实时处理专题

AppInventor2 文本输入框(TextBox)已支持文本变更事件,非常便于实时处理输入的内容
自 v2.70开始,文本输入框加入了文本变更事件: 效果如下: 文本事件.gif (99.17 KB, 下载次数: 3) 下载附件 昨天 19:57 上传 同理,密码输入框组件也是一样的。 原文:AppInventor2 文本输入框(TextBox)已支持文本变更事件,非常便于实时处理输入的内容 - App Inventor 2 中文网 - 清泛IT社区,为创新赋能!

Druid:一个用于大数据实时处理的开源分布式系统之怎么用
简单使用介绍 Druid与其他数据库连接池使用方法基本一样(与DBCP非常相似),将数据库的连接信息全部配置给DataSource对象 下面给出2种配置方法实例: 1. 纯Java代码创建 dataSource = new DruidDataSource();dataSource.setDriverClassName("com.mysql.jdbc.Driver");
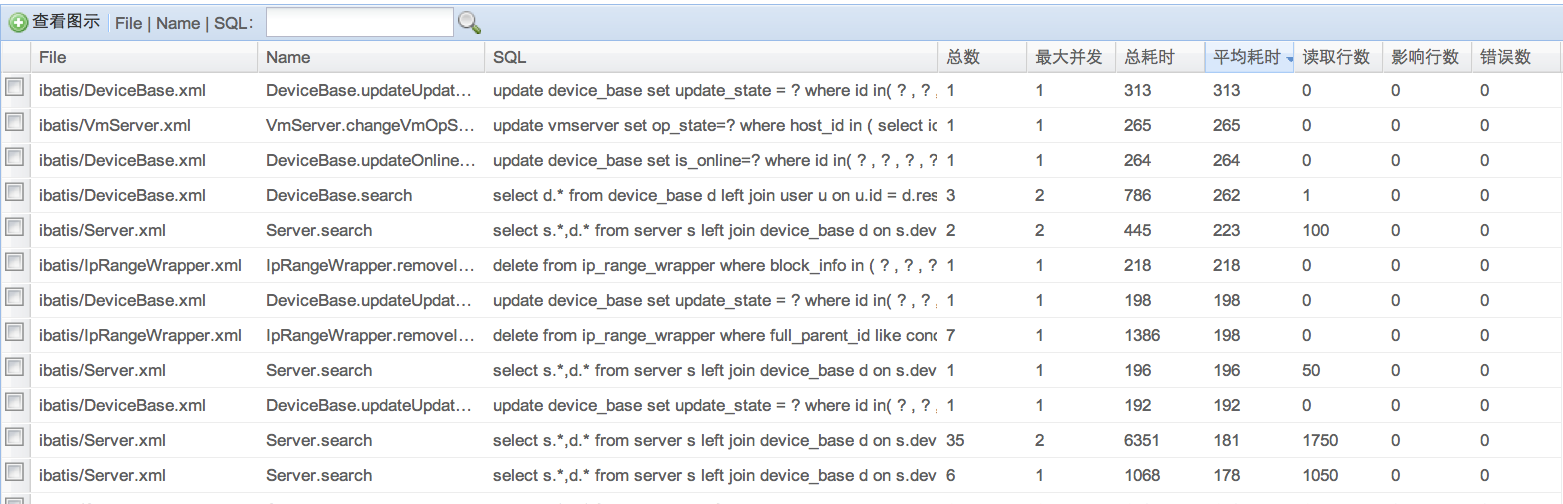
Druid:一个用于大数据实时处理的开源分布式系统之是什么
Druid是一个JDBC组件,它包括三部分: DruidDriver 代理Driver,能够提供基于Filter-Chain模式的插件体系。 DruidDataSource 高效可管理的数据库连接池。 SQLParser Druid可以做什么? 1) 可以监控数据库访问性能,Druid内置提供了一个功能强大的StatFilter插件,能够详细统计SQL的执行性能

Flink学习笔记1--安装NC,运行Flink实时处理
NC下载地址:https://eternallybored.org/misc/netcat/ 解压到自己磁盘某地。然后在CMD中运行NC 最终效果如下: 代码如下: package com.cl;import org.apache.flink.api.common.functions.FlatMapFunction;import org.apache.flink.api.ja

基于Flink SQL的实时处理架构
本博文介绍基于Flink的多数据源->数据治理->Kafka->作业治理->DB的实时处理架构。数据治理,将读库降低为原来的2/3次,并使得多数据源转为统一Schema。基于统一的Schema数据流,作业治理将基于Jstorm的业务逻辑编码项目,简化成多条SQL语句的配置。 sar案例 可以先参阅 storm项目迁移flink案例:系统活动情况报告 而 Flink-sar-e
流式大数据实时处理技术、平台及应用
大数据技术的广泛应用使其成为引领众多行业技术进步、促进效益增长的关键支撑技术。根据数据处理的时效性,大数据处理系统可分为批式(batch)大数据和流式(streaming)大数据两类。其中,批式大数据又被称为历史大数据,流式大数据又被称为实时大数据。 目前主流的大数据处理技术体系主要包括Hadoop及其衍生系统。Hadoop技术体系实现并优化了MapReduce框架。Hadoop技术体系主要由谷

批处理系统、分时处理系统、实时处理系统简介
一、批处理阶段(操作系统开始出现) 为了解决人机矛盾及CPU和I/O设备之间速度不匹配的矛盾,出现了批处理系统。它按发展历程又分为单道批处理系统、多道批处理系统(多道程序设计技术出现以后)。 1) 单道批处理系统 系统对作业的处理是成批进行的,但内存中始终保持一道作业。该系统是在解决人机矛盾和CPU与I/O设备速率不匹配的矛盾中形成的。单道批处理系统的主要特征如下: 自动性。在顺利的情况下,在
Flink 实时处理 Socket 数据
在 2.3 中讲解了 Flink 最简单的 WordCount 程序的创建、运行结果查看和代码分析,这篇文章继续带大家来看一个入门上手的程序:Flink 处理 Socket 数据。 IDEA 创建项目 使用 IDEA 创建新的 module,结构如下: ├── pom.xml└── src├── main│ ├── java│ │ └── com│ │ └──
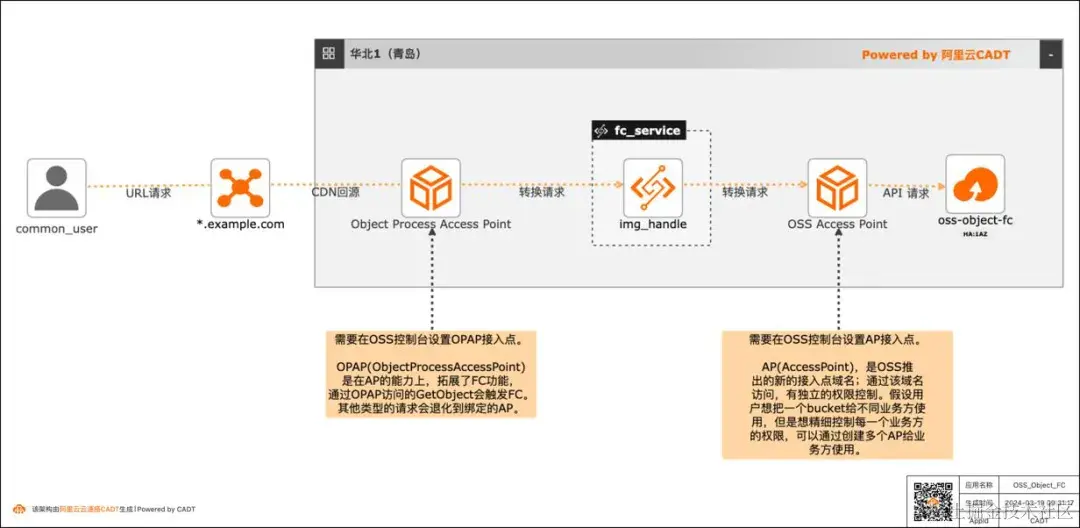
云原生最佳实践系列 7:基于 OSS Object FC 实现非结构化文件实时处理
方案概述 现在绝大多数客户都有很多非结构化的数据存在 OSS 中,以图片,视频,音频居多。举一个图片处理的场景,现在各种终端种类繁多,不同的终端对图片的格式、分辨率要求也不同,所以一张图片往往会有很多张衍生图,那如果所有的衍生图都存在 OSS 中,那存储的成本会增加,所以就可以通过 OSS Object FC 的方案,在不同的终端请求时,对 OSS 中的原图基于终端的要求做实时处理,然后响应返回
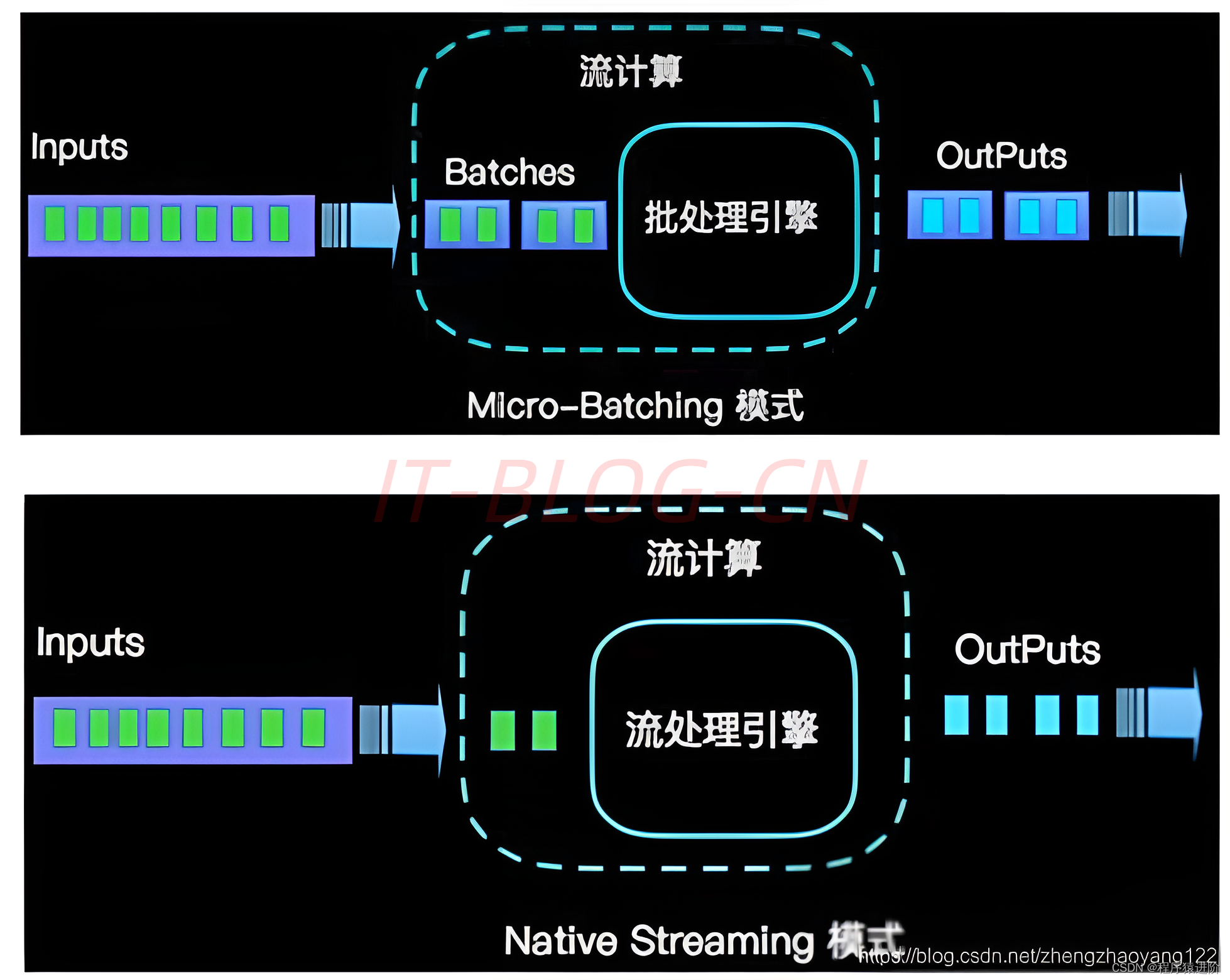
为什么选择 Flink 做实时处理
优质博文:IT-BLOG-CN 为什么选择 Flink 【1】流数据更真实地反映了我们的生活方式(实时聊天); 【2】传统的数据架构是基于有限数据集的(Spark 是基于微批次数据处理); 【3】我们的目标:低延迟、高吞吐(分布式架构,可能会出现顺序上的混乱,比如统计1个小时内,可能在1小时的时候,可能有的数据还在处理,会延迟到达几毫秒,这个可以通过设置来规避)、结果的准确性和良好的容错

SparkStreaming在实时处理的两个场景示例
简介 Spark Streaming是Apache Spark生态系统中的一个组件,用于实时流式数据处理。它提供了类似于Spark的API,使开发者可以使用相似的编程模型来处理实时数据流。 Spark Streaming的工作原理是将连续的数据流划分成小的批次,并将每个批次作为RDD(弹性分布式数据集)来处理。这样,开发者可以使用Spark的各种高级功能,如map、reduce、join等,来
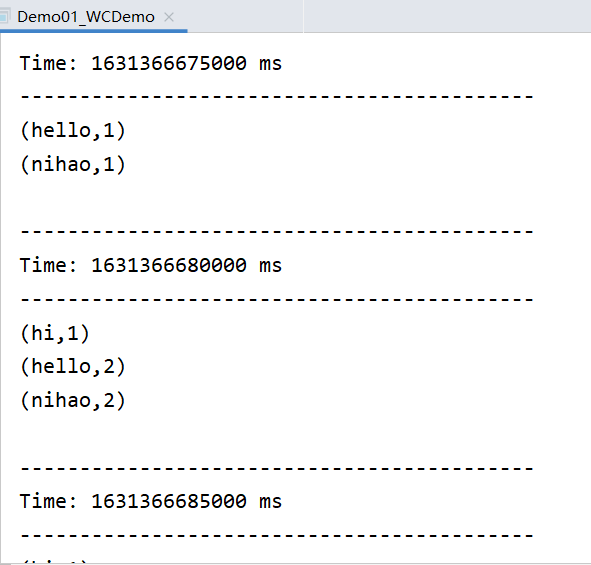
sparkstreamnig实时处理入门
1.2 SparkStreaming实时处理入门 1.2.1 工程创建 导入maven依赖 <dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>3.1.2</version></dependency><dependency><groupId
爬虫神器!用它可以实时处理和保存 Ajax 数据
公众号关注 “GitHubDaily” 设为 “星标”,每天带你逛 GitHub! 做爬虫的时候我们经常会遇到这么一个问题: 网站的数据是通过 Ajax 加载的,但是 Ajax 的接口又是加密的,不费点功夫破解不出来。这时候如果我们想绕过破解抓取数据的话,比如就得用 Selenium 了,Selenium 能完成一些模拟点击、翻页等操作,但又不好获取 Ajax 的数据了,通过渲染后的 HTM

android开发camera自动人脸,Android camera实时预览 实时处理,人脸识别示例
Android camera实时预览 实时处理,面部认证。 预览操作是网友共享的代码,我在继承SurfaceView 的CameraSurfaceView 中加入了帧监听事件,每次预览监听前五个数据帧,在处理做一个面部识别。 先看目录关系 自定义控件CameraSurfaceView.java 自定义接口方法CameraInterface.java CameraActivity预览界面。 Ca

Storm与Spark:谁才是我们的实时处理利器
实时商务智能目前已经逐步迈入主流,而Storm与Spark开源项目的支持无疑在其中起到了显著的推动作用。那么问题来了:实时处理到底哪家强? AD:51CTO 网+ 第十二期沙龙:大话数据之美_如何用数据驱动用户体验 实时商务智能这一构想早已算不得什么新生事物(早在2006年维基百科中就出现了关于这一概念的页面)。然而尽管人们多年来一直在对此类方案进行探讨,我却发现很

大数据实时处理-基于Spark的大数据实时处理及应用技术
培训要点 互联网点击数据、传感数据、日志文件、具有丰富地理空间信息的移动数据和涉及网络的各类评论,成为了海量信息的多种形式。当数据以成百上千TB不断增长的时候,我们在内部交易系统的历史信息之外,需要一种基于大数据实时分析的决策模型和技术支持。 大数据通常具有:数据体量(Volume)巨大,数据类型(Variety)繁多,价值(Value)密度低,处理速度(Velocity)快等四大特征。Goo
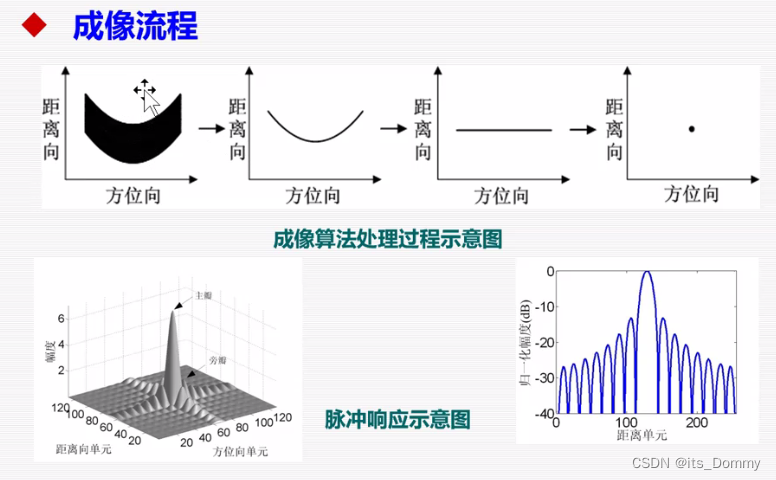
雷达成像与实时处理 第一课笔记
注重完整性、构建知识框架>细学知识 2022秋季课程的课堂笔记 2022/9/9 雷达成像原理与实时处理 第一课 1 雷达介绍: 连续波雷达一般是双天线,脉冲雷达一般是单天线加双工器。 2 合成孔径雷达(SAR)介绍 距离分辨率:C/2B,二维高分辨,点->图像 *SAR灰度图像与光学图像的对比:SAR成像全天时全天候,更强的地表表征区分能力。互补 *SA

c++视觉处理----固定阈值操作:Threshold()函数,实时处理:二值化,反二值化,截断,设为零,反向设为零
固定阈值操作: Threshold()函数 cv::threshold() 函数是OpenCV中用于执行固定阈值二值化操作的函数。它可以用来将图像中的像素值根据用户定义的阈值转换为二进制值(0或255),以便进行图像分割、物体检测和特征提取等任务。 cv::threshold() 函数的基本语法如下: double cv::threshold(cv::InputArray src,