本文主要是介绍PCIE的吞吐量如何计算和记忆诀窍?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介: PCIe标准中的性能参数有好几个,比如设备的带宽和吞吐量是多少?传输速率?
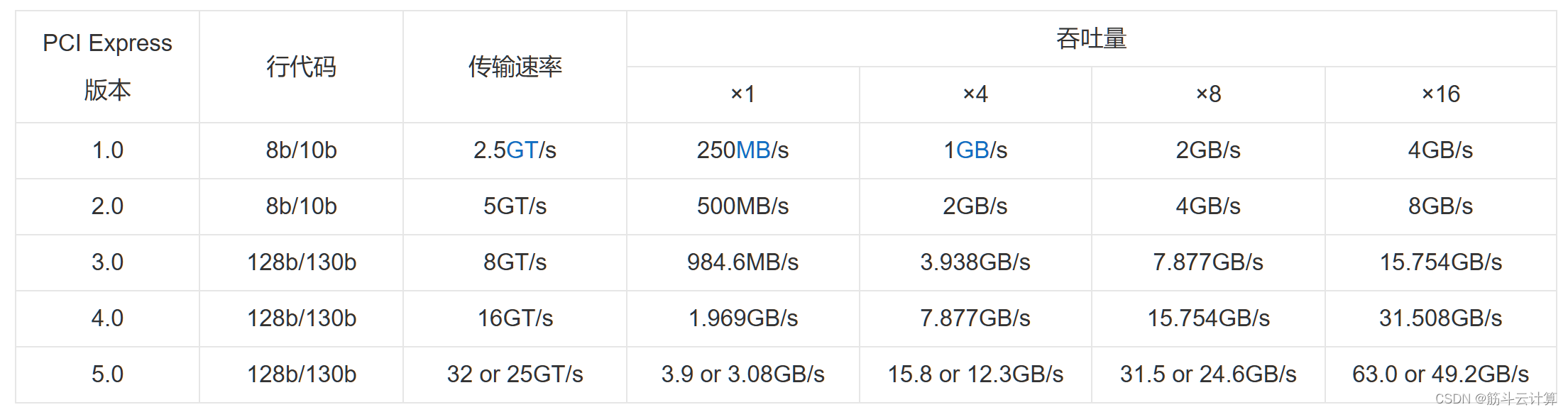
百度百科上,PCIE标准的传输速率与带宽对应表如下(表中速率为单向速率)。网上有些数据是双向的,性能数据就翻倍了。
记忆PCIE吞吐量有诀窍
PCIE总线版本为n, 那么 PCIE x8的吞吐量=2的n次方 。 PCIE 3.0 带宽为2^3=8 GB/s ,和表格中7.877大差不差。
其他在x8的吞吐量倍数上折算即可。
详细说明
- Width(带宽):通常用x1、x2、x4、x8等表示,表示该链路由几条lane组成。
- Speed(速率):通常用2.5GT/s、5GT/s、8GT/s,表示每条lane上的传输速率。PCIe1.0为2.5GT/s,PCIe2.0为5GT/s,PCIe3.0为8GT/s,
- GT/s :Giga transation per second (千兆传输/秒),即每一秒内传输的次数。重点在于描述物理层通信协议的速率属性,可以不和链路宽度等关联。
- Gbps :Giga Bits Per Second (千兆位/秒)。GT/s 与Gbps 之间其实不是相等的,但可以认为近似相等。近似的原因是编码算法造成的,有极少的码元bit用于存放纠错码了。
PCIe 链路吞吐量计算方法:
- 吞吐量 = 速率 * 带宽 * 2方向(全双工) * 编码方式
1)PCI-e2.0 协议支持 5.0 GT/s,即每一条Lane 上支持每秒钟内传输 5G个bit;但这并不意味着 PCIe 2.0协议的每一条Lane支持 5Gbps 的速率。因为PCIe 2.0 的物理层协议中使用的是 8b/10b 的编码方式。 即每传输8个bit,需要发送10个bit;这多出的2个bit是纠错码,并不是对上层有实际意义的。
- 以PCIe 2.0 x8的通道为例,吞吐量=5GT * 8 * 8/10 = 32 Gbps = 4GB/s。
2)PCI-e3.0 协议支持 8.0 GT/s, 即每一条Lane 上支持每秒钟内传输 8G个bit。而PCIe 3.0 的物理层协议中使用的是 128b/130b 的编码方案。 即每传输128个bit,需要发送130个bit。
- 以PCIe 3.0 x4的通道为例,该链路的吞吐量= 8GT * 4 * 128/130 = 31.508 Gbps = 3.938GB/s
- 以PCIe 3.0 x8的通道为例,该链路的吞吐量= 8GT * 8 * 128/130 = 63.015Gbps = 7.877 GB/s
这篇关于PCIE的吞吐量如何计算和记忆诀窍?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







