本文主要是介绍网络字节序 大端( big endian) 小端 (little endian) 字节序 主机序,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
以前经常遇到大端、小端、网络字节序、字节序 、主机序等概念经常记住了又忘记,用的时候就查,很耗时,终归其实也是没有完全理解导致,这次就记录一下吧,将这个理解透彻吧。
查网上资料看了感觉还是不是很可信,于是我查阅了多本书籍,并截图,方便以后查阅与复习。如果有侵权请联系及时删除。
前言:
我个人认为应该分成存储中大小端和网络中的大小端,当然这个是我个人理解,还不一定对,有待验证。
一、存储中的大端与小端
摘抄《ARM体系结构与编程》

二、存储中的大端与小端和网络中的大小端
摘抄《UNIX网络编程卷1:套接字联网API (第三版)》


对于一个由2个字节组成的16位整数,在内存中存储这两个字节有两种方法:一种是将低序字节存储在起始地址,这称为小端(little-endian)字节序;另一种方法是将高序字节存储在起始地址,这称为大端(big-endian)字节序。
在图3-9中,顶部表明内存地址增长方向从右到左,在底部标明内存地址增长的方向为从左到右。并且还标明最高有效位(most significant bit,MSB)是这个16位值最左边一位,最低有效位(least significant bit, LSB)是这个16位值最右边一位。
术语“小端”和“大端”表示多个字节值的哪一端(小端或大端)存储在该值的起始地址。
这两种字节序没有标准可循,都有系统在使用。把某个给定系统所用的字节序称为主机字节序,可以用以下程序输出主机字节序。方法是在一个短整数变量中存放2字节的值0x0102,然后查看它的连续字节c[0](对应上图地址A)和c[1](对应上图地址A+1),以此确定字节序。

三、网络中的大小端
摘抄自《 TCP/IP详解 卷1:协议》

四、摘抄其他博客:
博客一
网络上传输的数据都是字节流,对于一个多字节数值,在进行网络传输的时候,先传递哪个字节?也就是说,当接收端收到第一个字节的时候,它将这个字节作为高位字节还是低位字节处理,是一个比较有意义的问题:
UDP/TCP/IP协议规定:把接收到的第一个字节当作高位字节看待,这就要求发送端发送的第一个字节是高位字节;而在发送端发送数据时,发送的第一个字节是该数值在内存中的起始地址处对应的那个字节,也就是说,该数值在内存中的起始地址处对应的那个字节就是要发送的第一个高位字节
所以:网络字节序就是大端字节序, 有些系统的本机字节序是小端字节序, 有些则是大端字节序, 为了保证传送顺序的一致性, 所以网际协议使用大端字节序来传送数据。
版权声明:此段为其他博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
此文链接:https://blog.csdn.net/JMW1407/article/details/108637540
博客二
在计算机里,对于地址的描述,很少用“大”和“小”来形容;对应地,用的更多的是“高”和“低”;很不幸地,这对术语直接按字面翻译过来就成了“大端”和“小端”,让人产生迷惑也不是很奇怪的事了。
不过给我启发的是,在裘宗燕翻译的《程序设计实践》里,这对术语并没有翻译为“大端”和小端,而是“高尾端”和“低尾端”,这就好理解了:如果把一个数看成一个字符串,比如11223344看成"11223344",末尾是个'\0','11'到'44'个占用一个存储单元,那么它的尾端很显然是44,前面的高还是低就表示尾端放在高地址还是低地址,它在内存中的放法非常直观,如下图:
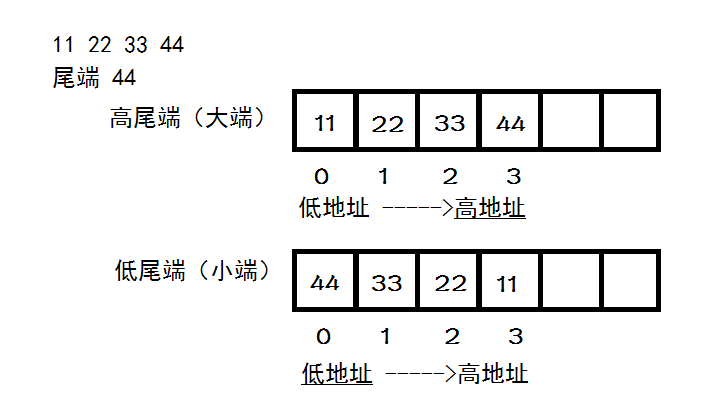
“高/低尾端”比“大/小端”更不容易让人迷惑。但是根据个人经验,在市面上的书籍、网络上的各种资料中,很遗憾,前者已经很少见了,多见的是后者。好在这两对形容词中,恰好“高”和“大”对应,“低”和“小”对应;既然高尾端对应的是大端,低尾端对应的是小端,那么当你再见到大端和小端这一对术语,就可以在脑中把它们转化成高尾端和低尾端,这时凭着之前的理解,甚至不用回忆,想着高低的字面含义就能回想起它们的含义。但是很奇怪的是,同样是裘宗燕翻译的《编程原本》(Elements of Programming),却把big-endian翻译成大尾格式(第一章)。
版权声明:此段为其他博主原创文章,转载请先咨询原博主。
链接:https://www.cnblogs.com/isAndyWu/p/10788990.html
博客三
小端就是低位在前(低位字节存在内存低地址,字节高低顺序和内存高低地址顺序相同),大端就是高位在前,(其中“前”是指靠近内存低地址,存储在硬盘上就是先写那个字节)。概念上字节序也叫主机序。
链接:https://blog.csdn.net/anningzte/article/details/52125665
博客四
如果LSByte在MSByte的前面,即LSB为低地址,则该字节序是小端序;反之则是大端序。
链接:https://social.technet.microsoft.com/Forums/en-US/471e01d4-2614-441c-b068-39259368998f?forum=1761
总结
根据以上看哪种方式适合方便你记忆,选择一种即可,根据《UNIX网络编程卷1》中的术语我认为可以这样记:
起始地址存储大端(即高字节)就是大端
起始地址存储小端(即低字节)就是小端
a) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
b) Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
c) 网络字节序:TCP/IP各层协议将字节序定义为大端(Big-Endian),因此TCP/IP协议中使用的字节序通常称之为网络字节序。
有些书籍或文章中称低位字节、低字节、低有效位、最低有效位、低位都是一个意思,都是指是低字节。
同理高位字节、高字节、高有效位、最高有效位、高位都是一个意思,都是指是高字节。
这篇关于网络字节序 大端( big endian) 小端 (little endian) 字节序 主机序的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






