本文主要是介绍Python实战:使用DrissionPage库爬取拉勾网职位信息,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
DrissionPage库,号称可以把Selenium按在地上摩擦!
常规情况下,我们借助 requests 库爬取不加密的网站,使用 Selenium 库爬取加密的网站。
requests 效率高,但是解密难度大。Selenium 库可以实现网页自动化,不用解密,但是爬虫效率不高。
那有没有什么库既效率高,又可以网页自动化。
DrissionPage 库他来了,号称可以把 Selenium 按在地上摩擦!
DrissionPage 库结合了 requests 和 selenium 的特长,既实现了和 Selenium 库类似的网页自动化效果,又提升了爬虫效率。同时实现代码“写得快”和“跑得快”。
DrissionPage 库在码云上有 3.4k 个 Star,很牛了。

今天我们就使用 DrissionPage 库实战,爬取拉勾网职位信息。
一、简介
DrissionPage 是一个基于 python 的网页自动化工具。它既能控制浏览器,也能收发数据包,还能把两者合而为一。可兼顾浏览器自动化的便利性和 requests 的高效率。它功能强大,内置无数人性化设计和便捷功能。它的语法简洁而优雅,代码量少,对新手友好。
用 requests 做数据采集面对要登录的网站时,要分析数据包、JS 源码,构造复杂的请求,往往还要应付验证码、JS 混淆、签名参数等反爬手段,门槛较高,开发效率不高。使用浏览器,可以很大程度上绕过这些坑,但浏览器运行效率不高。
因此,这个库设计初衷,是将它们合而为一,同时实现“写得快”和“跑得快”。能够在不同需要时切换相应模式,并提供一种人性化的使用方法,提高开发和运行效率。除了合并两者,本库还以网页为单位封装了常用功能,提供非常简便的操作和语句,使用户可减少考虑细节,专注功能实现。以简单的方式实现强大的功能,使代码更优雅。
以前的版本是对 selenium 进行重新封装实现的。从 3.0 开始,作者另起炉灶,对底层进行了重新开发,摆脱对 selenium 的依赖,增强了功能,提升了运行效率。
二、入门案例
1、启动浏览器
默认状态下,程序会自动在系统内查找 Chrome 路径。
执行以下代码,浏览器启动并且访问百度网页。
from DrissionPage import ChromiumPagepage = ChromiumPage()
page.get('https://www.baidu.com/')
浏览器顺利打开了百度的网页。

2、爬取码云网站项目
网址:https://gitee.com/explore/all
这个示例的目标,要获取所有库的名称和链接,为避免对网站造成压力,只采集 3 页。
打开网址,按F12,我们可以看到页面 html 如下:

爬虫代码如下:
from DrissionPage import SessionPage# 创建页面对象
page = SessionPage()# 爬取3页
for i in range(1, 4):# 访问某一页的网页page.get(f'https://gitee.com/explore/all?page={i}')# 获取所有开源库<a>元素列表links = page.eles('.title project-namespace-path')# 遍历所有<a>元素for link in links:# 打印链接信息print(link.text, link.link)
Pycharm 控制台输出如下,项目名称和链接都爬取到了:
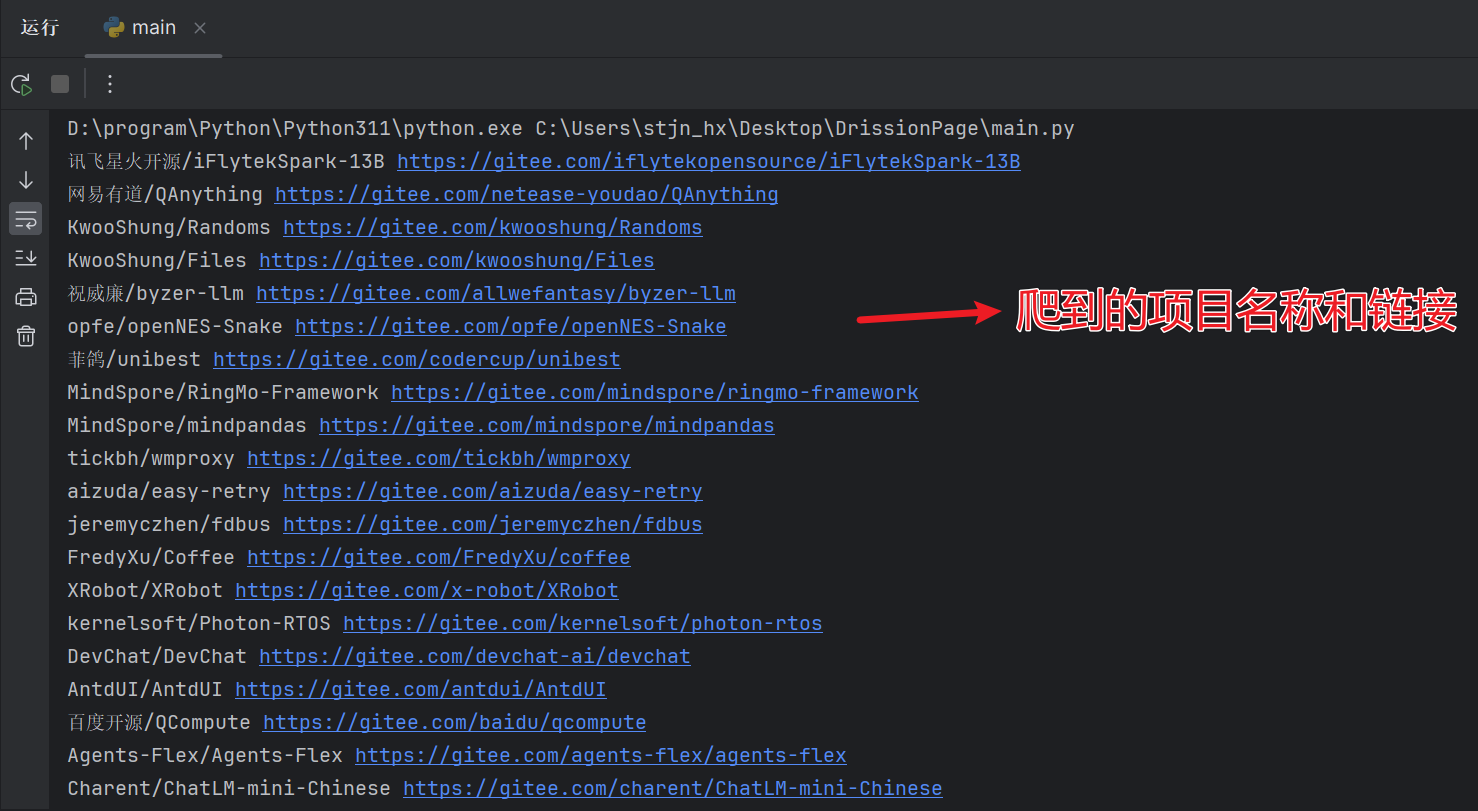
三、定位元素
爬网页简单来说就是提取一些页面元素,定位到元素,就可以进行输出、保存等操作。
一些常用的元素定位方式如下,基本逻辑和 Selenium 方式类似,但是更简洁。
# 根据 class 或 id 查找
page.ele('#ele_id') # 等价于 page.ele('@id=ele_id')
page.ele('#:ele_id') # 等价于 page.ele('@id:ele_id')
page.ele('.ele_class') # 等价于 page.ele('@class=ele_class')
page.ele('.:ele_class') # 等价于 page.ele('@class:ele_class')# 根据 tag name 查找
page.ele('tag:li') # 查找第一个 li 元素
page.eles('tag:li') # 查找所有 li 元素 # 根据 tag name 及属性查找
page.ele('tag:div@class=div_class') # 查找 class 为 div_class 的 div 元素
四、实战案例:爬拉勾网
在拉勾网爬取 Python 职位的招聘信息,获取公司、职位、薪资等信息。
目标网址https://www.lagou.com/wn/zhaopin?kd=Python&pn=2
分析网址 url,只有pn参数是变化的,通过改变pn参数的值就可以实现翻页效果。

根据定位元素的方法,分析网页元素信息,可以定位到职位 div、company、company、money 这些信息。定位方法如下:
divs = page.eles('tag:div@class=item__10RTO')
company = div.ele('.company-name__2-SjF')
company = div.ele('#openWinPostion')
money = div.ele('.money__3Lkgq')
定位到元素,就可以写爬虫代码了,还是比较简单的。在我公众号多看几篇 Python 实战,应该可以毫无压力写出代码,下面直接给出完整爬虫代码。代码如下:
from DrissionPage import SessionPage
import pandas as pd# contents列表用来存放所有爬取到的职位信息
contents = []# 创建页面对象
page = SessionPage()# 爬取30页
for i in range(1, 31):# 访问某一页的网页page.get(f'https://www.lagou.com/wn/zhaopin?kd=Python&pn={i}')# 查找 class 为 item__10RTO 的 div 元素divs = page.eles('tag:div@class=item__10RTO')# 提取公司、职位、薪资for div in divs:company = div.ele('.company-name__2-SjF')position = div.ele('#openWinPostion')money = div.ele('.money__3Lkgq')contents.append([company.text, position.text, money.text])print("正在爬取第", i, "页,总计获取到", len(contents), "条职位信息")# 保存到csv文件
name = ['company', 'position', 'money']
contents_df = pd.DataFrame(columns=name, data=contents)
contents_df.to_csv("拉勾网Python职位信息.csv", index=False)
Pycharm 控制台输出如下,爬取了 30 个网页,总计获取到 450 条职位信息:

打开 csv 文件查看数据,截图如下:
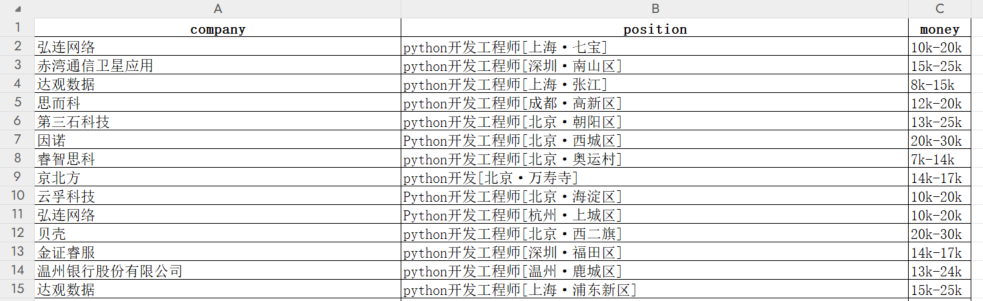
五、项目链接
项目主页:https://g1879.gitee.io/drissionpagedocs/
文档地址https://g1879.gitee.io/drissionpagedocs/
六、总结
通过这个实战案例,不得不说 DrissionPage 这个库真的牛逼。不用安装浏览器驱动了,元素定位也更简洁,爬虫效率也很高。
当然,本文只是一个入门,更多使用技巧可以到作者的项目主页食用,项目文档写的也很清晰易懂。
本文首发在“程序员coding”公众号,欢迎关注与我一起交流学习。
这篇关于Python实战:使用DrissionPage库爬取拉勾网职位信息的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






