扩增专题

tensorflow:超简单易懂 tensor list的使用 张量数组的使用 扩增 建立 append
构造张量数组: 最简单的方式: tensor_list=[tensor1,tensor2] 常用的方式(这个方式可以用于for循环) tensor_list=[]tensor_list.append(tensor1)tensor_list.append(tensor2) 张量数组的使用 批量处理张量数组里面的张量,之后将其存储到一个新的张量数组中 new_tensor_list

java中Array和ArrayList区别 可以将 ArrayList想象成一种会自动扩增容量的Array
java中Array和ArrayList区别 1)精辟阐述: 可以将 ArrayList想象成一种“会自动扩增容量的Array https://blog.csdn.net/ywjy10280915/article/details/82721062?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMach
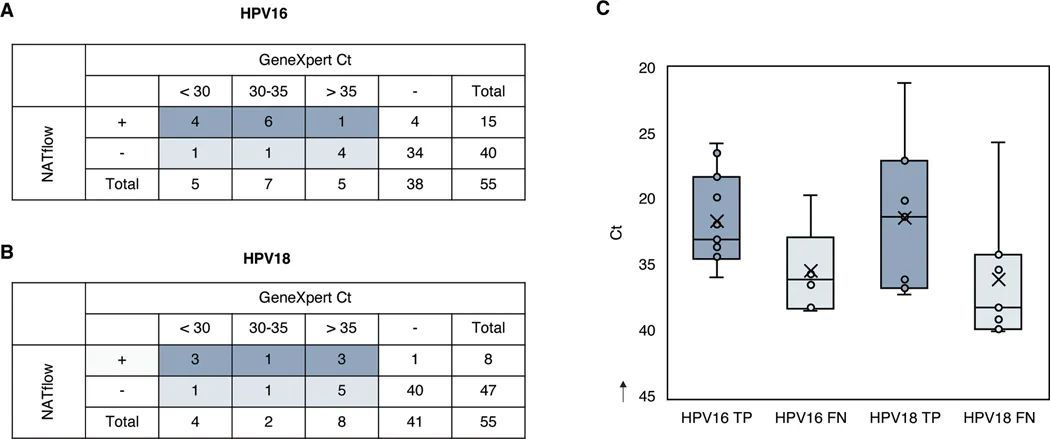
资源有限进行一种集成的等温核酸扩增检测HPV16和HPV18的DNA
今天给同学们分享一篇实验文章“An integrated isothermal nucleic acid amplification test to detect HPV16 and HPV18 DNA in resource-limited settings”,这篇文章发表在Sci Transl Med期刊上,影响因子为17.1。 结果解读: HPV16和HPV18 RPA检测可
numpy函数介绍1: repeat 数据扩增
1、对单数据类型重复: np.repeat(3,2)#array([3, 3])np.repeat('abd',2)#array(['abd', 'abd'], dtype='<U3') 2、对多维数据重复 #未指定维度np.repeat([[1],[2],[3]],2)#array([1, 1, 2, 2, 3, 3])np.repeat([[1],[2],[3]],2)np

Datawhale 零基础入门CV-Task02.数据读取与数据扩增
主要内容 数据读取数据扩增方法Pytorch读取赛题数据 学习目标 学会Python和Pytorch中图像读取学会扩增方法和Pytorch读取赛题数据 图像读取 由于赛题数据是图像数据,赛题的任务是识别图像中的字符。因此需要完成对数据的读取操作,在Python中有很多库可以完成数据读取的操作,比较常见的有Pillow和OpenCV Pillow Pillow是Python图像处理函数

【天池—街景字符编码识别】Task 2 数据读取与数据扩增
文章目录 1 简介2 学习目标3 图像读取3.1 Pillow3.1.1 安装3.1.2 基本操作3.2 OpenCV 4 数据扩增方法4.1 数据扩增介绍4.2 常见的数据扩增方法4.3 常用的数据扩增库4.3.1 torchvision4.3.2 imgaug4.3.3 albumentations 5 PyTorch读取数据(Dataset、DataLoder) 1 简介

SpeeDx扩增分销网点
与Neogen Diagnostik合作扩大在土耳其的销售 澳大利亚悉尼--(美国商业资讯)--SpeeDx已宣布签约一家新的分销伙伴,以进一步扩增客户取得市场领先的SpeeDx ResistancePlus®和PlexPCR®检测的渠道。Neogen Diagnostik Sağlık Hizmetleri Ltd Şti将在土耳其全境分销所有SpeeDx检测。 此新闻稿包含多媒

深度学习笔记(十六)正则化(L2 dropout 数据扩增 Earlystopping)
如果训练的模型过拟合,也就是高方差,我们首先想到的是正则化。高方差的解决方法有准备充足的数据,但是有时候我们无法找到足够的数据。下文详细说明正则化方法,包括L2正则化(菲罗贝尼乌斯)、dropout机制、数据扩增、Early stopping。 一、逻辑回归中的正则化 需要求得损失函数 J ( w , b ) J(w,b) J(w,b)的最小值,已知 J ( w , b ) = 1 m
网络安全公司梳理,看F5如何实现安全基因扩增
应用无处不在的当下,从传统应用到现代应用再到边缘、多云、多中心的安全防护,安全已成为企业数字化转型中的首要挑战。根据IDC2023年《全球网络安全支出指南》,2022年度中国网络安全支出规模137.6亿美元,增速位列全球第一。有专家指出,目前网络安全市场已经是仅次于计算、存储、网络的第四大IT基础设施市场。那什么才是一个优秀的网络安全公司?备受业界关注的F5又有怎样的能力?让我们一探究竟
网络安全公司梳理,看F5如何实现安全基因扩增
应用无处不在的当下,从传统应用到现代应用再到边缘、多云、多中心的安全防护,安全已成为企业数字化转型中的首要挑战。根据IDC2023年《全球网络安全支出指南》,2022年度中国网络安全支出规模137.6亿美元,增速位列全球第一。有专家指出,目前网络安全市场已经是仅次于计算、存储、网络的第四大IT基础设施市场。那什么才是一个优秀的网络安全公司?备受业界关注的F5又有怎样的能力?让我们一探究竟
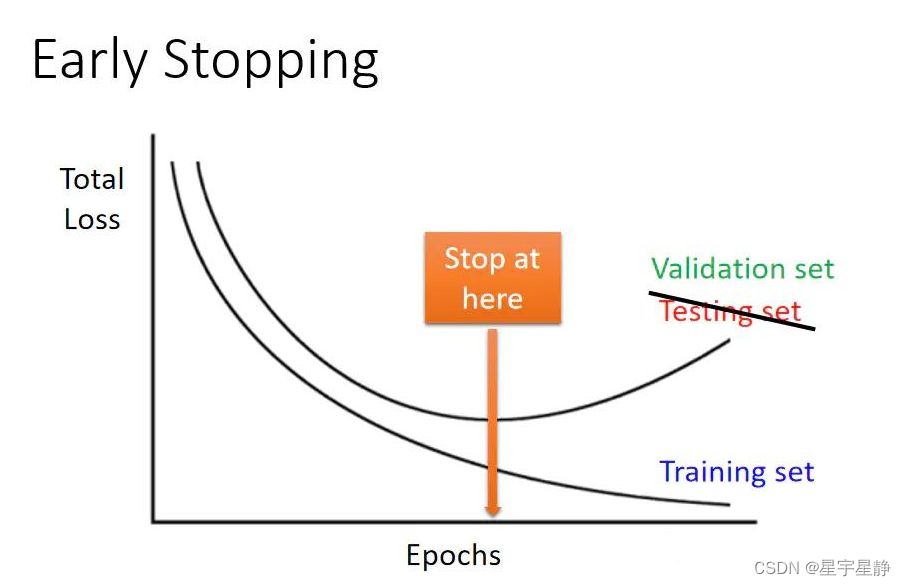
数据扩增(Data Augmentation)、正则化(Regularization)和早停止(Early Stopping)
数据扩增(Data Augmentation)、正则化(Regularization)和早停止(Early Stopping)是深度学习中常用的三种技术,它们有助于提高模型的泛化性能和防止过拟合 数据扩增(Data Augmentation) 定义:数据扩增是通过对训练集中的原始数据进行一系列变换,生成新的训练样本,从而增加训练数据的多样性。这有助于提高模型的鲁棒性,使其能够更好地泛化到未见

第十章 深度学习中的图像数据扩增(Data Augmentations)(工具)
数据增强介绍 1. 前言 这篇文章主要参考 A survey on Image Data Augmentation for Deep Learning, 总结了常用的传统扩增方法及其应用时的注意事项。这里的传统方法指不包括基于深度学习(比如 GAN)等新的扩增方法。 另外需要注意的是,虽然对于不同的任务,比如对于分类,检测任务,不同的任务在采用某一个具体的扩增方法的时候会有所不同,比如对于检
第十章 深度学习中的图像数据扩增(Data Augmentations)(工具)
数据增强介绍 1. 前言 这篇文章主要参考 A survey on Image Data Augmentation for Deep Learning, 总结了常用的传统扩增方法及其应用时的注意事项。这里的传统方法指不包括基于深度学习(比如 GAN)等新的扩增方法。 另外需要注意的是,虽然对于不同的任务,比如对于分类,检测任务,不同的任务在采用某一个具体的扩增方法的时候会有所不同,比如对于检
Augmentation for small object detection-小目标检测数据扩增
【文献阅读8】Augmentation for small object detection-小目标检测数据扩增_我是大阿周的学习博客-CSDN博客

LLM-LLaMA中文衍生模型:LLaMA-ZhiXi【没有对词表进行扩增、全参数预训练、部分参数预训练、指令微调】
下图展示了我们的训练的整个流程和数据集构造。整个训练过程分为两个阶段: (1)全量预训练阶段。该阶段的目的是增强模型的中文能力和知识储备。 (2)使用LoRA的指令微调阶段。该阶段让模型能够理解人类的指令并输出合适的内容。 3.1 预训练数据集构建 为了在保留原来的代码能力和英语能力的前提下,来提升模型对于中文的理解能力,我们并没有对词表进行扩增,而是搜集了中文语料、英文语料和

python 图片边缘扩增方法 图像分辨率调整
在进行深度学习时,我们在进行图片预操作时往往要进行一些图片的裁剪操作,在最后实验后往往需要还原成原来的图片大小。因此这里简单的进行操作。当然一些比较更复杂的还原法在这里就暂时不说了。比如 双线性插值,不改变形状的插值。这些方法跟深度学习方法的预操作的方法不同了。 在这里使用了opencv这个库进行了操作 python 版本3.6。代码如下 import cv2img = cv2.imread(