拉勾专题
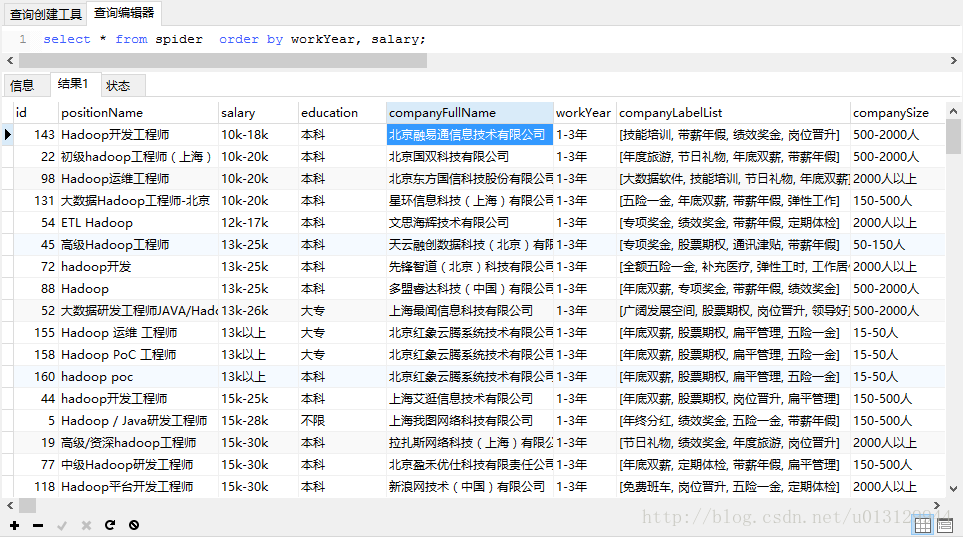
python爬取拉勾网数据保存到mysql数据库
环境:python3 相关包:requests , json , pymysql 思路:1.通过chrome F12找到拉钩请求接口,分析request的各项参数 2.模拟浏览器请求拉钩接口 3.默认返回的json不是标准格式 , 对返回的json数据进行处理转换为标准格式 4.利用pymysql模块进行db操作 #coding:utf-8import randomimpor
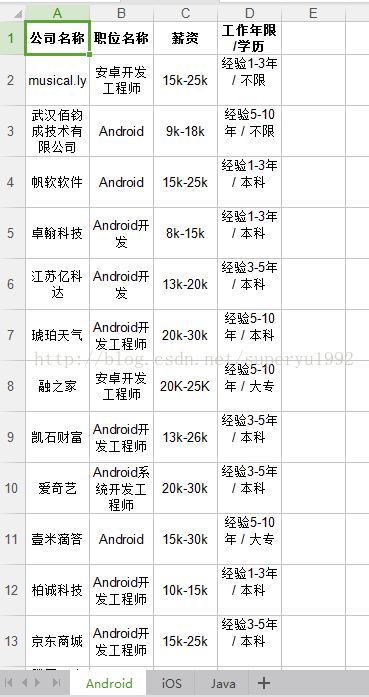
#python学习笔记#使用python爬取拉勾网职位信息(二):爬取数据
将python环境配置好后,接下来就可以开始动手coding了! 1.创建excel并插入头部数据: 这里的30是总页数,可以从网页中获得,这里为了简便,就暂时写了一个固定值。 2.获取网页数据 获取网页数据需要用到python自带的urllib(type为分类,如:Android,iOS等;index为页数),然后我们可以把获得的data,转成soup用于解析: 可

#python学习笔记#使用python爬取拉勾网职位信息(一):环境配置及库安装
鄙人作为一个Android开发者,经常想私下做一些小项目,需要一些后台的配合,自己的项目用servlet和sql语句也能凑合,但缺少后台数据就比较难办了(假数据看起来很违和,而且没有实际意义);听闻python可以做网络爬虫爬取数据,于是趁着这段时间开发任务不重,通过python实现了爬取网站数据的功能。 Python简介: 请自行百度... Python安装: 1.先去官网下载pyth

【爬虫专栏20】拉勾网爬虫(单线程和多线程)
拉勾网爬虫 爬取方法注意事项关键示例单线程示例多线程示例爬到的部分数据 爬取方法 emmmm这里就是从主页开始,找到页码的规律 这个规律还是挺好找的,就是页码变了而已 下面是拉钩主页页面 这个审查元素幅值xpath标签啥的我就不多说了吧 注意事项 1.#拉勾网有反爬,cookies变化 参考网址https://www.cnblogs.com/kuba8/p/108080
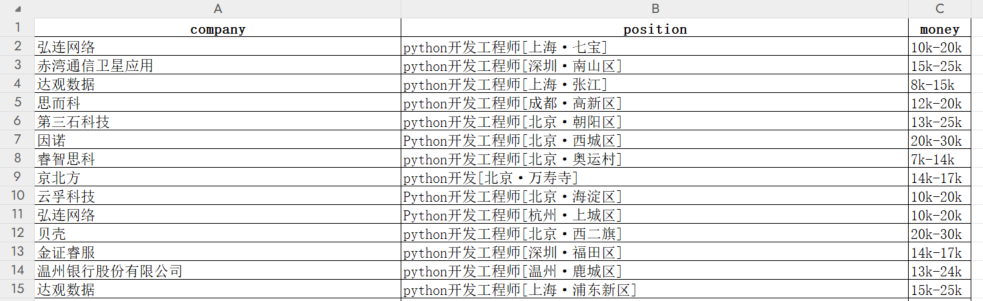
Python实战:使用DrissionPage库爬取拉勾网职位信息
DrissionPage库,号称可以把Selenium按在地上摩擦! 常规情况下,我们借助 requests 库爬取不加密的网站,使用 Selenium 库爬取加密的网站。 requests 效率高,但是解密难度大。Selenium 库可以实现网页自动化,不用解密,但是爬虫效率不高。 那有没有什么库既效率高,又可以网页自动化。 DrissionPage 库他来了,号称可以把 Sele
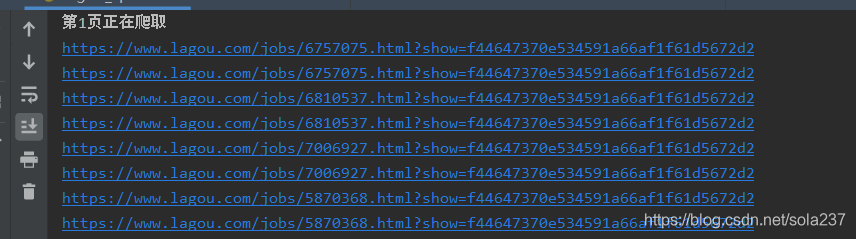
记录最新拉勾网职位和详情页的爬取
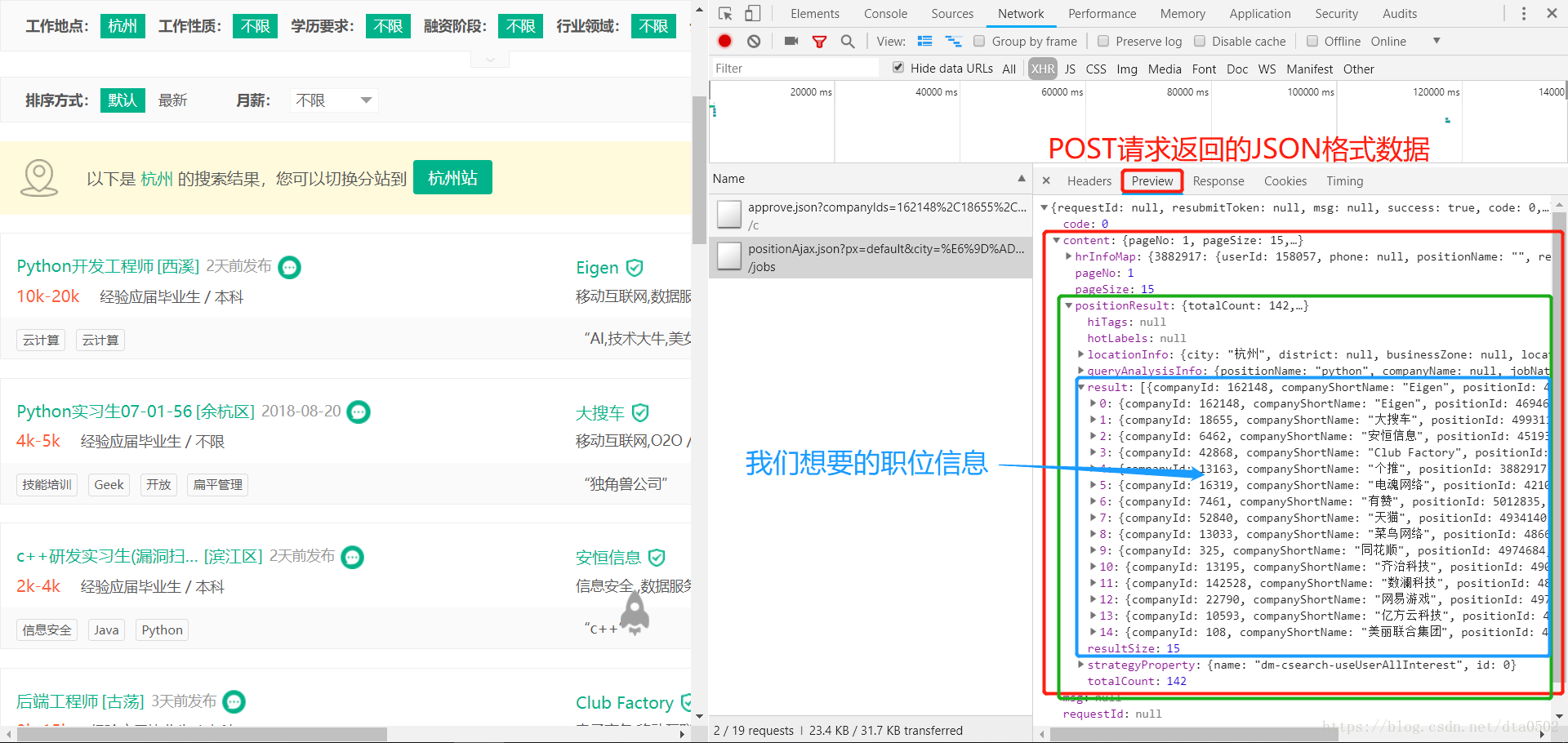
拉勾网职位和详情页爬取 拉勾网爬虫是异步加载方式,先访问初始页面得到cookie,再用cookie去爬取职位详情页面。 这里参考的是另外一篇文字的做法,开始自己走了很多弯路。原文链接暂时找不到了,后面看到会再贴上来。 爬取过程: 1、创建获取cookie的函数 2、main主程序 根据页面地址封装url,让其可以输入“城市”和“岗位”进行爬取。 3、解析页面 返回的是一个json格式,而且是

全栈系列Vue版拉勾
模拟拉勾app系列---vue前端界面 github地址,来猛戳吧 前言 本项目是本人在闲暇时间编写的一个初级引导项目,麻雀虽小五脏俱全,所使用的东西绝大多数在开发中都能用得到,但难免会存在很多地方需要完善。 由于近期要备战法考,且工作繁忙,没有时间维护,还存在很多BUG或需要优化的地方,希望多多提出(有空了就改),当然能给个star什么的就更好了。 为了方便访问,也加入了mock数据,

【附源码】Java计算机毕业设计拉勾教育课程管理系统(程序+LW+部署)
项目运行 环境配置: Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。 项目技术: java+ mybatis + Maven等等组成,B/S模式 + Maven管理等等。 环境需要 1.运行环境:最好是java
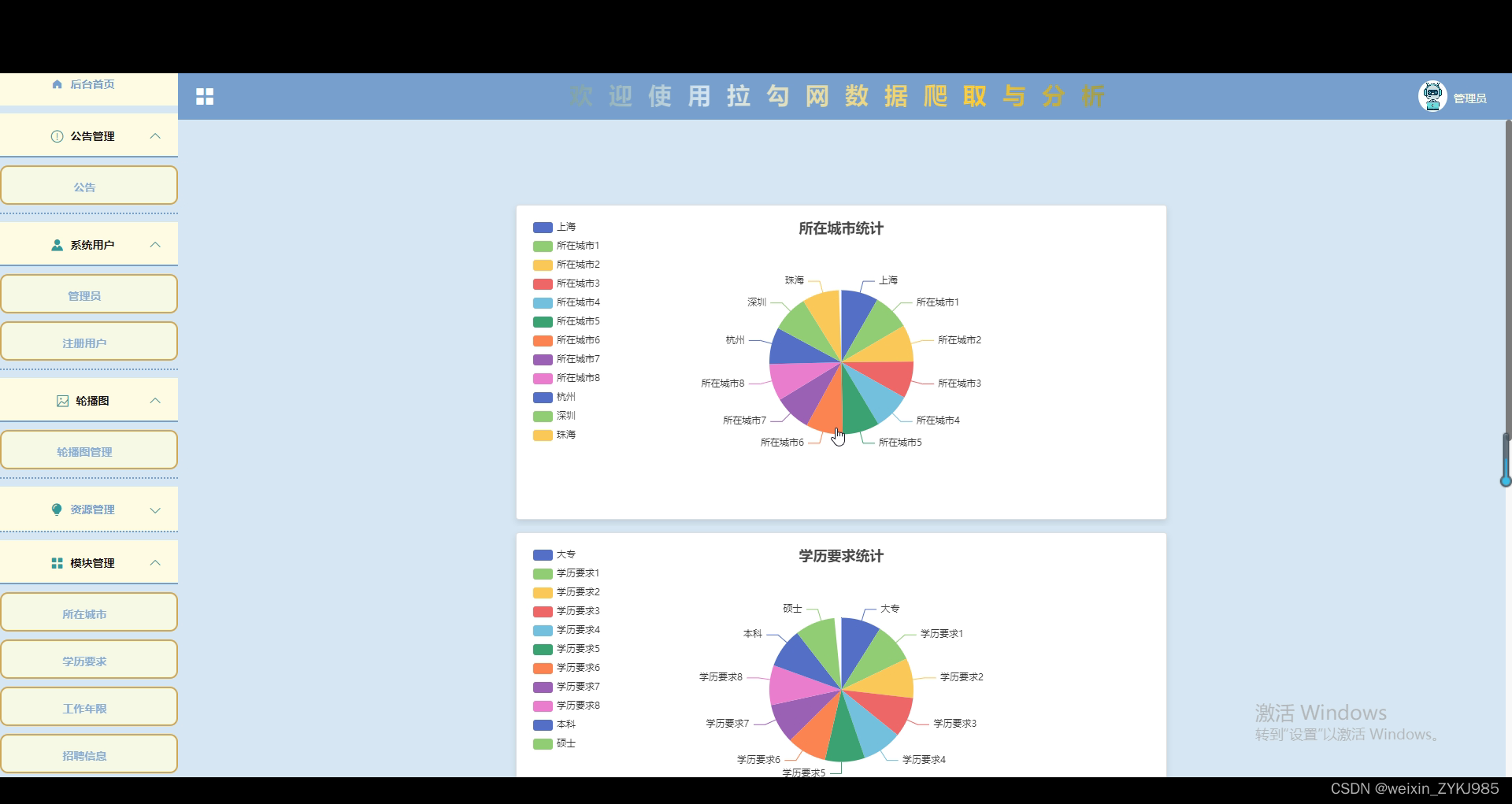
基于Python的拉勾网数据爬取与分析 计算机毕设源码97476
摘 要 该系统是一个将Python和数据分析相结合的实用应用系统。文章对系统应用设计的主要技术和相关框架进行了详细的说明,并给出了最终的结论分析。首先,使用Python来获取拉勾网中的招聘信息数据。其次,将收集到的数据存储在数据库中,并对结果数据进行再次清理和组织,最后进行可视化分析,以获得相应的统计图、招聘信息推荐等信息。设计该系统的目的是为了帮助求职者从复杂的招聘数据中直观地获取有价值的信

Python爬取拉勾网职位 - 分析学历与薪资关系及技能词云
Python拉勾网职位爬取及数据分析可视化 文章目录 Python拉勾网职位爬取及数据分析可视化1.工具准备(1)安装第三方库(2)安装及配置Chromedriver无头浏览器(3)谷歌浏览器xpath插件安装及配置(4)使用Pycharm 2.爬取准备(1)分析网站数据获取方式(2)选择爬取方式 3.数据爬取及提取保存(1)爬取器(2)解析器(3)下载器 4.数据分析及可视化(1)分析器
Python爬虫 senlenium爬取拉勾网招聘数据!
一、基本思路 目标url:https://www.lagou.com/ 用selenium爬虫实现,输入任意关键字,比如 python 数据分析,点击搜索,得到的有关岗位信息,爬取下来保存到Excel。 有30页,每个页面有15条招聘信息。 二、selenium爬虫 from selenium import webdriverimport timeimport logging

新手向:爬取分析拉勾网招聘信息
爱写bug(ID:icodebugs) 作者:爱写bug 前言: 看了很多网站,只发现获取拉勾网招聘信息是只用post方式就可以得到,应当是非常简单了。推荐刚接触数据分析和爬虫的朋友试一下。 在python3.7、acaconda3环境下运行通过 数据爬取篇: 1、伪造浏览器访问拉勾网 打开Chrome浏览器,进入拉勾网官网,右键->检查,调出开发者模式。 然后在拉勾网搜索关键词 算法工程师

Python(selenium)爬取拉勾网招聘信息并可视化分析-附代码
我的工作和数据分析相关,刚好最近也接触点爬虫,也想看看招聘网站的数据分析的要求是什么,就用爬虫爬下来分析分析 接触爬虫不多,什么代理池,cookie池还没有接触过,这个以后肯定要了解。 1、分析页面 先分析下拉钩的页面,是通过ajax方式动态显示的,提交的参数是页数,通过post方式进行提交,代码验证 最后返回来的是:{'success': False, 'msg': '

拉勾网访问显示操作太频繁解决思路,用session获取cookie添加到请求头(报文)里
拉勾网的职位界面使用ajax技术,在原网页代码无法获取搜索的职位信息。 1.抓包分析 , ! 通过反复观察,找到了信息职位的界面,根据这个数据包的信息制作头部信息 headers = {'User-Agent': random_user, #随机用户"Referer":"https://www.lagou.com/jobs/list_python/",# 从哪个访问过来"X-An
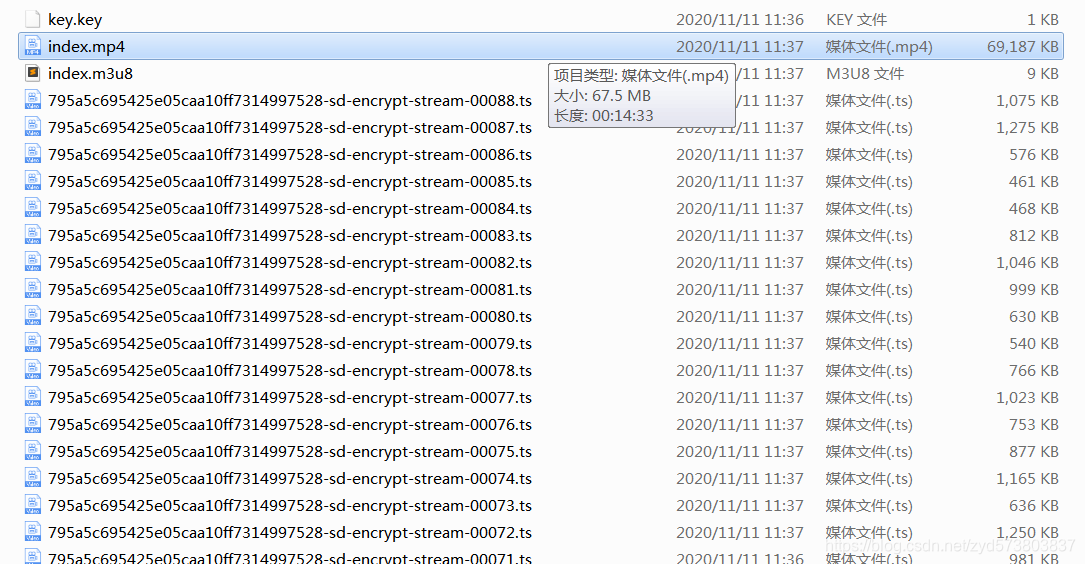
java下载m3u8视频(拉勾视频为例)
文章目录 java下载m3u8视频1.创建工具类2.下载m3u8文件3.下载key4.关于ts文件5.合成视频6.运行 二、关于ffmpeg1.简单用法2.创建工具类 java下载m3u8视频 m3u8视频主要 由 m3u8文件、key、ts文件 三部分组成 本篇以拉勾视频为例 1.创建工具类 @Slf4jpublic class M3U8Factory {priv