声学专题

流动会场:覆盖广泛、声学出色的创新选择—轻空间
在现代社会,活动的多样性和灵活性要求场馆具备更高的适应性。流动会场作为一种创新的场馆形式,以其覆盖人群广泛、快速搭建、成本低廉、优异的声学效果等优势,迅速成为各类活动的首选。无论是商业活动、体育赛事、音乐演出,还是社区集会,流动会场都能在满足不同需求的同时,提供传统场馆难以实现的灵活性、经济性和卓越的音效体验。 覆盖人群广泛,打破空间限制 流动会场最大的优势在于其覆盖人群的广泛性。传

中国科学院声学研究所博士招生目录
中国科学院声学研究所(以下简称声学所)成立于1964年,是从事声学和信息处理技术研究的综合性研究所,总部位于北京市海淀区中关村。目前,声学所在北京设有声场声信息国家重点实验室、国家网络新媒体工程技术研究中心等9个研究单元;在海南建有南海研究站、在上海建有东海研究站、在青岛建有北海研究站。声学所定位是:主要致力于声学和信息处理技术学科的应用基础和高技术发展研究,围绕未来5到10年我国在海洋、安全、能

打造灵动空间,流动会场的声学优势—轻空间
在现代社会中,各类会议、展览、演出、培训等活动越来越多,对场地的需求也越来越多样化。传统的固定场地往往难以满足不同活动的需求,而“流动会场”凭借其灵活多变的特点,迅速成为各类活动的新宠。特别是其独特的声学优势,更是为各种类型的活动提供了不可替代的优质体验。 一、快速搭建,灵活应对多样化需求 流动会场最大的特点是其高效的搭建方式。与传统建筑相比,流动会场无需繁琐的建筑施工和长期的规划审
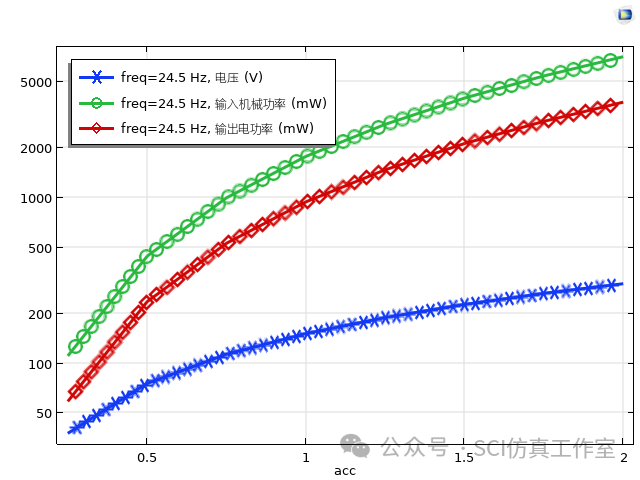
Comsol 声学黑洞梁式结构的振动能量收集器
声学黑洞梁式结构是一种用于收集振动能量的装置,其工作原理类似于光学中的黑洞概念。它可以将周围环境中的声波能量转化为可用的电能。声学黑洞梁式结构通常由以下几个主要组成部分构成: 1. 梁:梁是主要的振动结构,可以是金属、陶瓷或者其他适合传导声波的材料。它的设计通常考虑到频率响应和材料的机械特性,以优化能量收集效率。 2. 能量转换器:能量转换器位于振动膜的背面,用于将振动能量转化为电能。

AI在医学领域:谷歌的HeAR生物声学模型
声学非语义属性的语音可以使机器学习模型执行诸如情绪识别、说话者识别和痴呆检测等副语言任务。脑卒中、帕金森病、阿尔茨海默病、脑瘫和肌萎缩侧索硬化症(ALS)等脑血管和神经退行性疾病也可以使用非语义语音模式,如发音、共鸣和发声等来检测和监测。与健康相关的非语义声学信号不仅限于对话语音数据。来自呼吸系统气流的健康相关声学线索,包括咳嗽声和呼吸模式等声音,可以用于健康监测。例如,临床医生使用

ASR-声学特征提取
文章目录 方法一:MFCC特征提取step 1:A/D转换(采样)step 2:预加重step 3:加窗分帧step 4:DFT+取平方step 5:Mel滤波step 6:取对数step 7:IDFTstep 8:动态特征 方法二:深度学习特征提取step 1:采样step 2:分帧step 3:傅里叶变换step 4:识别字符step 5:获取映射图 方法一:MFCC特征提

ECM和MEMS技术在心肺声学监测中的应用
心肺疾病是全球范围内导致死亡的主要原因。因此,对这些疾病迹象的准确和快速评估对于为患者提供适当的医疗保健至关重要。心血管疾病最重要的迹象之一是心脏周期的异常。大多数呼吸系统疾病则表现为呼吸周期的异常。有多种方法可以监测心脏和肺部的周期。听诊是监测患者健康状况的最重要的诊断方法之一。 人体器官产生的声学信号通过组织传播并到达体表。这些声学信号极其微弱,但包含了大量的与健康相关

解决气膜场馆内噪声问题的多功能声学综合馆—轻空间
随着气膜结构在各个领域的广泛应用,人们开始意识到在这些场馆内部,特别是在大型活动和展览中,噪声问题可能会变得相当严重。传统的气膜结构通常难以提供良好的声学环境,这对于参与者的舒适度和活动的质量构成了挑战。为了解决气膜场馆内噪声问题,多功能声学综合馆成为了一个创新和可行的选择。 多功能声学综合馆的声学技术 多功能声学综合馆的声学技术为传统气膜馆的噪音问题提供了创新性的解决方案。轻空间依

【神奇的声学多普勒流速剖面仪(ADCP )】
神奇的声学多普勒流速剖面仪(ADCP ) 1842年,奥地利物理学家克里斯琴·多普勒(Christian Doppler)发现由于波源和观察者之间的相对运动使观测频率与波源频率不同的现象,后来被称为“多普勒效应”。 1982年,美国发明家福然·罗欧(Fran Rowe)和堪特·丹尼斯(Kent Deines)发明了声学多普勒流速剖面仪(Acoustic Doppler Current Profi
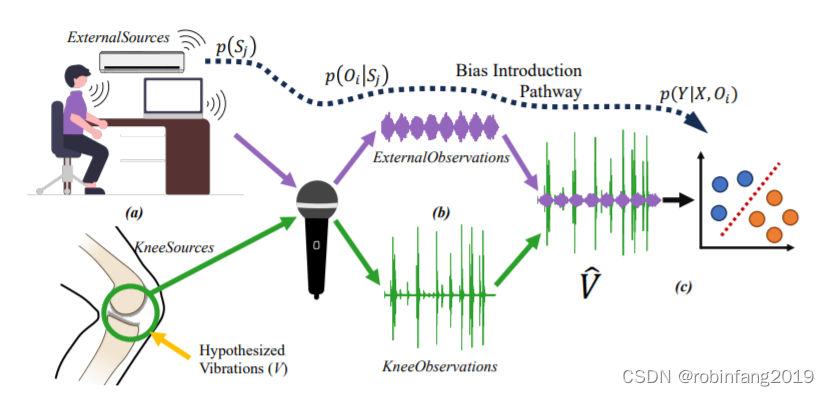
声学特征在膝关节健康诊断中的应用分析
关键词:膝关节声发射、膝关节生物标志物、因果关系、机器学习 声学膝关节健康评估长期以来一直被看作是一种替代临床可用医学成像工具的替代方法,如声发射技术是通过检测膝关节在运动过程中产生的微小裂纹或损伤引起的声波信号,从而评估关节的健康状况。这种技术可以实时监测膝关节在不同活动状态下的声发射信号,帮助医生更准确地诊断和评估膝关节的损伤程度,但这种方法尚未在医疗实践中未得到广泛采用。目
【经典文献】水下光学和声学成像:融合的时代?最新技术概述
文献名称:《Underwater Optical and Acoustic Imaging: A Time for Fusion? A Brief Overview of the State-of-the-Art》作者列表:Fausto Ferreira, Diogo Machado, Gabriele Ferri, Samantha Dugelay and John Potter作者单位:北约科
对语言模型的通用声学攻击
对语言模型的通用声学攻击主要涉及到通过生成对抗性扰动来干扰或欺骗语音识别系统。这种攻击可以通过多种方式实现,包括但不限于基于深度学习的方法和特定的攻击策略。 通用音频对抗性扰动生成器(UAPG)是一种有效的工具,它能够在任意良性音频输入上强加对抗性扰动,从而导致错误分类。这种方法的优势在于其高效性,实验表明它比最先进的音频对抗攻击方法实现了高达167倍的加速。 此外,

HBK声学与振动 | 助听器测试
高质量的助听器能让有听力障碍的用户轻松自如地进行交流。我们的头和躯干模拟器、耳模拟器和人工乳突为优化音频质量和清晰度提供了全面的测试解决方案。 来源丨BK声学与振动

GLFore声学成像仪
声波成像研究始于20世纪20年代末,最早的方法是液体表面变形方法。随后,各种声学成像方法相继出现。到了20世纪70年代,已经形成了一些成熟的方法和大量的商业产品。声成像方法可分为主动声成像、扫描声学成像和声全息。由于许多声学探测器能够记录声波的振幅和相位并将其转换成相应的电信号,因此可以记录由换能器阵列的每个单元接收的信号的振幅和相位,以再现对象的图像。 SIG
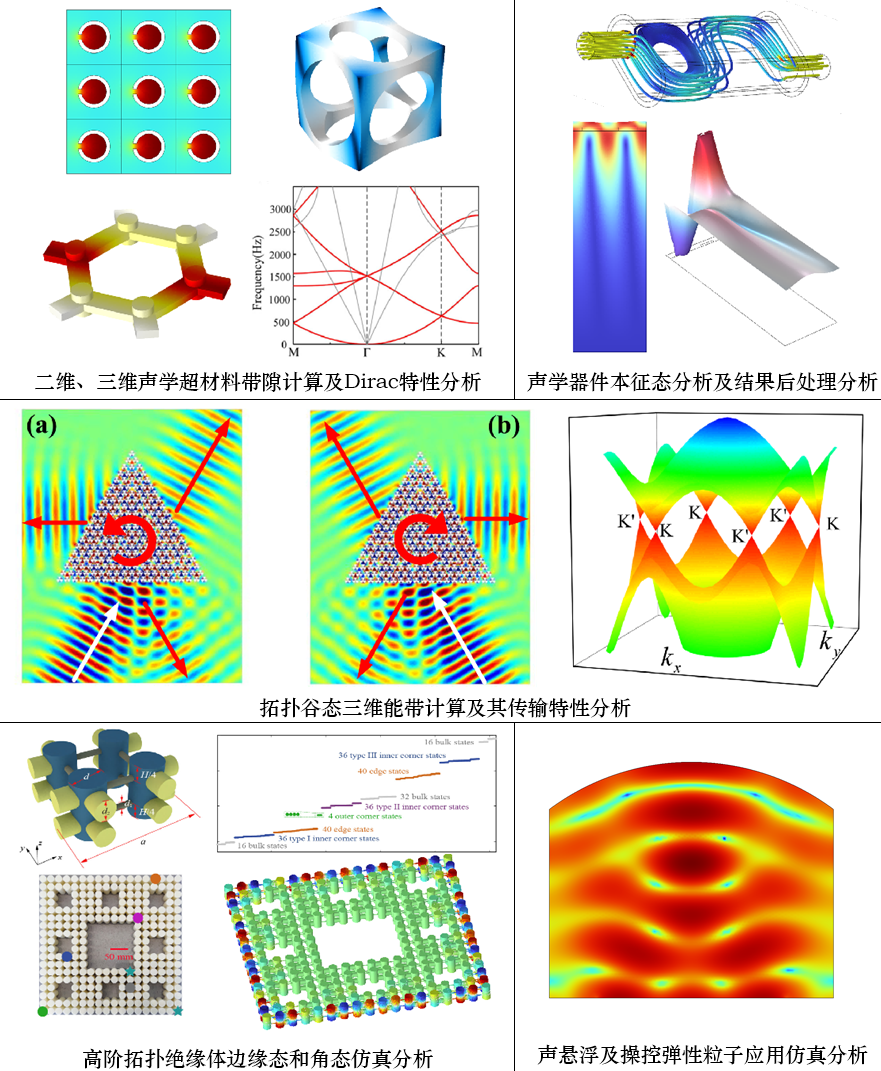
COMSOL声学(线下)-光电(线上),几十种案例仿真
仿真专题培训会 光电专题 2023年9月16日-9月17日 2023年9月23日-9月24日 在线直播(授课四天) 声学专题 2023年10月12日-10月15日 线下北京 (第一天报道,授课三天) 主讲导师 光电讲师: 来自国家“双一流”建设高校 、“211工程”“985工程”重点高校。授课讲师有着丰富的COMSOL使用经验,以第一/通讯作者在《Nature C

comsol声学专题
COMSOL多物理场仿真软件以高效的计算性能和杰出的多场耦合分析能力实现了精确的数值仿真,已被广泛应用于各个领域的科学研究以及工程计算,为工程界和科学界解决了复杂的多物理场建模问题。COMSOL内嵌的声学模块可以方便地进行多孔声学和粘热声学的模拟仿真。软件数值计算得到的云图,可以将声压、速度、声强以及声能耗散等结果可视化,十分有利于学生对声学的学习和理解。将COMSOL仿真引入实验当中,通过软件的

【AI视野·今日Sound 声学论文速览 第四十四期】Tue, 9 Jan 2024
AI视野·今日CS.Sound 声学论文速览 Tue, 9 Jan 2024 Totally 27 papers 👉上期速览✈更多精彩请移步主页 Daily Sound Papers DJCM: A Deep Joint Cascade Model for Singing Voice Separation and Vocal Pitch Estimation Authors Hao

【AI视野·今日Sound 声学论文速览 第四十一期】Thu, 4 Jan 2024
AI视野·今日CS.Sound 声学论文速览 Thu, 4 Jan 2024 Totally 8 papers 👉上期速览✈更多精彩请移步主页 Daily Sound Papers Multichannel blind speech source separation with a disjoint constraint source model Authors Jianyu Wa

【AI视野·今日Sound 声学论文速览 第四十二期】Fri, 5 Jan 2024
AI视野·今日CS.Sound 声学论文速览 Fri, 5 Jan 2024 Totally 10 papers 👉上期速览✈更多精彩请移步主页 Daily Sound Papers PosCUDA: Position based Convolution for Unlearnable Audio Datasets Authors Vignesh Gokul, Shlomo Dub

【AI视野·今日Sound 声学论文速览 第四十期】Wed, 3 Jan 2024
AI视野·今日CS.Sound 声学论文速览 Wed, 3 Jan 2024 Totally 4 papers 👉上期速览✈更多精彩请移步主页 Daily Sound Papers Auffusion: Leveraging the Power of Diffusion and Large Language Models for Text-to-Audio Generation A

【AI视野·今日Sound 声学论文速览 第三十九期】Tue, 2 Jan 2024
AI视野·今日CS.Sound 声学论文速览 Tue, 2 Jan 2024 Totally 7 papers 👉上期速览✈更多精彩请移步主页 Daily Sound Papers Enhancing Pre-trained ASR System Fine-tuning for Dysarthric Speech Recognition using Adversarial Data

Kaldi声学模型训练
我的书: 淘宝购买链接 当当购买链接 京东购买链接 支持标准的基于ML训练的模型 线性变换,如LDA,HLDA,MLLT/STC基于fMLLR,MLLR的说话人自适应支持混合系统 支持SGMMs 基于fMLLR的说话人识别 模型代码,可以容易的修改扩展 ##声学模型训练过程 ###1.获得语料集的音频集和对应的文字集 可以提供更精确的对齐,发音(句子ÿ

大牛讲堂|语音专题第三讲,声学模型
雷锋网(公众号:雷锋网)按:本文作者牛建伟,地平线语音算法工程师。硕士毕业于西北工业大学,曾任百度语音技术部资深工程师。主要工作方向是语音识别中声学模型的算法开发和优化,负责深度学习技术在声学模型上的应用和产品优化。参与了百度最早的深度学习系统研发,负责优化语音搜索、语音输入法等产品;后负责百度嵌入式语音开发,其负责的离线语音识别性能超越竞品。现任地平线机器人语音识别算法工程师,深度参与地平线“

【AI视野·今日Sound 声学论文速览 第二十五期】Fri, 13 Oct 2023
AI视野·今日CS.Sound 声学论文速览 Fri, 13 Oct 2023 Totally 8 papers 👉上期速览✈更多精彩请移步主页 Daily Sound Papers Impact of time and note duration tokenizations on deep learning symbolic music modeling Authors Nath
