本文主要是介绍记录最新拉勾网职位和详情页的爬取,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
拉勾网职位和详情页爬取
拉勾网爬虫是异步加载方式,先访问初始页面得到cookie,再用cookie去爬取职位详情页面。
这里参考的是另外一篇文字的做法,开始自己走了很多弯路。原文链接暂时找不到了,后面看到会再贴上来。
爬取过程:
1、创建获取cookie的函数
2、main主程序
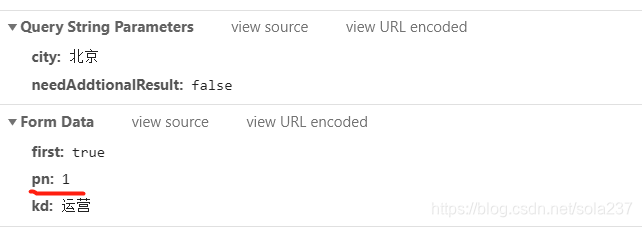
根据页面地址封装url,让其可以输入“城市”和“岗位”进行爬取。
3、解析页面
返回的是一个json格式,而且是post方法,但是在post的时候,页面的翻页地址实际上也会发生变化,只是并不会显示出来,所以我们通过改变这个pn实现翻页。
4、解析详情页的地址
详情页地址解析这里也有个坑,就是也需要带上第一步的cookies,否则只能爬取5条详情页,后面的地址就会不一样,导致无法爬取。
另外,详情页的地址里面还带有一个sid,是在解析职位列表的时候附带的一个showid,至于是否一定要这个,还不是很清楚,但是我爬取详情页的时候把它也附带上了,所以详情页的地址如下。
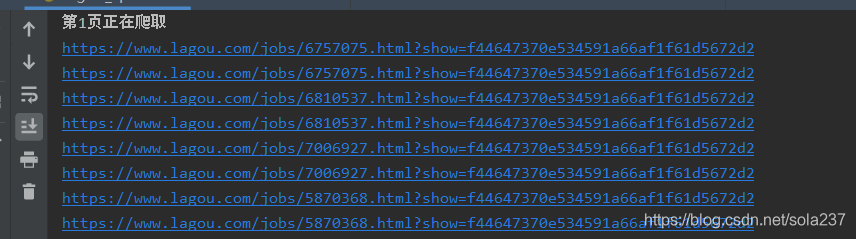
一个是构造的url,另一个是response.url,通过对比两个url的地址不同才发现这个cookies的问题。
5、保存到csv
这一步就没什么好说的了,通过追加的方式逐条保存到csv文件中。这样有个问题就是每一次都有一个标题行,在csv文件中需要手动删除才行。
当然也可以先保存到字典列表,然后一次性,然后用pandas.to_excel的方法一次性写入到excel中,就不会出现上面的问题。
完整代码如下:
#coding:utf-8import requests
import csv,time
from lxml import etreedef GetCookie():url = 'https://www.lagou.com/jobs/list_%E8%BF%90%E8%90%A5/p-city_213?&cl=false&fromSearch=true&labelWords=&suginput='# 注意如果url中有中文,需要把中文字符编码后才可以正常运行headers = {'User-Agent': 'ozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400'}response = requests.get(url=url,headers=headers,allow_redirects=False)# cookies = requests.utils.dict_from_cookiejar(response.cookies)return response.cookiesdef GetData(page,kd,url):headers = {'Host': 'www.lagou.com','Origin': 'https://www.lagou.com','Referer': 'https://www.lagou.com/jobs/list_%E8%BF%90%E8%90%A5?labelWords=&fromSearch=true&suginput=','User-Agent这篇关于记录最新拉勾网职位和详情页的爬取的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




