小端专题

【通讯协议数据采用大/小端存储的探讨】
前言 在嵌入式系统和网络通信中,数据的字节序是一个不可忽视的细节。不同的设备可能采用不同的字节序,常见的有大端和小端两种。小端字节序,即最低有效字节存储在最低的内存地址,在网络协议中应用普遍。本文将通过一个简单的示例,探讨如何在C语言中实现小端存储,并构建符合特定通讯协议的数据包。 实例 1.示例代码 以下是一个使用C语言编写的示例程序,该程序演示了如何将数据以小端存储的方式复制到通讯帧中:

【数据存储】大/小端存储与字节顺序转换函数详解
学习目的是使用,网络编程中主机字节顺序与网络字节顺序转换这块就用到了这些概念及其函数! 【Linux网络编程入门】Day5_socket编程基础 文章目录: 大端存储与小端存储 1.1 低地址与高地址 1.2 数据的高位与低位 1.3 大端存储 1.3.1 定义 1.3.2 小端存储举例 小端存储 2.1. 定义 2.2 小端存储举例 Linux网络通信 3.1 四个函数存在的意义

大端和小端(Big endian and Little endian):1、大端小端转换方法 2、检测方法
文章目录 前言I、例子II、大端小端转换方法III、大端小端检测方法see also 前言 大、小端指的是字节的存储顺序是按从高到低还是从低到高的顺序存储,与处理器架构有关,Intel的x86平台是典型的小端序存储方式.Java默认采用大端序存储方式,实际编码的音频数据是小端序,如果处理单8bit的音频当然不需要做转换,但是如果是16bit或者以上的就需要处理成小端字节顺序 对

大端字节和小端字节的判断及转换
当前的存储器,多以byte为访问的最小单元,当一个逻辑上的地址必须分割为物理上的若干单元时就存在了先放谁后放谁的问题,于是端(endian)的问题应运而生了,对于不同的存储方法,就有大端(big-endian)和小端(little- endian)两个描述。 字节排序按分为大端和小端,概念如下 大端(big endian):低地址存放高有效字节 小端(little endian):低
判断小端字节序和大端字节序的C程序
编写一个C程序,实现32位CPU中存储方式小端字节序和大端字节序的判别。 ONE: #include<stdio.h>#define LBS 0#define MBS 1{int main(int){int a=0x12345678;char *p;p = (char *)&a;if(*p == 0x12){return MBS;}/* if(*p == 0x78){ return
数据存储中的大端小端
数据存储中的大端小端 https://www.jianshu.com/p/bb1b882d8d61 https://blog.csdn.net/yangves/article/details/78085600 1)不同端模式的处理器进行数据传递时必须要考虑端模式的不同 2)在网络上传输数据时,由于数据传输的两端对应不同的硬件平台,采用的存储字节顺序可能 不一致。所以在TCP/I
结合Union谈大端模式,小端模式,网络字节
CPU型号:Intel(R) Core(TM) i5-2450M 系统:windows 10 IDE:Microsoft Visual C++ 6.0(下文中简称VC) 制图软件:Photoshop cs5 预备知识: 1. union的空间大小为以其成员变量中所占最大内存字节数进行内存对齐(VC默认为4字节对齐,,不足4字节补0),所有成员共享同一段内存地址,存放顺序为从低地址到高地
CPU中的大端与小端
一、CPU大端与小端的区别? 明白大端和小端的区别,实现起来就非常简单: Big-endian和little-endian是描述排列存储在计算机内存里的字节序列的术语。 Big-endian是一种高位的一端存在前面(在最小的存储地址)的顺序。Little-endian是一种低位的一端存储在前的顺序。 嵌入式系统开发者应该对Little-endian和Big-endian模式
大端格式和小端格式存储的区别
大端格式: 在这种格式中,字数据的高字节存储在低地址中,而字数据的低字节则存放在高地址中,如图2.1所示: 小端格式: 与大端存储格式相反,在小端存储格式中,低地址中存放的是字数据的低字节,高地址存放的是字数据的高字节。如图2.2所示: 请写一个C函数,若处理器是Big_endian的,则返回0;若是Little_endian的,则返回1
本机大端/小端模式测试及解释
测试程序代码: #include <stdio.h> void checkCPUendian(); int main(){ checkCPUendian(); return 0;} void checkCPUendian(){ union{ unsigned int i; unsig

狗都不学之计算机科学中缺失的内容——大端与小端
起源 "endian"一词起源于《格列佛游记》,书中人物根据吃鸡蛋时从大头(Big-Endian)吃还是从小头(Little-Endian)而分为两类人,甚至引发了战争。 同样的,在计算机领域中,对于数据的存储和传输,不同的人也产生了不同的观点。目前在各种体系的计算机中通常采用的字节存储机制主要分类两类:大端(Big-Endian)和小端(Little-Endian)。 对于Big-Endian
小端机器数据在内存中的存储
#include <iostream.h>#include <iomanip.h>union Num{ char a[4]; int b; };void main() { Num x;x.a[0]=‘A’; x.a[1]=‘B’;x.a[2]=‘C’;x.a[3]=‘D’;cout<<x.a<<endl;cout<<x.b<<endl;cout<<hex<<
.a .so .bin 文件格式分析--文件格式是32位还是64位,数据是大端还是小端,运行在 arm 上还是 x86上
可通过readelf指令,分析文.a .so .bin 文件是在什么系统上编译的,文件格式是32位还是64位,数据是大端还是小端,运行在 arm 上还是 x86上 1:格式读取说明 通过 readelf -a libbrd.a 读取文件的格式内容 File: libbrd.a(brd_audio.o)ELF Header:Magic: 7f 45 4c 46 01 01 01 00 0

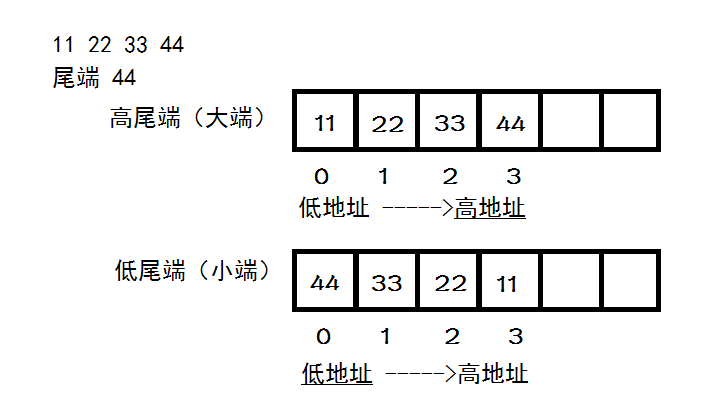
计算机系统基础 大端小端方式(巧妙记忆)
总结一句话: “大端”和小端,而是“高尾端”和“低尾端”,这就好理解了:如果把一个数看成一个字符串,比如11223344看成"11223344",末尾是个’\0’,'11’到’44’个占用一个存储单元,那么它的尾端很显然是44,前面的高还是低就表示尾端放在高地址还是低地址,它在内存中的放法非常直观,如下图: 参考链接:参考
20131213-详解大端模式和小端模式 .
原文地址:http://blog.csdn.net/ce123_zhouwei/article/details/6971544 详解大端模式和小端模式 一、大端模式和小端模式的起源 关于大端小端名词的由来,有一个有趣的故事,来自于Jonathan Swift的《格利佛游记》:Lilliput和Blefuscu这两个强国在过去的36个月中一直在苦战。战争的原因:大家都知道

【数据存储】大端存储||小端存储(超详细解析,小白一看就懂!!!)
目录 一、前言 二、什么是低地址、高地址 ? 三、什么是数据的高位和低位 ? 四、什么是大小端存储? 🍉 小端存储详解 🍒 大端存储详解 五、为什么会有大小端存储? 🍍大端存储的优点 🥝小端存储的缺点 六、实例详解 七、面试题 八、共勉 一、前言 大小端存储是计算机存储的一个设计概念,涉及了高地址和低地址,数据的高位和低位
套接字中的数据转换(大端模式/小端模式)
通常使用的有两种数据类型:短型(两个字节)和长型(四个字节)。 下面介绍的这些转换函数对于这两类的无符号整型变量都可以正确的转换。 如果你想将一个短型数据从主机字节顺序转换到网络字节顺序的话,有这样一个函数htnos: 它是以"h”开头的,代表“主机”; 紧跟着它的是"to",代表“转换到”; 然后是"n",代表“网络”; 最后是"s
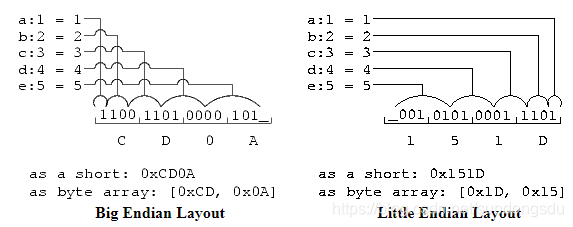
C 结构体位域 bit field (小端)
运行环境为X86 64小端: 结构体中size最大的元素t0是int, 占四个字节,因此整个结构体是4字节对齐,结构体中的short是两字节对齐。 short占两个字节16bit,因此t1,t2,t3,t4共同占用short的两个字节。t5需要两字节对齐,单独占用两个字节。 因此整个结构体占用8个字节。 GDB通过x/8bx查看结构体8个字节,小端存放,高字节在高地址,低字节在低地址。

大端、小端模式,网络字节序,多字节字符、Unicode字符存储
关于字节序(大端法、小端法)的定义 《UNXI网络编程》定义: 术语“小端”和“大端”表示多字节值的哪一端(小端或大端)存储在该值的起始地址。 小端(低字节数据)存在起始地址(低地址单元),即是小端字节序;大端存在起始地址,即是大端字节序。 也可以说: 1.小端法(Little-Endian) :高字节数据 存放在 高地址单元,低字节数据 存放在 低地址单元。
大端与小端(字节序)
1、明确0X12345678 该16进制数是从右往左读 2、小端:是低位字节指地位存放在内存的低地址端,大端:高位字节存放在内存的地址高端 Eg: 低地址--------------->高地址 0X78。。。。。。。。0X12 这个是小端 而JAVA采用大端:因此,对于多字节的基本数据类型,其首字节(低位字节)应当存储在内存的到地址部分 示例: 地址的高端与低端 0x

什么是大小端字节序存储?如何用代码判断当前的机器是大端字存储还是小端存储?
目录 什么是大端字节序存储与小端字节序存储 为什么会有大端和小端之分? 用代码判断当前机器是大端存储还是小端存储 什么是大端字节序存储与小端字节序存储 1.字节序:以字节为单位,讨论存储顺序 2.大端字节序存储:高位在低地址处 小端字节序存储:高位在低地址处 什么是高位?比如1234中1就是高位,4就是低位。 3.只有字节数超过一个字节的类型才讨论存储顺序,char类
网络字节序 大端( big endian) 小端 (little endian) 字节序 主机序
以前经常遇到大端、小端、网络字节序、字节序 、主机序等概念经常记住了又忘记,用的时候就查,很耗时,终归其实也是没有完全理解导致,这次就记录一下吧,将这个理解透彻吧。 查网上资料看了感觉还是不是很可信,于是我查阅了多本书籍,并截图,方便以后查阅与复习。如果有侵权请联系及时删除。 前言: 我个人认为应该分成存储中大小端和网络中的大小端,当然这个是我个人理解,还不一定对,有待验证。


大端和小端传输字节序
大端和小端传输字节序 大端和小端一、最高有效位、最低有效位1.MSB(Most significant Bit)最高有效位2.LSB(Least Significant Bit)最低有效位 二、内存地址三、大端和小端四、网络字节序和主机字节序五、C#位操作符六、C#中关于大端和小端的转换七、关于负数八、关于汉字编码以及与字节序的关系网络通讯文件 大端和小端 在计算机中是以字节