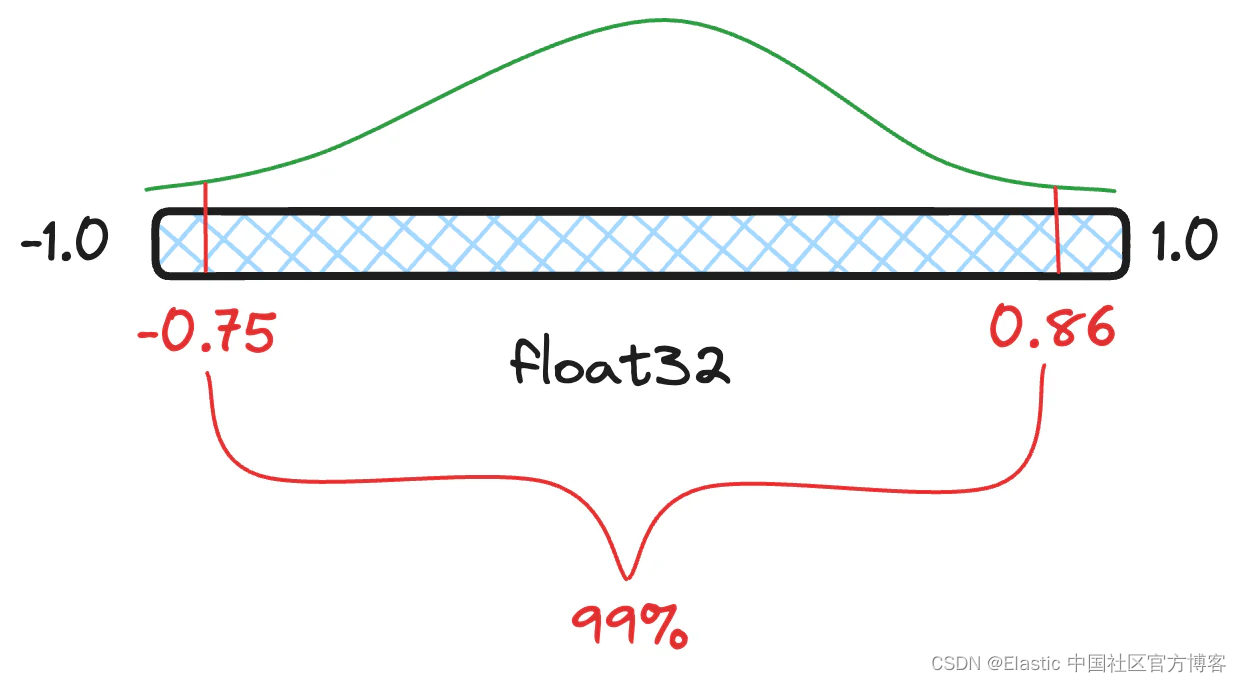
评估 Elasticsearch 中的标量量化
作者:来自 Elastic Thanos Papaoikonomou, Thomas Veasey 在 8.13 版本中,我们为 Elasticsearch 引入了标量量化功能。通过使用此功能,最终用户可以提供浮点向量,这些向量在内部作为字节向量进行索引,同时在索引中保留浮点向量,以便可选地重新评分。这意味着他们可以将索引内存需求降低四分之一,这是其主要成本。目前,这是一个可选择加入的功能,但我
逃逸分析、栈上分配、标量替换大展神威
一、逃逸分析 1.逃逸分析的目的是判断对象的作用域是否会逃逸出方法体(方法逃逸)或者外部线程(线程逃逸)。 2.注意,任何可以在多个线程之间共享的对象,一定都属于逃逸对象。 3.若重写了一个类的finalize方法,则这个类的变量会被标记为全局逃逸状态,且会被放在堆内存中。 4.若一个对象不会逃逸到方法或其他线程之外,则可以对此对象进行高效优化。 5.默认情况下32位的hotspot虚拟机都是cl
标量值函数 日期转换
create FUNCTION [dbo].[GetDateTimeString] (@Input varchar(60)) RETURNS VARCHAR(20)AS BEGIN DECLARE @StringDate VARCHAR(20) SET @StringDate = REPLACE(@Input, 'T', ' ') RETURN @StringDateE
sqlserver 调用存储过程时出现必须声明标量变量 @ReturnMsg的解决方法
因为项目需要写了一个存储过程,但是调用的时候却一直提示必须声明标量变量,然后将调用过成改造一下就好了,正确调用代码如下: BEGIN --将代码包围到begin end块中,要不然会提示必须声明标量变量 DECLARE @Updatetime1 varchar(50) = '2017-06-21 09:10:10'; DECLARE @Orgguid1 varchar(50)= '2';
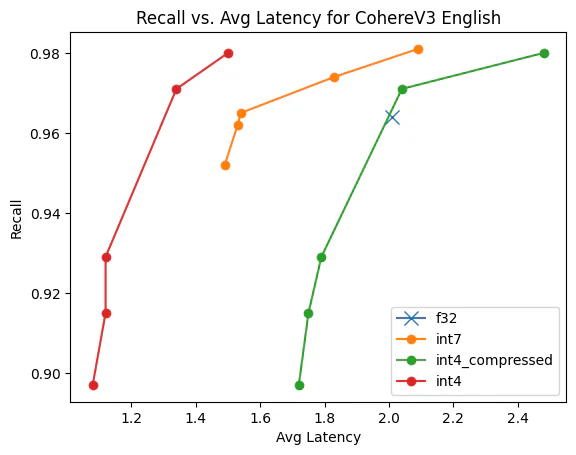
Int4:Lucene 中的更多标量量化
作者:来自 Elastic Benjamin Trent, Thomas Veasey 在 Lucene 中引入 Int4 量化 在之前的博客中,我们全面介绍了 Lucene 中标量量化的实现。 我们还探索了两种具体的量化优化。 现在我们遇到了一个问题:int4 量化在 Lucene 中是如何工作的以及它是如何排列的? 存储量化向量并对其进行评分 Lucene 将所有向量存储在一个

Perl语言入门读书笔记 | 二. 标量数据
所谓直接量,其实就是常量。 1. 数字 在Perl内部所有的数字按double类型来存储,即Perl不存在int类型; print 7.25e45; # 7.25乘以10的45次方# print 7.25E45; # 错误print 61_298_040_283_768; # 通过下划线使大数更清楚print 0b11111111; # 二进制的11111111,等于十进制的255

matlab教程之矩阵的标量、转置操作实例
1、矩阵的标量操作,也就是矩阵与常量之间的+ - * / a=[1,2,3;4,5,6];b=3;c=a+bd=a-be=a*bf=a/b 2、矩阵的转置操作 有2行三列变成3行2列 a=[1,2,3;4,5,6];b=a'
tf.contrib.keras.preprocessing.sequence.pad_sequences 将标量数据 转换成numpy ndarray
keras.preprocessing.sequence.pad_sequences(sequences, maxlen=None, dtype=’int32’, padding=’pre’, truncating=’pre’, value=0.) 函数说明: 将长为nb_samples的序列(标量序列)转化为形如(nb_samples,nb_timesteps)2D numpy array。

【计算机系统结构】第五章:标量处理机
第一节:重叠方式 知识点1:重叠原理与一次重叠 顺序解释指的是各条指令之间顺序串行(执行完一条指令后才取下条指令)地进行,每条指令内部的各个微操作也顺序串行地进行。 解释一条机器指令的微操作可归并成取指令、分析和执行三部分,时间关系如图5-1所示。 取指是按指令计数器的内容访主存,取出该指令送到指令寄存器。指令的分析是对指令的操作码进行译码,按寻址方式和地址字段形成操作数真地址,并用此
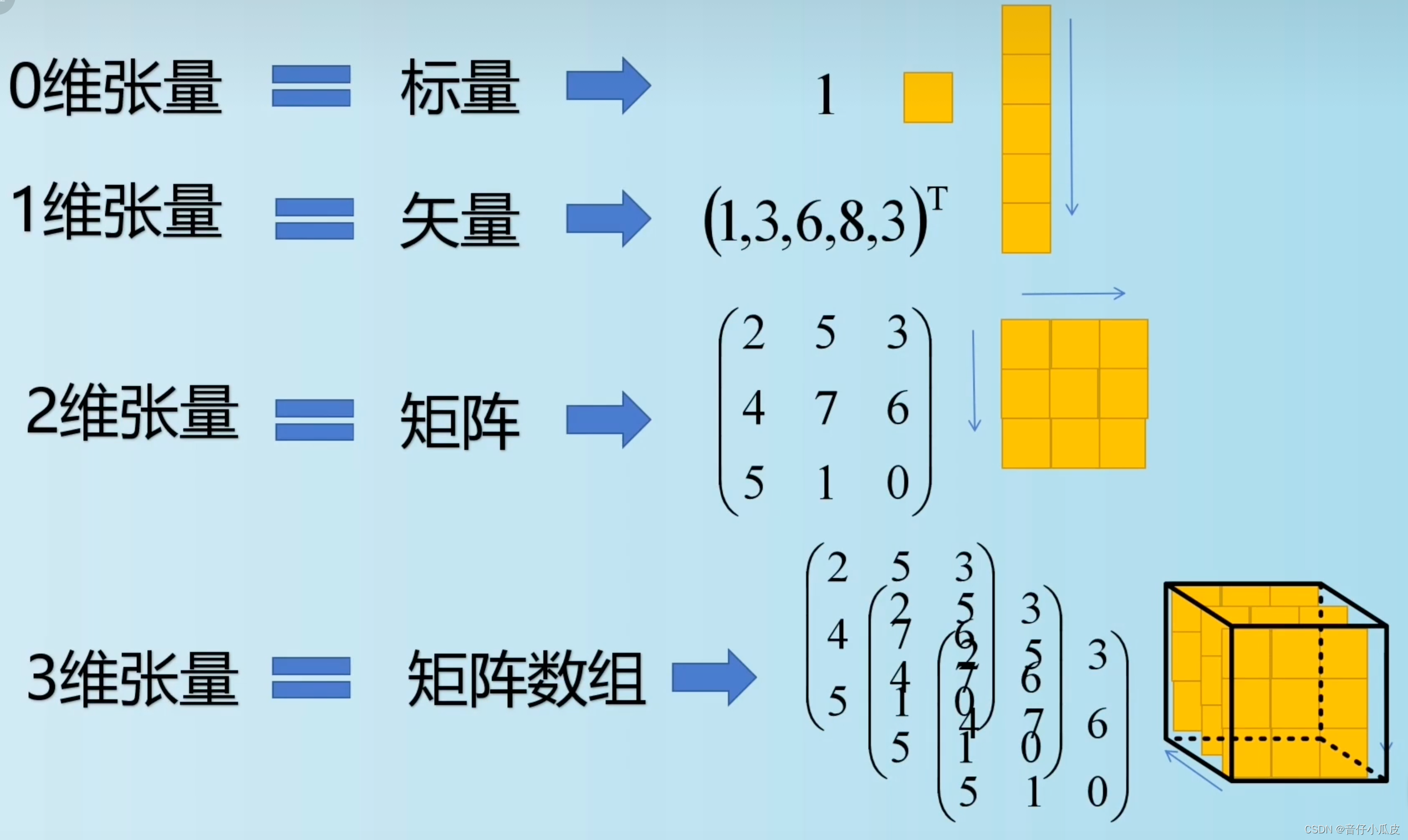
【线代基础】张量、向量、标量、矩阵的区别
1、标量(Scalar) 纯数字,无方向性、无维度概念。因此也叫 标量张量、零维张量、0D张量 例如,x1=8,x2=1.34 x1、x2即为标量 2、张量(tensor) 具有方向性,可以理解为一个多维数组,它是标量、向量、矩阵的高维扩展,属于一个数据容器。理论上,张量是向量概念上的推广,可以理解为其在多个维度的扩展。 通常,张量的维度被称作轴(axis),张量轴的个数也叫做阶(ra
场的概念---数量场(标量场)和矢量场介绍理解
目录 一、场的概念 二、场的分类 三、数量场(标量场)的等值面 四、矢量场中的矢量线 矢量线方程推导: 一、场的概念 场在数学上是指一个向量到另一个向量或数的映射。场指物体在空间中的分布情况。场是用空间位置函数来表征的。在物理学中,经常要研究某种物理量在空间的分布和变化规律。 场https://baike.baidu.com/item/%E5%9C%BA/7451287

估计理论笔记1 - 标量下Cramer Rao LB公式推导以及与MVUE的关系
CRLB的推导其实有两个关键的地方,第一个关键的是如何理解满足"正则"条件,第二个地方是柯西不等式的使用,并且在柯西不等式取等号的时候,与统计量的MVUE的联系。 第一 : 正则条件,他的意思其实就是说,你再使用概率密度函数的时候,这些个带参数的概率目的函数是满足概率密度函数的定义的,在直接一点讲,概蜜在x轴上的积分等于1,这个在证明中使用到了 第二:柯西不等式取等号的条件,是在a = kb的
Elasticsearch:dense vector 数据类型及标量量化
密集向量(dense_vector)字段类型存储数值的密集向量。 密集向量场主要用于 k 最近邻 (kNN) 搜索。 dense_vector 类型不支持聚合或排序。 默认情况下,你可以基于 element_type 添加一个 dend_vector 字段作为 float 数值数组: PUT my-index{"mappings": {"properties": {"my_vector
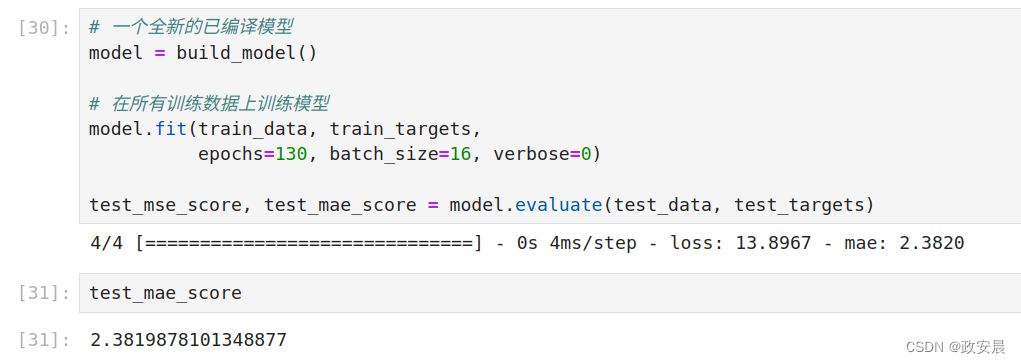
政安晨:【示例演绎机器学习】(四)—— 神经网络的标量回归问题示例 (价格预测)
政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: 政安晨的机器学习笔记 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正,让小伙伴们一起学习、交流进步,不论是学业还是工作都取得好成绩! 前言 咱们这个系列的前面几篇机器学习示例演绎的文章中,演绎的都是分类问题,其目标是预测输入数据点所对应的单一离散标签。 其实还有另一种常见的机器学习问题是回归(reg
Rust标量类型详解
在Rust中,数据类型分为标量类型和复合类型。本篇博客将重点介绍Rust的标量类型,其中包括整数类型、浮点类型、布尔类型以及字符类型。 整数类型 Rust提供了多种整数类型,分为带符号整数和无符号整数。带符号整数表示可以为正数、零或负数,而无符号整数则仅表示非负数。 带符号整数(i类型) let n1: i8 = 10;let n2: i64 = 0b1111_000; 在上述代码中
mxnet nd中的asscalar() 向量转换为标量 转
X.asscalar() 将向量X转换成标量,且向量X只能为一维含单个元素的向量 X:nd类型的数据 创建一个单个元素的向量 test=nd.array([2]) 输出: [2.] <NDArray 1 @cpu(0)> 转换成标量: test.asscalar() 输出:2.0 https://blog.csdn.net/shenkunchang1877/arti