本文主要是介绍【数据存储】大端存储||小端存储(超详细解析,小白一看就懂!!!),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、前言
二、什么是低地址、高地址 ?
三、什么是数据的高位和低位 ?
四、什么是大小端存储?
🍉 小端存储详解
🍒 大端存储详解
五、为什么会有大小端存储?
🍍大端存储的优点
🥝小端存储的缺点
六、实例详解
七、面试题
八、共勉
一、前言
大小端存储是计算机存储的一个设计概念,涉及了高地址和低地址,数据的高位和低位等概念,所以在理解大小端存储之前,需要知道什么是高地址和低地址,什么是数据的高位和低位,这样才能更好的理解大小端存储。
二、什么是低地址、高地址 ?
为了便于管理存储地址,给地址进行编号,值较大的地址是高地址,值较小的地址是低地址
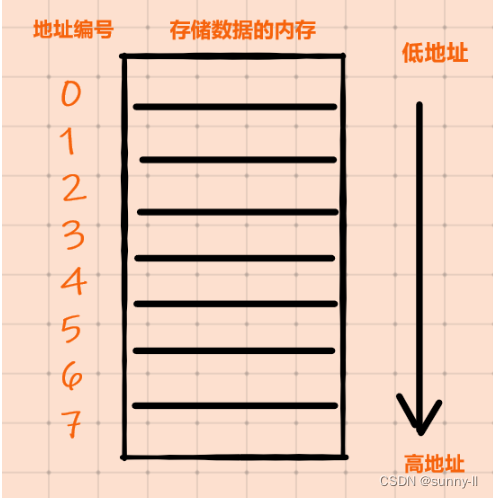
✨注意:计算机读数据永远是从低地址开始的!!!
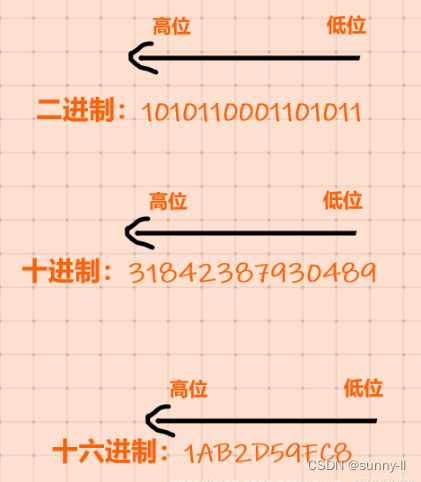
三、什么是数据的高位和低位 ?
数据的高位是数据的左边位置的数,数据的低位是数据右边位置的数,数据的高位和低位又称高字节和低字节。
四、什么是大小端存储?
大端存储,是将数据的低位字节放到高地址处,高位字节放到低地址处。
小端存储,是将数据的低位字节放到低地址处,高位字节放到高地址处。
大端存储和小端存储的区别是,低位字节放在高地址还是什么是低地址?大端存储的特点是低位字节存放在高地址,小端存储的特点是低位字节存放在低地址,这样可以方便记忆。
🍉 小端存储详解
数据的低位放在低地址空间,数据的高位放在高地址空间
简记:小端就是低位对应低地址,高位对应高地址
✨ 图例1:存放二进制数:1011-0100-1111-0110-1000-1100-0001-0101

注意注意:我们在存放的时候是以一个存储单元为单位来存放,存储单元内部不需要再转变顺序啦!!
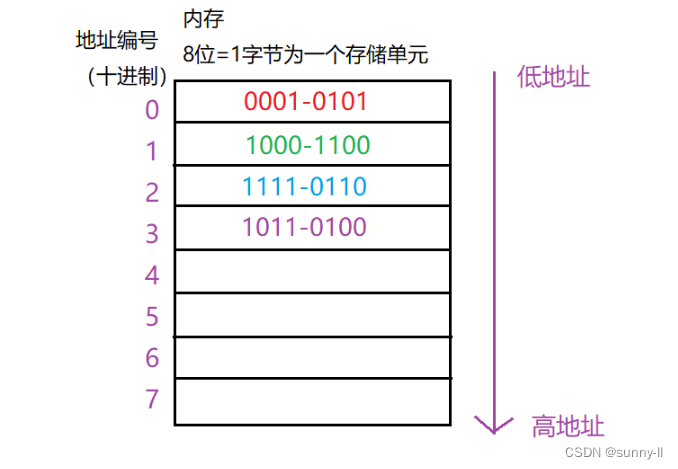
注意一定一定是从低地址读起!!!我们知道这是小端存储,所以在读出来的时候会从低位开始放!!!
✨ 图例2:存放十六进制数:2AB93584FE1C
十六进制数每一位转化为二进制就是4位:2对应0010,A对应1010,以此类推。所以在存放的时候两个十六进制位就占用一个存储单元
注意注意:一个字节为一个存储单元
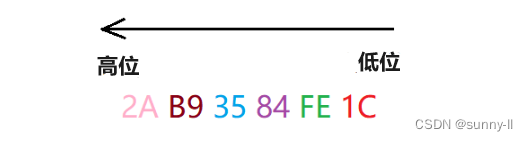
注意注意:计算机读数据永远是从低地址开始的!!!

🍒 大端存储详解
数据的高位放在低地址空间,数据的低位放在高地址空间
简记:大端就是低位对应高地址,高位对应低地址
✨ 图例1:存放二进制数:1011-0100-1111-0110-1000-1100-0001-0101

读取数据:注意仍然是从低地址开始读,我们知道这是大端模式,当我们从0号地址读到1011-0100时,我们知道它是高位,所以放到高位的位置上去
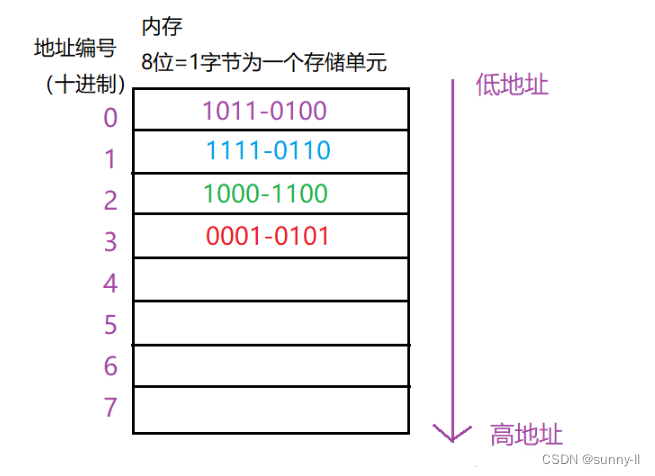
✨ 图例2:存放十六进制数:2A-B9-35-84-FE-1C
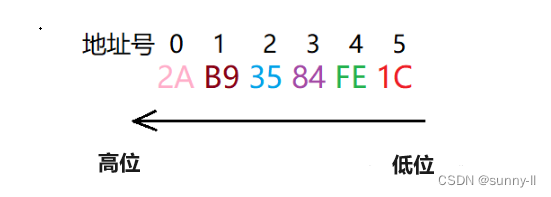
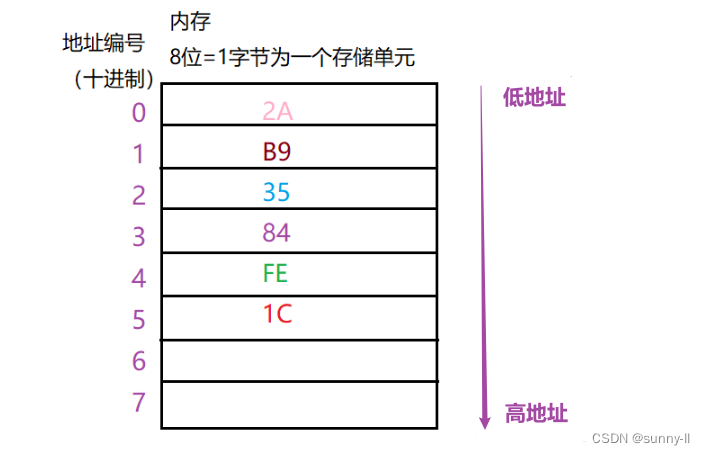
读取数据:注意从低地址开始读取,读到的从高地址开始放!!!
五、为什么会有大小端存储?
为什么会有大小端模式之分呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8 bit。但是在C语言中除了8 bit的char之外,还有16 bit的short型,32 bit的long型(要看具体的编译器)。
另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
⭐例如:一个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么 0x11 为高字节, 0x22 为低字节。
对于大端模式,就将 0x11 放在低地址中,即 0x0010 中, 0x22 放在高地址中,即 0x0011 中。
小端模式,刚好相反。
我们常用的 X86 结构是小端模式,而 KEIL C51 则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
🍍大端存储的优点
符号位在所表示的数据的内存的第一个字节中,便于快速判断数据的正负和大小
🥝小端存储的缺点
1.CPU做数值运算时从内存中按顺序依次从低位到高位取数据进行运算,直到最后刷新最高位的符号位,这样的运算方式会更高效
2.内存的低地址处存放低字节,所以在强制转换数据时不需要调整字节的内容
六、实例详解
#include<stdio.h>
int main()
{int a = 0x11223344;short b = 0x5566;return 0;
}
我们先来看16进制的数据0x11223344和0x5566
我们知道,1个十六进制位是4个bit位,2个十六进制位就是8个bit位,也就是1个字节,那0x11223344是8个十六进制位,也就是4个字节,0x5566就是2个字节。a和b都是大于1个字节,放在内存中就有存储先后的问题。----- 大小端存储
那么具体怎么布局的呢,我们以0x11223344和0x5566为例来看看。
以下编译器为vs2022
a的内存:

b的内存:

比如a我们可以看到,数据在内存中是顺着存的,即数据的低位保存在内存的低地址中,b同理,说明这个编译器里的存储模式为小端存储模式。
我们同时也可以看到,整型数据在内存中存储,是以字节为单位在布局它的顺序的。
七、面试题
百度2015年系统工程师笔试题:
请简述大端字节序和小端字节序的概念,设计一个小程序来判断当前机器的字节序。(10分)
以刚才的0x11223344为例,如果是大端存储模式,那第一个字节里存放的就是11;如果是小端存储模式,那第一个字节里存放的就是44。
我们换一组简单的数据来表示int a=1;//即0x00000001
如果按照大端存储模式,第一个字节里存的是00
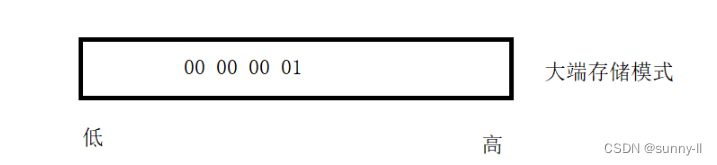
如果按照小端存储模式,第一个字节里存的就是01
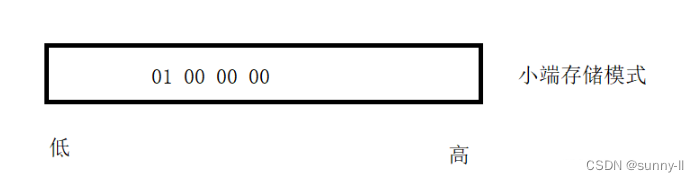
我们知道,如果我们拿到一个整型的地址,即指针的类型为int*,对它进行解引用,那么就向后访问4个字节,如果指针的类型是char*类型的话,那么就只用访问一个字节。
按这个思路,我们用代码来实现一下
int main()
{int a = 1;// 注意 :读取数据永远都是从低地址开始//此时*p取出的就是第一个字节里的数据 ----- 低地址的数据char* p = (char*)&a;if (*p == 1){printf("小端\n");}else{printf("大端\n");}return 0;
}先来看这行代码
char* p=(char*)&a;
&a的类型本来应该是int*,但我们要利用char*指针,所以对&a强制类型转换。if (*p == 1)这行,此时*p取出的就是第一个字节里的数据。如果取出的是1,说明是小端存储,如果取出的是0,说明是大端存储。
八、共勉
以下就是我对【数据存储】大端存储||小端存储的理解,如果有不懂和发现问题的小伙伴,请在评论区说出来哦,同时我还会继续更新对结构体内存对齐的理解,请持续关注我哦!!!!!

这篇关于【数据存储】大端存储||小端存储(超详细解析,小白一看就懂!!!)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



