吞吐量专题

系统吞吐量几个重要参数:QPS(TPS)、并发数、响应时间
一.系统吞度量要素: 一个系统的吞度量(承压能力)与request对CPU的消耗、外部接口、IO等等紧密关联。单个reqeust 对CPU消耗越高,外部系统接口、IO影响速度越慢,系统吞吐能力越低,反之越高。 系统吞吐量几个重要参数:QPS(TPS)、并发数、响应时间 QPS(TPS):每秒钟request/事务 数量 并发数: 系统同时处理的request/事务数 响应时间: 一般
QPS(每秒查询率、最大吞吐能力),TPS,吞吐量,响应时间
因特网上,经常用每秒查询率来衡量域名系统服务器的机器的性能,其即为QPS。 对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。 计算关系: QPS = 并发量 / 平均响应时间并发量 = QPS * 平均响应时间 通常QPS用来表达和衡量当前系统的负载,也可以用RPS来表示, 我们形容当前系统的运行状态时可以说当前QPS已经达到多少多少了, 在系统环境不变的情况下存在支持的

LinkedBlockingQueue比BlockingQueue吞吐量高的原因?
目录 1.首先吞吐量是什么?如何衡量程序的吞吐量?2. LinkedBlockingQueue 吞吐量高的原因? 1.首先吞吐量是什么?如何衡量程序的吞吐量? 吞吐量是指在一定时间内系统或程序处理的任务数量或数据量。在计算机领域,吞吐量通常用来衡量系统、程序或设备在单位时间内处理的工作量或数据量,是评估系统性能的重要性能之一。可以从吞吐量通常可以通过以下方式进行衡量: 任务完成数

机器之心 | 五倍吞吐量,性能全面包围Transformer:新架构Mamba引爆AI圈
本文来源公众号“机器之心”,仅用于学术分享,侵权删,干货满满。 原文链接:五倍吞吐量,性能全面包围Transformer:新架构Mamba引爆AI圈 屹立不倒的 Transformer 迎来了一个强劲竞争者。 在别的领域,如果你想形容一个东西非常重要,你可能将其形容为「撑起了某领域的半壁江山」。但在 AI 大模型领域,Transformer 架构不能这么形容,因为它几乎撑起了「整个江山

java应用响应时间长、吞吐量小、CPU利用率特别高问题定位笔记(一)
环境:一个java应用+tomcat 问题描述:响应时间长、吞吐量小、CPU利用率特别高 如下图所示: 定位分析思路 1)看看占用cpu高的进程中有哪些线程 使用top -Hp pid命令查看 2)使用jstack pid > xxx.txt 将java应用的堆栈信息dump下来 3)更具线程PID查看当前线程在干什么(如下图) 4)根据信息查看代码找到最终问题
网络相关基础知识总结(一)吞吐量测试吞吐量与带宽区别
一.概念 网络中的数据是由一个个数据包组成,防火墙对每个数据包的处理要耗费资源。吞吐量是指在没有帧丢失的情况下,设备能够接受的最大速率。 1.作用地位 网络吞吐量测试是网络维护和故障查找中最重要的手段之一,尤其是在分析与网络性能相关的问题时吞吐量的测试是必备的测试手段。 作为验证和测试网络带宽最常用的技术就是吞吐量测试。 二.测试方法与思想 吞吐量的测试需要由被测试链路的双端进行端
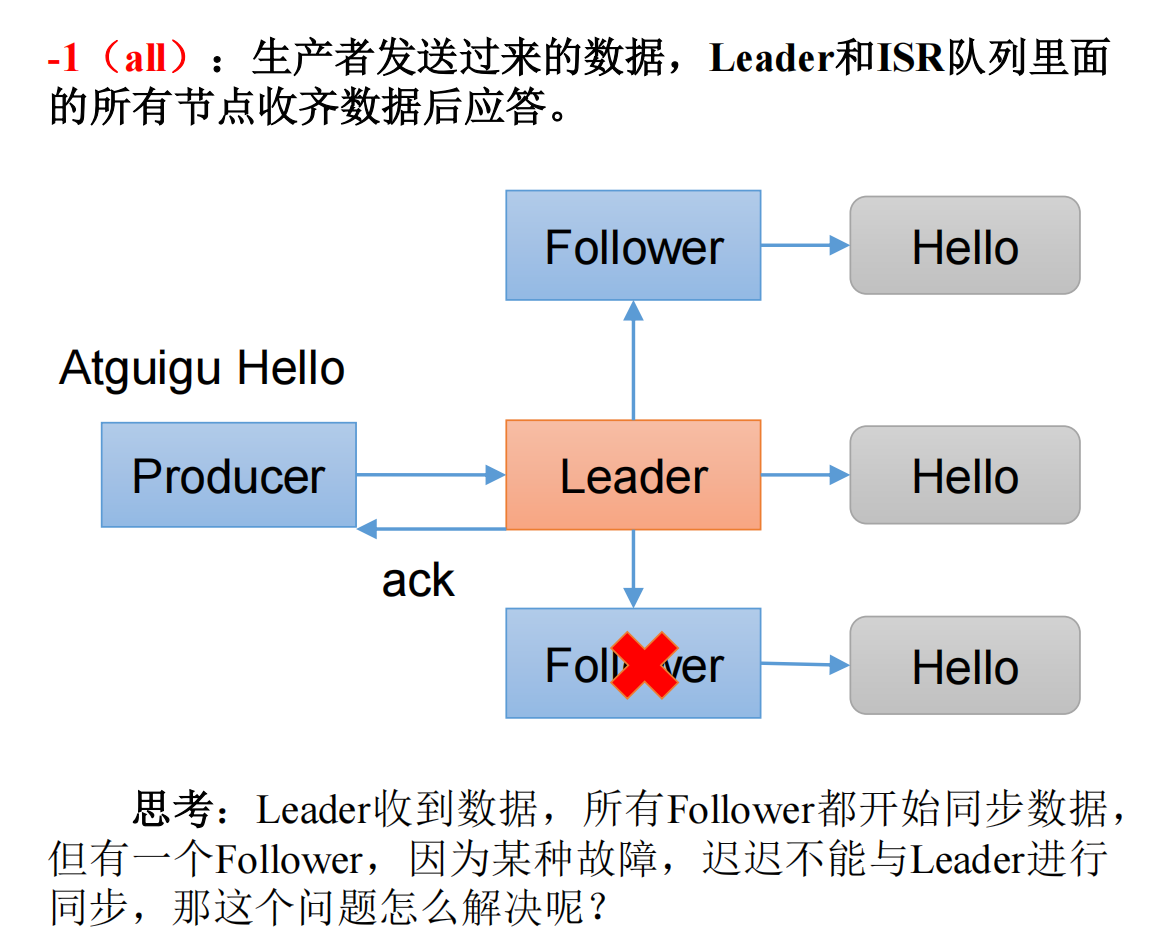
【Kafka】Kafka提高生产者吞吐量、数据可靠性-06
【Kafka】Kafka提高生产者吞吐量-06 1. 提高生产者吞吐量2.数据可靠性2.1 回顾数据的发送流程2.2 ack应答级别2.2.1 acks:02.2.2 acks:12.2.2 acks:-1(all)2.2.2.1 数据可靠性分析2.2.2.2 数据完全可靠 2.3 可靠性总结2.4 可靠性代码配置 1. 提高生产者吞吐量 import org.apach

伯克利开源Confluo:吞吐量比Kafka高4到10倍!
原文链接 使用文档链接 源码链接 confluo是用于多个数据流实时分布式分析的系统,Confluo 通过为多数据流的一些专门应用场景而精心设计的数据结构和针对端到端而优化的系统设计实现了高吞吐量并发写入、毫秒级在线查询和高效的即时查询。 我们很高兴将 Confluo 作为一个开源 C++ 项目,其中包括: Confluo 的数据结构库,支持高吞吐量日志摄入,以及各种在线(实时聚合、条件触

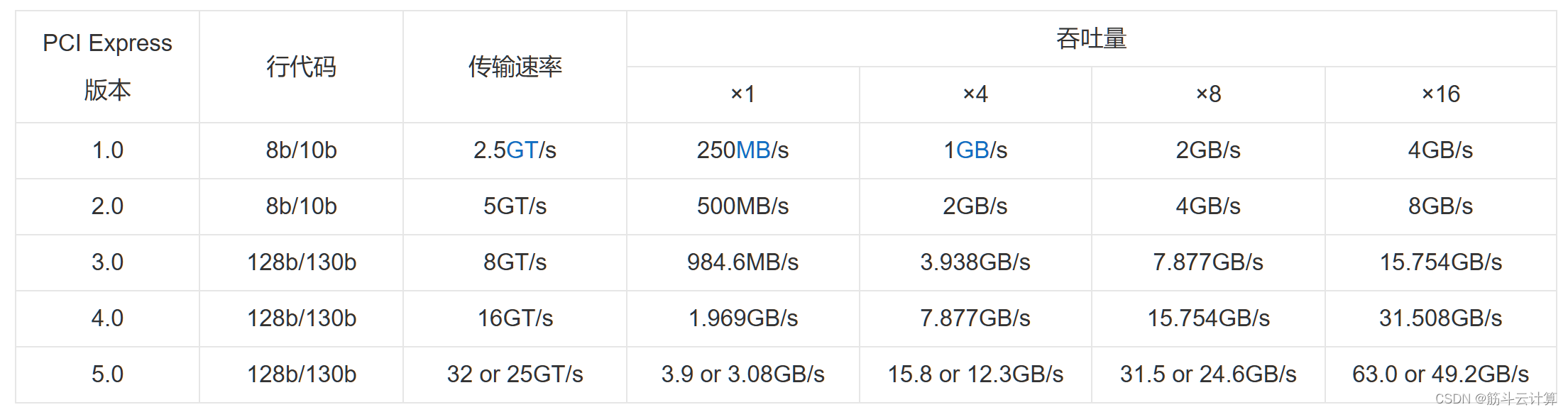
PCIE的吞吐量如何计算和记忆诀窍?
简介: PCIe标准中的性能参数有好几个,比如设备的带宽和吞吐量是多少?传输速率? 百度百科上,PCIE标准的传输速率与带宽对应表如下(表中速率为单向速率)。网上有些数据是双向的,性能数据就翻倍了。 记忆PCIE吞吐量有诀窍 PCIE总线版本为n, 那么 PCIE x8的吞吐量=2的n次方 。 PCIE 3.0 带宽为2^3=8 GB/s ,和表格中7.877大差不差。 其他在x8的
使用Keepalived提高吞吐量和负载均衡ip_hash.
一 . Nginx使用Keepalived提高吞吐量案例 Keepalived[表示把连接保持一定长连接数来提高吞吐量] 1.1没有使用keepalived参数 upstream tomcats {server 192.168.28.102:8080;}server {listen 88;server_name www.tomcats.com;location / {

工具使用-网络性能测试工具(iperf)-TCP 和 UDP 的吞吐量-包转发率参数的理解
时间戳:2024年5月26日15:18:39 iperf 和 netperf 都是最常用的网络性能测试工具,测试 TCP 和 UDP 的吞吐量。它们都以客户端和服务器通信的方式,测试一段时间内的平均吞吐量。 接下来,我们就以 iperf 为例,看一下 TCP 性能的测试方法。目前,iperf 的最新版本为iperf3,你可以运行下面的命令来安装: iperf工具安装 # Ubuntuap
吞吐量 和 延时的关系
关于吞吐量/吞吐率、延时,你可以通过 Jmeter中的”聚合报告“和”用表格查看报告“来获取。 Throughput 越大,Latency 越差:因为请求过多,系统繁忙导致响应速度降低。Latency 的值越小说明能支持的 Throughput 越高:Latency 数值小说明系统处理速度快,自然便可以处理更多的请求。Throughput "不用" 通过降低 latency 的方式来提高,排查性

分布式事务:不过是在一致性、吞吐量和复杂度之间,做一个选择 分布式系统 消息系统
分布式事务:不过是在一致性、吞吐量和复杂度之间,做一个选择 您的评价: 0.0 收藏 1收藏 这是一个开撕的话题,我经历过太多的关于分布式事务的需求:“有没有简单的方案,像使用数据库事务那样,解决分布式数据一致性的问题”。特别是微服务架构流行的今天,一次交易需要跨越多个“服务”、多个数据库来实现,传统的技术手段,已经无
【计算机网络】-性能指标(速率、带宽和吞吐量)
速率、带宽和吞吐量 信道(channel): 表示向某个方向传输信息的通道,一条通信线路在逻辑上往往对应着一条发送信道和接收线道 速率(speed): 指的是连接到网络上的节点在信道上传输的速率。也称为数据率或比特率、数据传输速率 单位:bit/s,b/s,或者bps(bit per second) 时延、时延带宽、往返时延 注意:有时B/s,(1B=8b)B=byte字节,b=bi
SpringBoot异步接口实现:提高系统的吞吐量
前言 Servlet 3.0之前:每一次Http请求都由一个线程从头到尾处理。 Servlet 3.0之后,提供了异步处理请求:可以先释放容器分配给请求的线程与相关资源,减轻系统负担,从而增加服务的吞吐量。 在springboot应用中,可以有4种方式实现异步接口(至于ResponseBodyEmitter、SseEmitter、StreamingResponseBody,不在本文介绍内,之
ttcp测试网络吞吐量
计算机网络中的几个性能指标 带宽:用来表示网络的通信线路传送数据的能力,通常是指单位时间内从网络中的某一点通过另一点的最高数据率,即网络设备所支持的最高速度 吞吐量:表示单位时间内通过某个网络(或信道、接口)的数据量。 代码位置及分析 ttcp代码位置:muduo-master/examples/ace/ttcp ttcp_blocking.cc就是简单的客户端服务端通信(阻塞IO),通信
吞吐量与响应时间的关系
计算机系统的总体性能标准是吞吐量和响应时间。 吞吐量是对单位时间内完成的工作量的量度。示例包括: 每分钟的数据库事务 每秒传送的文件千字节数 每秒读或写的文件千字节数 每分钟的 Web 服务器命中数 响应时间是提交请求和返回该请求的响应之间使用的时间。示例包括: 数据库查询花费的时间 将字符回显到终端
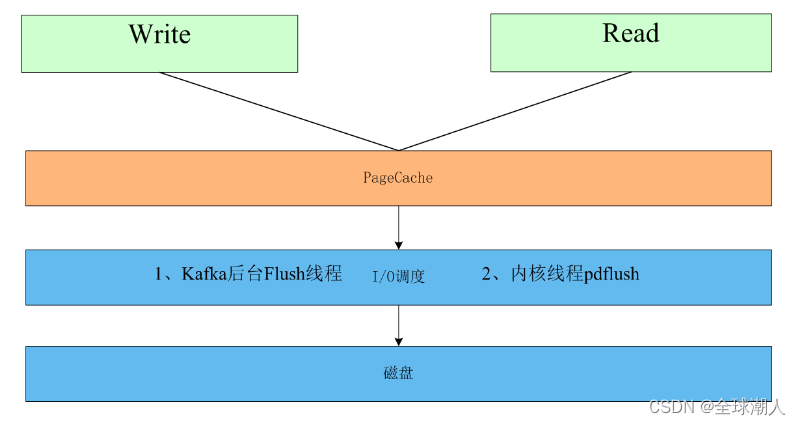
面试题:Kafka的吞吐量和性能为什么那么好?以及Topic或者分区多了之后,会有什么问题?
题目来源 阿里-技术-1面 题目描述 Kafka的单个Broker上的Topic或者分区多了之后,会有什么问题? 我的回答 没了解过 更好的答案 一般来说,我们需要基于单个Broker来评判这个问题,因为在集群中,10个分区分布在10个Broker上,是不会有性能问题的。下面就针对单个Broker来讨论下Topic或者Broker多了,会有什么问题。 结论 Kafka Broke

Open vSwitch 吞吐量测试报告
实验环境: 首先介绍一下实验环境 系统:CentOS7 CPU:Intel(R) Xeon(R) CPU E5-2630 @ 2.30GHz Memory:DDR4 1600MHZ 16GB OVS版本:2.5.0 拓扑描述: 再两台物理服务器上搭建OpenStack计算节点,两台物理服务器之间通过INTEL 100G网卡进行连接,保证物理带宽够用。计算节点上分别启动5台虚拟机,计算
软件交付效能度量——从吞吐量和稳定性开始
除了感性的工作体验外,我们还需要指标来度量改进措施是否对提升软件交付效能有帮助。过多的指标会对团队造成不必要的管理成本,也容易让团队失去关注焦点。从吞吐量和稳定性两个维度考量的四个关键指标是简单但有效的指标,建议优先度量。 为了提升软件交付效能,你的团队或组织可能已经开始采取行动,引入敏捷方法、DevOps实践甚至还有架构重构。但你如何知道这些改进措施起了作用呢,或者它们压根就水土不服

深入浅出 -- 系统架构之日均亿级吞吐量的网关架构(DNS轮询解析)
在前篇关于《Nginx》的文章中曾经提到:单节点的Nginx在经过调优后,可承载5W左右的并发量,同时为确保Nginx的高可用,在文中也结合了Keepalived对其实现了程序宕机重启、主机下线从机顶替等功能。 但就算实现了高可用的Nginx依旧存在一个致命问题:如果项目的QPS超出5W,那么很有可能会导致Nginx被流量打到宕机,然后根据配置的高可用规则,Keepalived会对Nginx重
深入浅出 -- 系统架构之日均亿级吞吐量的网关架构(CDN内容分发)
亿级吞吐第二战-CDN内容分发 CDN(Content Delivery Network)内容分发网络是一种构建在现有网络基础上的智能虚拟网络,依靠部署在全球各地的节点,通过负载均衡、内容分发、机器调度等功能,使用户的请求能够被分发到离自身最近的节点处理,就近获取所需的资源,最终达到提升用户访问速度以及降低服务器访问压力等目的。 CDN出现的本质是为了解决不同地区用户访问速度不一致

【分析 GClog 的吞吐量和停顿时间、heapdump 内存泄漏分析】
文章目录 🔊博主介绍🥤本文内容GClog分析以优化吞吐量和停顿时间步骤1: 收集GClog步骤2: 分析GClog步骤3: 优化建议步骤4: 实施优化 Heapdump内存泄漏分析步骤1: 获取Heapdump步骤2: 分析Heapdump步骤3: 定位泄漏对象步骤4: 分析泄漏原因步骤5: 修复泄漏 📢文章总结📥博主目标 🔊博主介绍 🌟我是廖志伟,一名Java开

五倍吞吐量,性能全面包围 Transformer:新架构 Mamba 引爆AI圈
屹立不倒的 Transformer 迎来了一个强劲竞争者。 在别的领域,如果你想形容一个东西非常重要,你可能将其形容为「撑起了某领域的半壁江山」。但在 AI 大模型领域,Transformer 架构不能这么形容,因为它几乎撑起了「整个江山」。 自 2017 年被提出以来,Transformer 已经成为 AI 大模型的主流架构,但随着模型规模的扩展和需要处理的序列不断变长,Transfo