描述性专题

数学建模~~描述性分析---RFM用户分层模型聚类
目录 1.RFM用户分层模型介绍 2.获取数据,标准化处理 2.1获取数据 2.2时间类型转换 2.3计算时间间隔 3.对于R,F,M的描述性分析 3.1代码分析 3.2分析结果说明 3.3对于F的描述性分析 3.4对于M的描述性分析 4.数据分箱--等级划分 4.1分箱概念 4.3分箱特点 4.3分箱方式 4.4总结分析 5.综合评价 6.K中心聚类分析
python数据分析---ch11 python数据描述性统计
python数据分析--- ch11 python数据描述性统计 1. Ch11--描述性统计2. 数据集中趋势的度量2.1 平均值2.2 中位数2.3 众数2.4 几何平均值2.5 调和平均值 3. 数据离散趋势的度量3.1 极差3.2 平均绝对偏差(MAD)3.3 方差和标准差3.4 下偏方差和下偏标准差3.5 目标下偏方差和目标下偏标准差 4. 峰度、偏度与正态性检验4.1 偏度4.2

《LoadRunner 没有告诉你的》之一——描述性统计与性能结果分析
http://www.cnblogs.com/jackei/archive/2006/12/04/558720.html LoadRunner中的90%响应时间是什么意思?这个值在进行性能分析时有什么作用?本文争取用最简洁的文字来解答这个问题,并引申出“描述性统计”方法在性能测试结果分析中的应用。 为什么要有90%用户响应时间?因为在评估一次测试的结果时,仅仅有平均事务响应

为pytorch前向和反向的Tensor生成描述性统计
为pytorch前向和反向的Tensor生成描述性统计 代码 在调试Megatron-DeepSpeed的精度时,我们希望对比每一层前向和反向传播的输入输出误差。然而,由于数据量过大,直接保存所有数据不太现实。因此,我们生成了输入输出tensor的描述性统计信息,并等间隔抽样N个数据点,以比较这些点的相对误差,从而查找精度异常的位置。为了准确定位,我们通过类名和对象ID生成唯一的对象
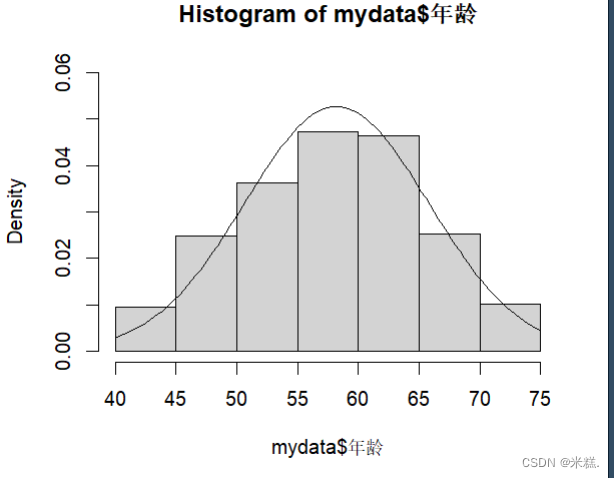
【R语言】描述性数据分析与数据可视化
我们处理的变量可以分为两类,一类是连续型变量,另一类叫做分类型变量,其中对于连续型变量,如果服从正态分布就用平均值填充NA,不服从正态分布就用中位数填充NA,对于分类型变量,不管是有序的(比如一年级,二年级)还是无序的(比如男性,女性)都是用众数来填补NA。 分类型变量的描述性数据分析 对于分类型变量,我们只需要关心每一类变量有多少个以及他的众数,使用的函数为table(变量),table函数

在Python里,用股票案例讲描述性统计分析方法(内容来自我的书)
描述性统计是数学统计分析里的一种方法,通过这种统计方法,能分析出数据整体状况以及数据间的关联。在这部分里,将用股票数据为样本,以matplotlib类为可视化工具,讲述描述性统计里常用指标的计算方法和含义。 1 平均数、中位数和百分位数 平均数比较好理解,是样本的和除以样本的个数。 中位数也叫中值,假设样本个数是奇数,那么数据按顺序排列后处于居中位置的数则是中位数,如

数理统计与描述性统计
一、数理统计概念 注: 主要参考Datawhale课程资料,此处仅做大纲梳理,以便日后迅速回顾 1、基本概念 定义:在数理统计中,称研究对象的全体为总体,通常用一个随机变量表示总体。组成总体的每个基本单元叫个体。 样本的两重性:一经抽样便是一组确定数值;但在通常描述中样本也是一组随机变量,因为抽样本身就是随机的 2、常用统计量 1、样本均值:通常使用样本均值来估计总体分布的均值和对有关总

【Python 数据分析】描述性统计:平均数(均值)、方差、标准差、极大值、极小值、中位数、百分位数、用箱型图表示分位数
目录 简述 / 前言1. 平均数(均值)、方差、标准差、极大值、极小值2. 中位数3. 百分位数4. 用箱型图表示分位数 简述 / 前言 前面讲了数据分析中的第一步:数据预处理,下面就是数据分析的其中一个重头戏:描述性统计,具体内容为:平均数(均值)、方差、标准差、极大值、极小值、中位数、百分位数、用箱型图表示分位数。 1. 平均数(均值)、方差、标准差、极大值、极小值 关键

商务智能|描述性统计分析与数据可视化
一、商务智能的三大方面 三个主要方面是描述性的统计分析、预测性的分析和指导性的数据分析。 A. 商务智能的知识体系下,数据分析包含了哪三个工作?商务智能体系架构里边关于数据分析的术语是什么? 商务智能的知识体系下,数据分析包含了三个工作,即描述性分析,预测性分析,以及规范性分析。商务智能体系架构里边关于数据分析的术语是data nalyse或者business a man
技术学习|CDA level I 描述性统计分析(相关分析)
常用于分析变量之间的关系的方法——相关分析。变量之间关系的分析师数据分析非常核心的工作,变量之间关系的研究包括关系存在性研究、关系程度大小研究、关系方向的研究、关系形式的研究、关系传递的研究等。其中关系形式的研究最为复杂,统计中有大量的分析方法都是来探索变量之间关系形式的。研究变量关系形式的前提是变量间存在一定程度的相关关系。 一、相关分析的含义 变量之间的关系按照强弱来划分,常可以分为函数关
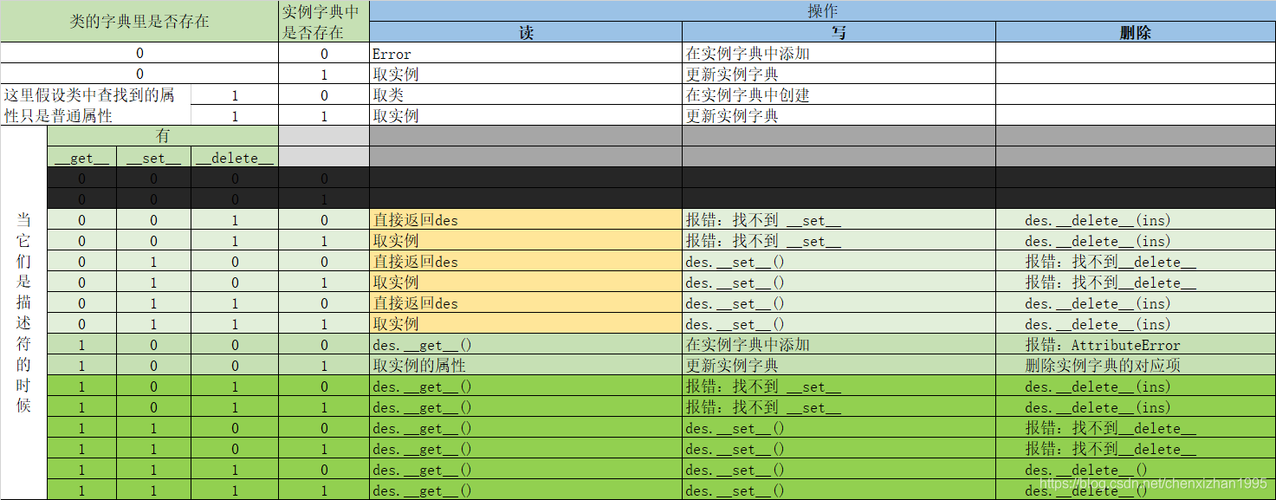
python进行描述性统计分析,python怎么做描述性统计
大家好,小编来为大家解答以下问题,python语言的描述错误的选项,python描述算法的方法有几种,今天让我们一起来看看吧! 一、描述符是什么 描述符:是一个类,只要内部定义了方法__get__, __set__, __delete__中的一个或者多个。描述符,属性,方法绑定等内部机制都是描述符在起作用python打印皮卡丘怎么弄。描述符以单个属性出现,并针对该属性的不同访问行
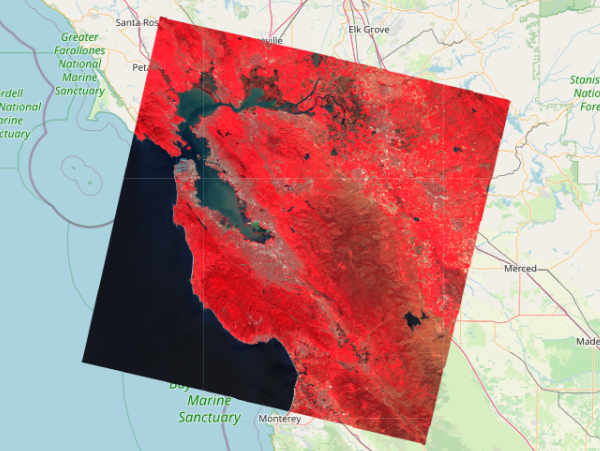
geemap学习笔记016:获取图像的基本属性和描述性信息
前言 遥感数据中通常包含众多信息,例如图像获取的时间、云覆盖量、以及每个波段的最大值最小值等等。 1 导入库并显示地图 import eeimport geemapMap = geemap.Map()Map 2 添加图像数据 centroid = ee.Geometry.Point([-122.4439, 37.7538]) #创建一个点坐标landsat = ee.ImageCo
numpy Head 与 Tail、属性与底层数据、加速操作、二进制操作、描述性统计、函数应用
基础用法 本节介绍 Pandas 数据结构的基础用法。下列代码创建上一节用过的示例数据对象: In [1]: index = pd.date_range('1/1/2000', periods=8)In [2]: s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])In [3]: df = pd.DataFrame

概率统计之——数理统计与描述性分析
一、数理统计概念 1.基本概念 定义:在数理统计中,称研究对象的全体为总体,通常用一个随机变量表示总体。组成总体的每个基本单元叫个体。从总体 X X X 中随机抽取一部分个体 X 1 , X 2 , . . . , X n X_1,X_2,...,X_n X1,X2,...,Xn ,称 X 1 , X 2 , . . . , X n X_1,X_2,...,X_n X1,X2,

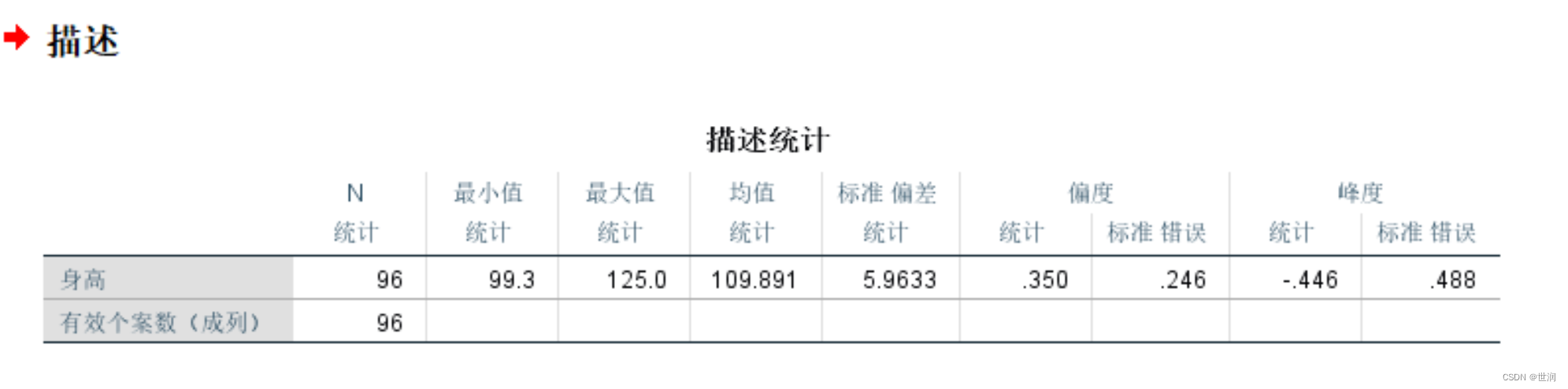
SPSS18常规描述性统计
1文件-打开-数据(进行数据导入) 2分析-描述统计-频率-(框框页面中)将成绩移入变量(可以取消勾选显示频率表格) 3选中所需数据(这里没有变异系数) (生成数据中英文问题,输出界面【编辑-选项-常规-更改语言】) 4复制数据到excel-增加变异系数(变异系数=标准差/均值)-更改一些所需数据(极大值极小值改为最大值最小值)-增加所有框线(将数据变为表格) 5将数据复制到
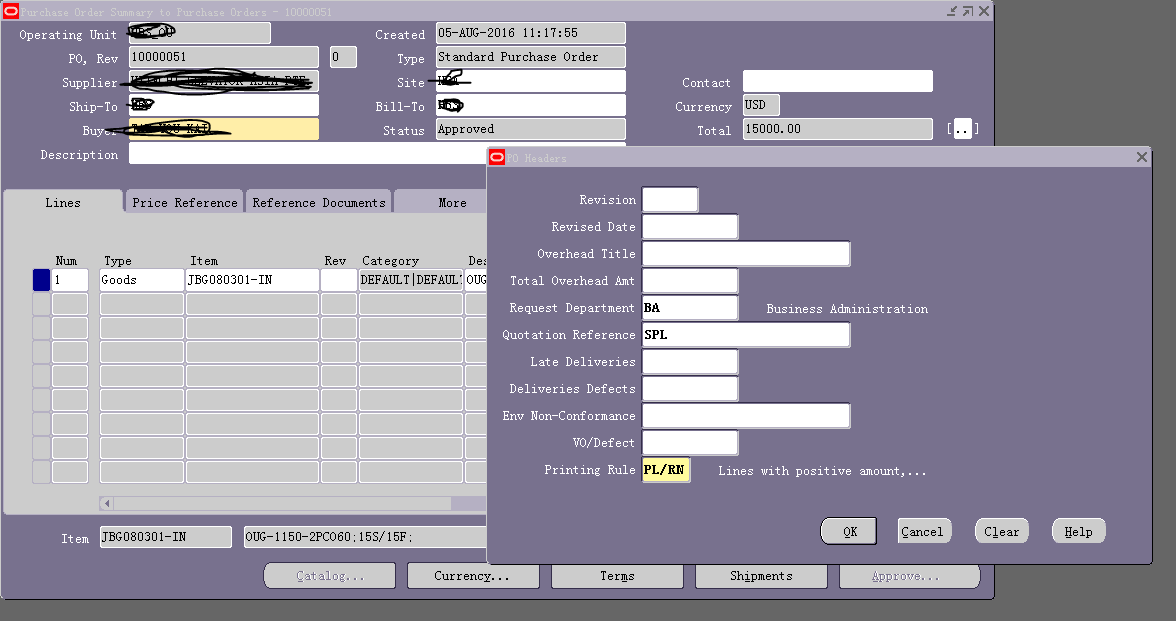
EBS中描述性弹性域的定义过程
以采购订单界面订单头部分弹性域为例 路径:Application Developer->Flexfield->Descriptive->Register 路径:Application Developer->Flexfield->Descriptive->Segment 根据title在 segment 界面查找出来,并定义段。 在更改段的时候,应该将Freeze Flexfield Def