本文主要是介绍Python(selenium)爬取拉勾网招聘信息并可视化分析-附代码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我的工作和数据分析相关,刚好最近也接触点爬虫,也想看看招聘网站的数据分析的要求是什么,就用爬虫爬下来分析分析
接触爬虫不多,什么代理池,cookie池还没有接触过,这个以后肯定要了解。
1、分析页面
先分析下拉钩的页面,是通过ajax方式动态显示的,提交的参数是页数,通过post方式进行提交,代码验证

最后返回来的是:{'success': False, 'msg': '您操作太频繁,请稍后再访问', 'clientIp': '113.14.1.254'},但这个状态的statues_code是200(成功返回了请求),代码中的headers是基本上把浏览器下面的request的headers原封不动的复制过来,还是这种情况,之后我换了一个新的账号(新的cookies),不同的网络情况下(不同ip),基本上排除了ip被封的情况,我现在还没有找到原因,猜测是因为是动态cookies的缘故。
2、我只是为了获取数据,没有没有必要在这个地方硬嗑,我选择了selenium进行硬怼,主要爬取 全国+13个主要城市,
因为要爬取的是详情页(静态页面):

所以需要先找到每个页面对应的ID,这个ID在主页面的这个位置,通过selenium点击下一页,分别将每一页的ID找出来储存起来。
通过selenium爬取这个需要注意三点:
(1)、第一个坑:它是通过找到“下一页”按钮进行点击来翻页的,但是你打开页面并不能找到“下一页”这个element,因为它是ajax渲染的页面,你必须下拉到最下面刷新出完整页面才能找到“下一页”并点击。
(2)、第二个坑:切换城市是通过循环点击主要城市element刷新出每一个城市的页面的,但是在点击第二个城市的element来刷新页面时会出现 StaleElemeReferenceException错误,出现这个错误的原因是点击的element在新的页面找不到,因为element是刷新第一个城市时候出现的,所以需要切换到下一个城市的时候得刷新下页面。
(3)、第三个坑:有的城市的职位比较少,只有一页,所以你寻找“下一页”element并点击的时候是找不到的,所以遇到这种情况做好错误的处理工作。
代码如下:
class reptile_lagou():def __init__(self):# self.city_page = {'全国':30,'北京':30,'上海':30,'深圳':21,'广州':16,'杭州':12,'成都':4}# self.list_ = [] #用来储存self.headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8','Accept-Encoding': 'gzip,deflate,br','Accept-Language': 'zh-CN,zh;q=0.9','Cache-Control':'max-age=0','Connection': 'keep-alive','Host':'www.lagou.com','Upgrade-Insecure-Requests':'1','User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'}self.list_id = [] #用来储存详情页ID的列表self.next_page_element = [1] #用来储存下一页的elementself.city_element = '' #用来储存主要城市的element,用于循环遍历self.error = [] #爬虫中出现的错误储存在这里self.code = [] #爬虫中出错的网页code放在这里def loginSys(self,username='爱丽丝的梦幻王国', password='匹诺曹的性感嘴唇'):self.driver = webdriver.Chrome()'''登陆利用webdriver驱动打开浏览器,操作页面此处使用goole浏览器'''print('开始登陆')target = 'https://passport.lagou.com/login/login.html?service=https%3a%2f%2fwww.lagou.com%2f'self.driver.get(target)self.driver.implicitly_wait(0.1) #隐式等待0.1sLoginTitle = self.driver.titleresult = self.driver.titleif LoginTitle == result:self.driver.find_element_by_xpath("//*[@placeholder='请输入常用手机号/邮箱']").send_keys(username)time.sleep(0.6) # 停顿模拟真实操作情况,降低被网站发现的几率self.driver.find_element_by_xpath("//*[@placeholder='请输入密码']").send_keys(password)time.sleep(0.6) # 停顿模拟真实操作情况,降低被网站发现的几率self.driver.find_element_by_xpath("//*[@data-lg-tj-id='1j90']").click() # 点击登录self.find_company_id()def find_company_id(self):'''找到每个详情页的id'''time.sleep(12) # 此处停留20s,因为拉勾网有一个图像验证码,给20s来识别z = '北京' #刚开始赋值一个北京input = self.driver.find_element_by_id('search_input') #找到输入框input.send_keys('算法工程师') #输入数据分析input.send_keys(Keys.ENTER)time.sleep(5)list_ = ['北京']+[j for j in range(13)]for i in list_:self.driver.refresh() #得重新刷新页面,才能找到hot-city-nameif i != '北京':self.driver.implicitly_wait(3) # 隐式等待3sself.city_element = self.driver.find_elements(By.CLASS_NAME,'hot-city-name')j = self.city_element[i]z = j.textj.click()self.next_page_element = list(str(i))self.driver.implicitly_wait(1)while self.next_page_element: #在一个城市的页数内,不断的循环将页面中公司的ID保存下来try:print(z)idlist = self.driver.find_elements_by_xpath("//li[@data-positionid]")idlist = [i.get_attribute('data-positionid') for i in idlist]self.list_id += idlisttime.sleep(6)#one #通过滑动到最下面才能点击按钮,原因未知js = "window.scrollTo(0,document.body.scrollheight)" #一下滑到页面的底部self.driver.execute_script(js)next_page = self.driver.find_element_by_class_name("pager_next")print(next_page)print(next_page.tag_name)self.next_page_element.append(next_page)if self.next_page_element[-2] == self.next_page_element[-1]: #如果下一页的element相同,则跳出循环self.next_page_element = []next_page.click()self.driver.implicitly_wait(10) # 隐式等待4sexcept StaleElementReferenceException: #不再位于同一页面上,或者自元素找到后页面可能已刷新print('不在位于同一个页面,将重新刷新')self.driver.refresh() #一旦出现错误重新刷新页面time.sleep(2)except NoSuchElementException:#无法找到元素时抛出,此种情况是针对那些只有一个页面的城市print('此城市只有一页职位...')breakfinally:print(self.list_id)print(len(self.list_id))else:self.list_ = [] #去掉那些因为多取最后一页的重复IDfor i in self.list_id:if i not in self.list_:self.list_.append(i)pd.DataFrame({'conmpany_id':self.list_}).to_excel(r'C:\Users\lenovo\Desktop\company_id2.xlsx')self.id_content()def id_content(self):self.industry_size_state,self.un_time,self.address,self.jb_,self.company,self.income,self.city,self.experience,self.Education,self.time,self.label = [],[],[],[],[],[],[],[],[],[],[]print('开始爬取...')for q in self.list_:time.sleep(random.randint(16,20)) ##爬取每页的时候停止16-20s,防止被封print('第%d页'%(self.list_.index(q)+1))url = r'https://www.lagou.com/jobs/%s.html'%qr = requests.get(url, headers=self.headers,verify=False)soup = BeautifulSoup(r.content, 'lxml')try:self.company.append(soup.find_all('div',class_ = 'company')[0].get_text()[:-2])except:self.error.append({(self.list_.index(q)+1):1})self.code.append({(self.list_.index(q)+1):r.status_code})self.company.append(None)try:job_request = [i for i in soup.find_all('dd',class_ = 'job_request')[0].get_text().split('\n') if i]except Exception as e:self.error.append({(self.list_.index(q)+1):2})self.code.append({(self.list_.index(q)+1):r.status_code})self.income.append(None)self.city.append(None)self.experience.append(None)self.Education.append(None)self.time.append(None)self.label.append(None)else:self.income.append(job_request[0])self.city.append(job_request[1])self.experience.append(job_request[2])self.Education.append(job_request[3])self.time.append(job_request[-1][:-8])self.label.append(','.join(job_request[4:-1]))try:self.jb_.append([i for i in soup.find_all('div', class_='job-detail')[0].text.split('\n') if i])except:self.error.append({(self.list_.index(q) + 1): 3})self.code.append({(self.list_.index(q)+1):r.status_code})self.jb_.append(None)try:self.address.append(''.join([i.strip() for i in soup.find_all('div',class_ = 'work_addr')[0].text.split('\n') if i][:-1]))except:self.error.append({(self.list_.index(q) + 1): 4})self.address.append(None)try:self.un_time.append(soup.find_all('span',class_ = 'tip')[2].text.strip())except:self.error.append({(self.list_.index(q) + 1): 5})self.code.append({(self.list_.index(q)+1):r.status_code})self.un_time.append(None)try:self.industry_size_state.append([i.strip() for i in soup.find_all('ul',class_ = 'c_feature')[0].text.split('\n') if i] if len([i.strip() for i in soup.find_all('ul',class_ = 'c_feature')[0].text.split('\n') if i]) == 8 else [i.strip() for i in soup.find_all('ul',class_ = 'c_feature')[0].text.split('\n') if i][:4]+[i.strip() for i in soup.find_all('ul',class_ = 'c_feature')[0].text.split('\n') if i][6:])except:self.error.append({(self.list_.index(q) + 1): 6})self.code.append({(self.list_.index(q)+1):r.status_code})self.industry_size_state.append(None)print(self.error)print(self.code)else:print('爬取完毕')print(self.error)print(self.code)pd.DataFrame({'公司':self.company,'薪资':self.income,'城市':self.city,'经验':self.experience,'学历':self.Education,'发布时间':self.time,'职业标签':self.label,'工作描述':self.jb_,'工作地址':self.address,'hr活跃时间':self.un_time,'行业_发展_大小':self.industry_size_state}).to_excel(r'C:\Users\lenovo\Desktop\lagou_job_details_数据分析师.xlsx')test = reptile_lagou()
test.loginSys()
数据如下:

3、对爬取得数据进行分析
(1)、北京数据分析工作位置的分布(因为我在北京啊)
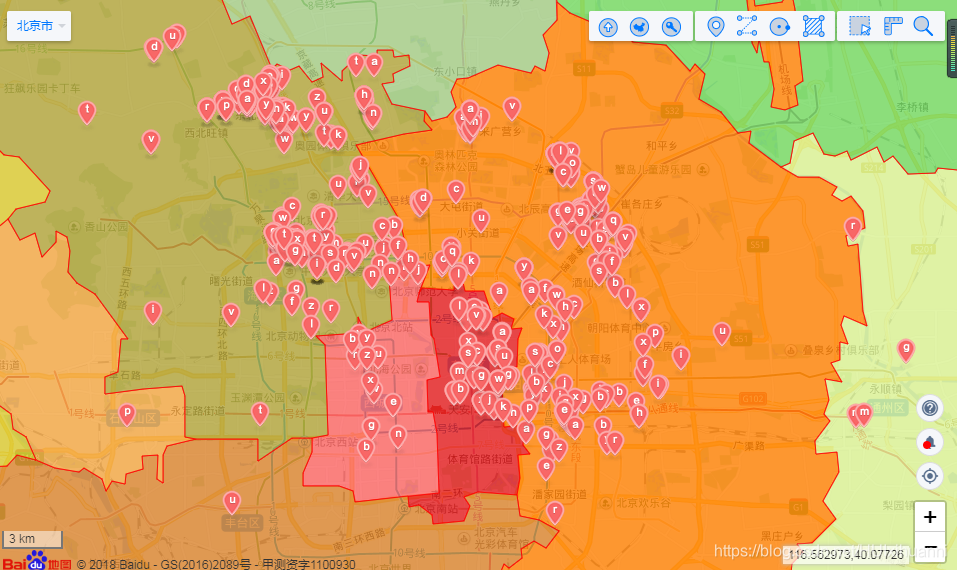
图 1
把北京的七百多个岗位显示在地图上可以看出,这个岗位集中分布在 海淀区、朝阳区和东西城区且基本在三环之内,预计着通勤时间长,租房成本高的问题,京城居,大不易啊。
此处的代码如下(获取工作地点地理位置的经纬度代码)
data = pd.read_excel(r'C:\Users\lenovo\Desktop\lagou_job_details_数据分析_数据挖掘.xlsx')
data.dropna(subset=['公司'],inplace=True)
data = data.loc[data['工作地址'].notnull(),:]
data['工作地址'] = data['工作地址'].map(lambda x:''.join([i.strip() for i in x.split('-')])).map(lambda x:x if x[:2] == '北京' else None)
data1 = pd.DataFrame()
data1['工作地址'] = data.loc[data['工作地址'].notnull(),'工作地址']
data1['经度'] = np.nan
data1['维度'] = np.nandef getlnglat(address):url = 'http://api.map.baidu.com/geocoder/v2/'output = 'json'ak = '爱丽丝的梦想乐园' # 百度地图ak,具体申请自行百度,提醒需要在“控制台”-“设置”-“启动服务”-“正逆地理编码”,启动address = quote(address) # 由于本文地址变量为中文,为防止乱码,先用quote进行编码try:uri = url + '?' + 'address=' + address + '&output=' + output + '&ak=' + akreq = urlopen(uri)except:time.sleep(3)return None,Noneres = req.read().decode()temp = json.loads(res)lat = temp['result']['location']['lat']lng = temp['result']['location']['lng']return lat,lng # 纬度 latitude,经度 longitude
#
for indexs in data1.index:get_location = getlnglat(data.loc[indexs,'工作地址'])print(get_location)get_lat = get_location[0]get_lng = get_location[1]data1.loc[indexs,'纬度'] = get_latdata1.loc[indexs,'经度'] = get_lngdata1[data1['经度'].notnull()].to_excel(r'C:\Users\lenovo\Desktop\北京地区工作地点经纬度.xlsx')
把地点的经纬度获取之后用这个软件实现标记: 地图无忧
(2)、各城市工作职位数量和薪资分布

图 2
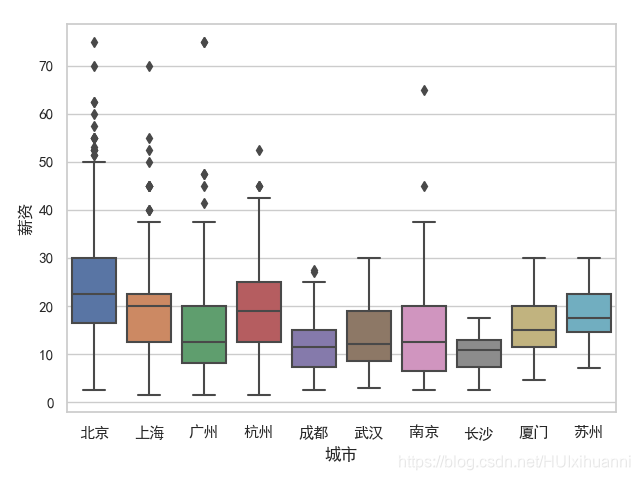
图 3
从各城市的职位数量可知,北上广深杭的职位是远远多于其余的城市的~
薪资是对薪资范围的求平均值,发现北京的的数据分析薪资25%分位数,50%分位数,75%分位数都是高于其他城市的,惭愧啊,我拉了大北京数据分析同仁的后腿了,仍需努力啊!
此处代码如下:
data = pd.read_excel(r'C:\Users\lenovo\Desktop\拉钩网数据分析\lagou_job_details_数据分析_数据挖掘.xlsx')
data.dropna(subset=['公司'],inplace=True)
#各个城市的职位分布
data1 = pd.DataFrame(data['城市'].value_counts()).reset_index().rename(columns ={'index':'城市','城市':'数量'})
data1 = data1[data1['数量'] > 14]
data1['城市'] = data1['城市'].str[1:3]
ax = sns.barplot(x="城市", y="数量", data=data1)
plt.show()data['城市'] = data['城市'].str[1:3]
data['薪资'] = data['薪资'].str.split('-').map(lambda x:np.median((int(re.findall('\d+',x[0])[0]),int(re.findall('\d+',x[1])[0])))) #取得每个薪资范围的平均值
data = data.loc[data['城市'].notnull(),]
g = sns.boxplot(x="城市", y="薪资",order=['北京','上海','广州','杭州','成都','武汉','南京','长沙','厦门','苏州'],data=data)
plt.show()(3)、各个行业的职位数量分布

图 4
数据分析岗位还是主要分布在分布在 互联网、数据行业和金融行业,传统行业对数据分析还是需求较少~符合我们的认知。
此处代码如下:
data = pd.read_excel(r'C:\Users\lenovo\Desktop\拉钩网数据分析\lagou_job_details_数据分析_数据挖掘.xlsx')
data.dropna(subset=['公司'],inplace=True)
data['行业'] = data['行业_发展_大小'].map(lambda x:[i.replace("'",'') for i in x[1:-1].split("', '")][0])
data['行业'] = data['行业'].map(lambda x: '移动互联网' if '移动互联网' in x else '金融' if '金融' in x else '020' if '020' in x else '数据行业' if '数据' in x else '电子商务' if '商务' in x else '服务' if '服务' in x else x)
data1 = pd.DataFrame(data['行业'].value_counts()).reset_index().rename(columns ={'index':'行业','行业':'数量'})
data1 = data1[data1['数量'] > 20]
ax = sns.barplot(x="行业", y="数量", data=data1)
plt.show()(4)、岗位薪资和学习以及工作经验的关系

图 5
从图上可以看出, 薪资受工作经验较大,在工作1-3年之后薪资有个大幅度的上升,其次数据分析学历也主要倾向于本科及硕士。
上图代码如下:
data['薪资'] = data['薪资'].str.split('-').map(lambda x:np.median((int(re.findall('\d+',x[0])[0]),int(re.findall('\d+',x[1])[0]))))
data['学历'] = data['学历'].str.split('/').map(lambda x:x[0]).str.strip()
data['经验'] = data['经验'].str.split('/').map(lambda x:x[0]).str.strip()
data = data.loc[data['薪资'] <40,]
ax = sns.boxplot(x="学历", y="薪资",hue = '经验', data=data,palette="Set3",order=['学历不限','大专及以上','本科及以上','硕士及以上','博士及以上'],hue_order=['经验不限','经验应届毕业生','经验1年以下','经验1-3年','经验3-5年','经验5-10年','经验10年以上'])
plt.show()(5)、公司大小和薪资的关系

在拉钩上,2000人以上的和500-2000人以上的公司占了50%,招数据分析的还是大公司居多,从薪资和公司的规模的图可以看出,2000人以上的薪资各个分位数的薪资都是 高于中小型公司的,所以选择大公司没有错~
上图代码如下:
data = pd.read_excel(r'C:\Users\lenovo\Desktop\拉钩网数据分析\lagou_job_details_数据分析_数据挖掘.xlsx')
data.dropna(subset=['公司'],inplace=True)
data['薪资'] = data['薪资'].str.split('-').map(lambda x:np.median((int(re.findall('\d+',x[0])[0]),int(re.findall('\d+',x[1])[0]))))
data['规模'] = data['行业_发展_大小'].map(lambda x:[i.strip() for i in x[1:-1].split(",") if '人' in i][-1][1:-1] if len([i.strip() for i in x[1:-1].split(",") if '人' in i])>0 else np.nan)
del data['行业_发展_大小']
data = data.loc[(data['规模'].notnull()) & (data['薪资']<60), ]ax = sns.boxplot(x="规模", y="薪资",data = data,palette="Set3",order = ['2000人以上','500-2000人','150-500人', '50-150人', '15-50人','少于15人'])
plt.show()(6)待续~
这篇关于Python(selenium)爬取拉勾网招聘信息并可视化分析-附代码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



