本文主要是介绍C 结构体位域 bit field (小端),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
运行环境为X86 64小端:
结构体中size最大的元素t0是int, 占四个字节,因此整个结构体是4字节对齐,结构体中的short是两字节对齐。
short占两个字节16bit,因此t1,t2,t3,t4共同占用short的两个字节。t5需要两字节对齐,单独占用两个字节。
因此整个结构体占用8个字节。
GDB通过x/8bx查看结构体8个字节,小端存放,高字节在高地址,低字节在低地址。
t0是0x00102030, 从低地址到高地址依次是: 0x30 0x20 0x10 0x00
t1,t2,t3,t4存放在同一个short两字节中,t4作为most significant,在内存中从低地址到高地址存放依次为t1,t2,t3,t4。
如果在GDB中以双字节打印这个short,显示顺序为t4t3t2t1,即0xdcba
如果以字节方式打印,由于short占用两个字节(高端字节t4t3,低端字节t2t1),高端字节存放在高地址,因此显示顺序为t2t1t4t3, 即0xba 0xdc
注意:不管何种方式打印,首先要明确的是t1t2t3t4是作为short类型存放的,然后再考虑各种方式打印这个short两字节的不同。
t5内容为0x000E, 小端存放为0x0E00
#include <stdio.h>
#include <string.h>typedef struct bit_field{unsigned int t0;unsigned short t1 : 4;unsigned short t2 : 4;unsigned short t3 : 4;unsigned short t4 : 4;unsigned short t5 : 4;
}bf;void endian_check()
{int i = 0x1;unsigned char *p;p = (unsigned char *)&i;if (*p)printf("little endian\r\n");elseprintf("big endian\r\n");return;
}main()
{endian_check();printf("size of uint is: %d\r\n", sizeof(unsigned int));printf("size of ushort is: %d\r\n", sizeof(unsigned short));printf("size of bit_field structure is: %d\r\n", sizeof(bf));bf bf_test;memset(&bf_test, 0, sizeof(bf_test));bf_test.t0 = 0x102030;bf_test.t1 = 0x0A;bf_test.t2 = 0x0B;bf_test.t3 = 0x0C;bf_test.t4 = 0x0D;bf_test.t5 = 0x0E;
}
输出为:
little endian
size of uint is: 4
size of ushort is: 2
size of bit_field structure is: 8
通过GDB查看内存字节存放:
(gdb) p bf_test
$1 = {t0 = 1056816, t1 = 10, t2 = 11, t3 = 12, t4 = 13, t5 = 14}
(gdb) x/4hx &bf_test
0x7fffffffe230: 0x2030 0x0010 0xdcba 0x000e
(gdb) x/8bx &bf_test
0x7fffffffe230: 0x30 0x20 0x10 0x00 0xba 0xdc 0x0e 0x00
以下内容from http://mjfrazer.org/mjfrazer/bitfields/
How Endianness Effects Bitfield Packing
Hints for porting drivers.
Big endian machines pack bitfields from most significant byte to least.
Little endian machines pack bitfields from least significant byte to most.
When we read hexidecimal numbers ourselves, we read them from most significant byte to least. So reading big endian memory dumps is easer than reading little endian. When it comes to reading memory dumps of bitfields, it is even harder than reading integers.
Consider:
union {unsigned short value;unsigned char byte[2];struct {unsigned short a : 4;unsigned short b : 4;unsigned short c : 4;unsigned short d : 4;} field;} u;On a big endian machine, the first field is in the first nibble in memory. When we print out a memory dump's character hex values, say [ 0x12, 0x34 ], it is easy to see that a = 1, b = 2, c = 3 and d = 4.
On a little endian machine, a memory dump of [ 0x12, 0x34 ] would indicate that a = 2, b = 1, c = 4, and d = 3. This is because our 2-nibble, or 1 byte, hex value has transposed the pairs of nibbles. Remember that field a would go in the least significant bits, so if we set (a, b, c, d) = (1, 2, 3, 4) we would read the nibbles from least significant to most as 1 2 3 4, but the bytes as 0x21, 0x43. Interpreting this memory as a short gives us the value 0x4321.
These two figures illustrate how the nibble sized elements are packed into memory with the 16 bit field being laid out from MSB to LSB.
| Big Endian Layout | Little Endian Layout |
|---|
注意:上图中
左图:对于大端来说,左侧为低地址,右侧为高地址。a为most significant, d为least significant
右图:对于小端来说,右侧为低地址,左侧为高地址。a为least significant, d为most significant
Now consider:
union {unsigned short value;unsigned char byte[2];struct {unsigned short a : 1;unsigned short b : 2;unsigned short c : 3;unsigned short d : 4;unsigned short e : 5;} field;} v;Again, the bits are pack from most significant on a big endian machine and least significant on a little endian machine. Interpreted as a short, the bitfield 'a' adds 0x0001 to 'value' on a little endian machine and 0x8000 on a big endian machine. The unused bit is left to the end of interpreting the struct, so it is the MSB on a little endian machine and the LSB on a big endian machine.
These two figures illustrate how the differently sized elements are packed into memory with the 16 bit field being laid out from MSB to LSB.
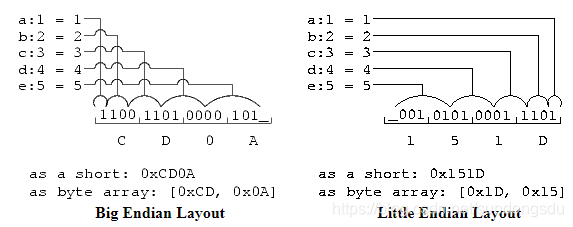
注意:上图中
左图:对于大端来说,左侧为低地址,右侧为高地址。a为most significant, d为least significant
右图:对于小端来说,右侧为低地址,左侧为高地址。a为least significant, d为most significant
参考:
http://mjfrazer.org/mjfrazer/bitfields/
这篇关于C 结构体位域 bit field (小端)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







