密集型专题

Python线程 适合I/O处理以及涉及阻塞操作的并发执行任务,不适合计算密集型
文章目录 为什么这种情况适合 I/O 和阻塞操作?1. I/O 操作和阻塞操作的特点:I/O 操作:阻塞操作: 2. GIL 对计算密集型任务的影响:计算密集型任务:GIL 的限制: 3. I/O 和阻塞操作的优势:I/O 操作的非 CPU 密集性:多线程的并发性: 具体示例:计算密集型任务:I/O 密集型任务: 总结: 全局解释器锁(Global Interpreter Lock
DDIA(数据密集型应用系统设计)第二版出了【part 1】
深受喜爱的DDIA终于出第二版了! 不过目前还属于 Early Release 版本阶段,只发布了前三章。 本书在GitHub 上的地址是:GitHub - ept/ddia2-feedback: Reader feedback on the early release of Designing Data-Intensive Applications, second edition

C++编程:使用C++多线程和POSIX库模拟CPU密集型工作
文章目录 0. 引言1. 设计思路2. 代码实现与详解2.1 忙等待机制:`BusyWait` 函数2.2 核心工作函数:`Work`2.3 主函数:`main` 3. CPU使用模式分析4. 完整代码 0. 引言 本文深入探讨了如何利用C++与POSIX线程库(pthread)编写多线程程序,以模拟不同负载下的CPU资源占用情况。 该工具应用在Linux编程: C++程序线程

「阅读」数据密集型系统设计 第六章 分区
文章目录 6.1 介绍6.2 如何实现分区?6.2.1 键值数据分区6.2.2 分区和次级索引次级索引的分区问题方案一:基于文档的分区-本地索引方案二:基于关键词的分区-全局索引 6.2.3 分区再平衡问题 && 解决方案问题介绍策略一:hash && Mod N(不推荐)策略二:固定数量分区策略三:动态分区策略四:按照节点比例分区 6.1 介绍 什么是分区? 分区是通过特定

设计数据密集型应用 第六章:分区
6. 分区 我们必须跳出电脑指令序列的窠臼。 叙述定义、描述元数据、梳理关系,而不是编写过程。 —— Grace Murray Hopper,未来的计算机及其管理(1962) 文章目录 6. 分区术语澄清 分区与复制键值数据的分区根据键的范围分区根据键的散列分区一致性哈希 负载倾斜与消除热点 分片与次级索引基于文档的二级索引进行分区基于关键词(Term)的二级索引进行分

设计数据密集型应用 第三章:存储与检索
3. 第三章:存储与检索 建立秩序,省却搜索 ——德国谚语 文章目录 3. 第三章:存储与检索驱动数据库的数据结构哈希索引SSTables和LSM树构建和维护SSTables用SSTables制作LSM树性能优化 B树让B树更可靠B树优化 比较B树和LSM树LSM树的优点LSM树的缺点 其他索引结构将值存储在索引中多列索引全文搜索和模糊索引在内存中存储一切 事务处理还是分

设计数据密集型应用 第二章:数据模型与查询语言
第二章:数据模型与查询语言 语言的边界就是思想的边界。 —— 路德维奇·维特根斯坦,《逻辑哲学》(1922) 文章目录 第二章:数据模型与查询语言关系模型与文档模型NoSQL的诞生对象关系不匹配多对一和多对多的关系文档数据库是否在重蹈覆辙?网络模型关系模型与文档数据库相比 关系型数据库与文档数据库在今日的对比哪种数据模型更有助于简化应用代码?文档模型中的架构灵活性查询的数据

设计数据密集型应用 第一章:可靠性,可伸缩性,可维护性
第一章:可靠性,可伸缩性,可维护性 原文地址 互联网做得太棒了,以至于大多数人将它看作像太平洋这样的自然资源,而不是什么人工产物。上一次出现这种大规模且无差错的技术, 你还记得是什么时候吗? ——阿兰·凯在接受Dobb博士杂志采访时说(2012年) 文章目录 第一章:可靠性,可伸缩性,可维护性关于数据系统的思考可靠性硬件故障软件错误人为错误可靠性有多重要? 可伸缩性描述负载

【数据密集型系统设计】软件系统的可靠性、可伸缩性、可维护性
文章目录 一. 数据密集型程序的特点以及遇到的问题二. 可靠性 : 即使出现问题,也能继续正确工作1 硬件故障2. 软件错误3. 人为错误 二. 可伸缩性1. 描述负载与推特的例子2. 描述性能-延迟和响应时间3. 应对负载的方法 四. 可维护性1. 可操作性:人生苦短,关爱运维2. 简单性:管理复杂度3. 可演化性:拥抱变化 本文讨论了软件系统的可靠性,可伸缩性和可维护性。

CPU io-密集型 计算密集型
核心是可以分别独立运行程序指令的计算单元。 线程是操作系统能够进行运算调度的最小单位。 有一个原则是:活跃线程数为 CPU(核)数时最佳。过少的活跃线程导致 CPU 无法被充分利用,过多的活跃线程导致过大的线程上下文切换开销。 线程应该是活跃的,处于 IO 的线程,休眠的线程等均不消耗 CPU。 在Java并发编程方面,计算密集型与IO密集型是两个非常典型的例子,这次大象就来讲讲自己在这方面
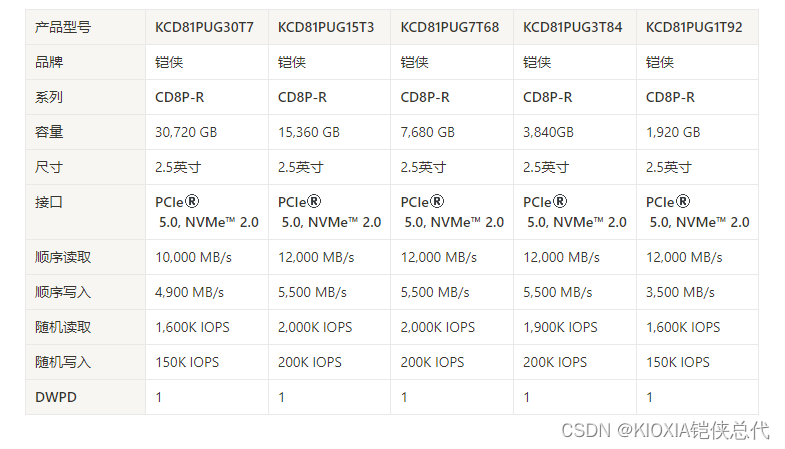
KIOXIA CD8P-R 1.92TB SSD KCD81PUG1T92数据中心读密集型
KIOXIA全新推出的CD8P-R系列数据中心级读密集型SSD - KCD81PUG1T92型号。这款SSD不仅在性能和可靠性方面表现出色,还能为您的数据中心应用带来前所未有的体验。 首先,让我们一起来看看KCD81PUG1T92的关键亮点: 超高性能: KCD81PUG1T92采用PCIe 5.0和NVMe 2.0规范,最高可提供2,000,000 IOPS的随机读取性能和200,000
io密集型 和 cpu(计算密集型)
I/O bound 指的是系统的CPU效能相对硬盘/内存的效能要好很多,此时,系统运作,大部分的状况是 CPU 在等 I/O (硬盘/内存) 的读/写,此时 CPU Loading 不高。 CPU bound 指的是系统的 硬盘/内存 效能 相对 CPU 的效能 要好很多,此时,系统运作,大部分的状况是 CPU Loading 100%,CPU 要读/写 I/O (硬盘/内存),I/O在很短

《数据密集型应用系统设计》笔记——第一部分 数据系统基础(ch1-4)
写在前面:对DDIA这本书慕名已久,粗看书里的一些知识都或多或少了解,但仔细阅读下来,还是缺少对细节的认识。目前看了四个章节,这本书一直在围绕两个问题:是什么和为什么,来做阐述,针对工业界已有的技术和存在的问题分析的非常细致,让我时常有种恍然大悟的感觉,对各种知识之间的关联讲述的非常到位。所以写下每章要点的笔记,时常回顾时常新 第1章 可靠、可扩展与可维护的应用系统 Redis既可以用于数据存
Go语言中栈和堆对数据密集型应用程序性能的影响
在 Go 中,变量可以被分配在栈上或堆上。这两种类型的内存在根本上是不相同的,它们可以显著影响数据密集型应用程序的性能。 1. 栈 vs 堆 首先,让我们讨论一下栈和堆的区别。栈是默认内存;它是一种后进先出(LIFO)的数据结构,用于存储特定 goroutine 的所有局部变量。当一个 goroutine 启动时,它会获得 2 KB 的连续内存作为它的栈空间(这
数据密集型应用系统设计 PDF 电子书(Martin Kleppmann 著)
简介 《数据密集型应用系统设计》全书分为三大部分: 第一部分,主要讨论有关增强数据密集型应用系统所需的若干基本原则。首先开篇第 1 章即瞄准目标:可靠性、可扩展性与可维护性,如何认识这些问题以及如何达成目标。第 2 章我们比较了多种不同的数据模型和查询语言,讨论各自的适用场景。接下来第 3 章主要针对存储引擎,即数据库是如何安排磁盘结构从而提高检索效率。第 4 章转向数据编码(序列化)方面
鸿蒙OS开发实例:【ArkTS类库多线程CPU密集型任务TaskPool】
CPU密集型任务是指需要占用系统资源处理大量计算能力的任务,需要长时间运行,这段时间会阻塞线程其它事件的处理,不适宜放在主线程进行。例如图像处理、视频编码、数据分析等。 基于多线程并发机制处理CPU密集型任务可以提高CPU利用率,提升应用程序响应速度。 当进行一系列同步任务时,推荐使用Worker;而进行大量或调度点较为分散的独立任务时,不方便使用8个Worker去做负载管理,推荐采用Tas

鸿蒙OS开发案例:【ArkTS类库多线程CPU密集型任务Worker】
使用Worker进行长时间数据分析 通过某地区提供的房价数据训练一个简易的房价预测模型,该模型支持通过输入房屋面积和房间数量去预测该区域的房价,模型需要长时间运行,房价预测需要使用前面的模型运行结果,因此需要使用Worker。 1.DevEco Studio提供了Worker创建的模板,新建一个Worker线程,例如命名为“MyWorker”。 2.在主线程中通过调用ThreadW

Node.js 软肋之 CPU 密集型任务
Node.js 在官网上是这样定义的:“一个搭建在Chrome JavaScript 运行时上的平台,用于构建高速、可伸缩的网络程序。Node.js 采用的事件驱动、非阻塞I/O 模型使它既轻量又高效,是构建运行在分布式设备上的数据密集型实时程序的完美选择。”Web 站点早已不仅限于内容的呈现,很多交互性和协作型环境也逐渐被搬到了网站上,而且这种需求还在不断地增长。这就是所谓的数据密集型实时(da
鸿蒙OS开发实例:【ArkTS类库多线程I/O密集型任务开发】
使用异步并发可以解决单次I/O任务阻塞的问题,但是如果遇到I/O密集型任务,同样会阻塞线程中其它任务的执行,这时需要使用多线程并发能力来进行解决。 I/O密集型任务的性能重点通常不在于CPU的处理能力,而在于I/O操作的速度和效率。这种任务通常需要频繁地进行磁盘读写、网络通信等操作。此处以频繁读写系统文件来模拟I/O密集型并发任务的处理。 定义并发函数,内部密集调用I/O能力。 import
IO密集型任务(多线程)||计算密集型(多进程)
IO密集型任务 是指磁盘IO、网络IO占主要的任务,计算量很小。 比如请求网页、读写文件等。 在Python中可以利用sleep达到IO密集型任务的目的。 Python中的多线程适合IO密集型任务,而不适合计算密集型任务。 计算密集型任务 是指CPU计算占主要的任务,CPU一直处于满负荷状态。 比如在一个很大的列表中查找元素(当然这不合理),复杂的加减乘除等。 Python
鸿蒙原生应用开发-ArkTS语言基础类库多线程CPU密集型任务TaskPool
CPU密集型任务是指需要占用系统资源处理大量计算能力的任务,需要长时间运行,这段时间会阻塞线程其它事件的处理,不适宜放在主线程进行。例如图像处理、视频编码、数据分析等。 基于多线程并发机制处理CPU密集型任务可以提高CPU利用率,提升应用程序响应速度。 当进行一系列同步任务时,推荐使用Worker;而进行大量或调度点较为分散的独立任务时,不方便使用8个Worker去做负载管理,推荐采用TaskPo

数据密集型应用系统设计
数据密集型应用系统设计 原文完整版PDF:https://pan.quark.cn/s/d5a34151fee9 这本书的作者是少有的从工业界干到学术界的牛人,知识面广得惊人,也善于举一反三,知识之间互相关联,比如有个地方把读路径比作programming language的lazy evaluation而写路径比作eager evaluation,令人拍案。这一本数囊括了几乎所有数
数据密集型应用系统设计--第2章 数据模型与查询语言
一、引言 数据模型可能是开发软件最重要的部分,而且还对如何思考待解决的问题都有深远的影响。 大多数应用程序是通过一层一层叠加数据模型来构建的。每一层都面临的关键问题是:如何将其用下一层来表示? 1.作为一名应用程序开发人员,观测现实世界(其中包括人员、组织、货物、行为、资金流动、传感器等),通过对象或数据结构,以及操作这些数据结构的API来对其建模。这些数据结构往往特定于该应用。
高密集型数据服务--第2章 数据模型与查询语言
一、引言 数据模型可能是开发软件最重要的部分,而且还对如何思考待解决的问题都有深远的影响。 大多数应用程序是通过一层一层叠加数据模型来构建的。每一层都面临的关键问题是:如何将其用下一层来表示? 1.作为一名应用程序开发人员,观测现实世界(其中包括人员、组织、货物、行为、资金流动、传感器等),通过对象或数据结构,以及操作这些数据结构的API来对其建模。这些数据结构往往特定于该应用。
IO密集型场景和CPU密集型场景——具体场景汇总
前言 多线程适合处理IO密集型任务,而多进程适合处理CPU密集型任务。选择使用哪种并发模型需要根据具体的应用场景和需求进行权衡。在 Python 中,可以使用 threading 模块实现多线程编程,使用 multiprocessing 模块实现多进程编程。 进阶详解 IO密集型场景是指程序执行时需要大量的输入输出操作(如文件读写、网络通信等),而CPU占用率相对较低的场景。在这种场景下,程
CPU密集型和IO密集型与CPU内核之间的关系
CPU密集型和IO密集型与CPU内核之间的关系 CPU 密集型 CPU密集型(CPU-bound)是指在程序运行过程中,主要由计算和逻辑运算任务占用大部分时间,而不是等待外部IO(输入/输出)完成。这类任务主要依赖于 CPU 的计算能力,而不是等待外部数据的读取或写入。在CPU密集型任务中,CPU 的运算能力是系统性能的瓶颈。 特点和场景: 计算需求高: CPU密集型任务通常需要进行大量的